
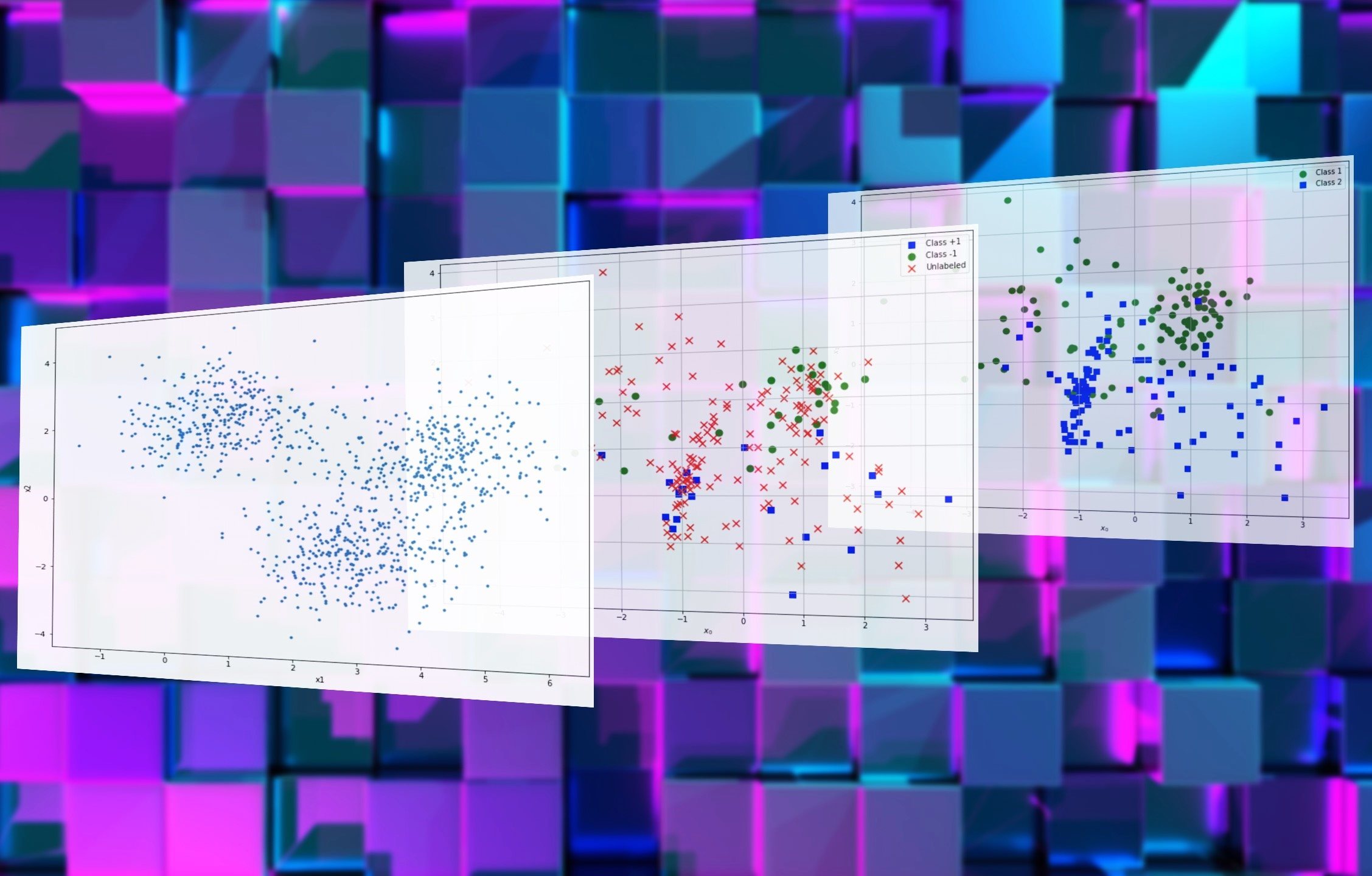
What is Semi-supervised Machine Learning
Semi-supervised machine learning is a powerful approach that combines aspects of both supervised and unsupervised learning. In traditional supervised machine learning, a model is trained using a dataset where each data point is labeled with the corresponding output. This allows the model to learn patterns and make predictions based on those labeled examples. On the other hand, unsupervised learning involves training a model on unlabeled data, where the goal is to discover inherent patterns or structures within the dataset.
Semi-supervised learning comes into play when we have a limited amount of labeled data available, but a large amount of unlabeled data. It bridges the gap between supervised and unsupervised learning by taking advantage of both types of data. The basic idea behind semi-supervised learning is to use the labeled data to guide the learning process and provide additional information for the model, while leveraging the unlabeled data to uncover hidden patterns and improve generalization.
By using semi-supervised learning, we can benefit from the strengths of both supervised and unsupervised learning. The labeled data helps the model learn specific patterns and make accurate predictions for the labeled examples. On the other hand, the unlabeled data allows the model to learn more general patterns and capture the underlying structure of the data.
Semi-supervised learning is especially useful in situations where labeling data is time-consuming, expensive, or impractical. In many real-world scenarios, obtaining labeled data can be a challenging and costly process. By utilizing both labeled and unlabeled data, semi-supervised learning provides a cost-effective solution for training models with higher accuracy and better performance.
Overall, semi-supervised machine learning is a valuable technique that combines the best of both supervised and unsupervised learning approaches. It provides a flexible and efficient way to leverage unlabeled data and improve the accuracy of predictions. By harnessing the power of semi-supervised learning, businesses and researchers can extract valuable insights from their data and make informed decisions.
The Difference between Supervised and Unsupervised Machine Learning
Supervised and unsupervised machine learning are two primary approaches in the field of artificial intelligence and data analysis. Understanding the key differences between these two methods is crucial for effectively applying machine learning algorithms and extracting meaningful insights from data.
Supervised learning is a type of machine learning where the model is trained using labeled data. In supervised learning, the dataset consists of input data and corresponding output labels. The goal is to learn a mapping function that can accurately predict the output labels for new, unseen input data. The model learns to make predictions based on the patterns and relationships in the labeled data. Examples of supervised learning algorithms include linear regression, decision trees, and neural networks.
On the other hand, unsupervised learning involves training a model on unlabeled data. In unsupervised learning, the objective is to discover hidden patterns, structures, or relationships within the dataset without any prior knowledge of the output labels. Unsupervised learning algorithms focus on clustering similar data points together or identifying patterns in the data. Common unsupervised learning techniques include k-means clustering, principal component analysis (PCA), and association rule mining.
The main difference between supervised and unsupervised learning lies in the availability of labeled data. In supervised learning, the labeled data explicitly provides the relationship between the input features and the output labels, making it easier for the model to learn and make accurate predictions. On the other hand, unsupervised learning operates purely on the input features without any knowledge of the output labels. It relies on intrinsic structures within the data to derive meaningful insights.
Supervised learning is suitable when the goal is to make predictions or classify data into predefined categories. It is commonly used in applications such as spam detection, sentiment analysis, and image recognition, where the desired output labels are known. Unsupervised learning, on the other hand, is useful when the objective is to explore and understand the underlying structure of the data, uncover hidden patterns, or perform data preprocessing tasks like dimensionality reduction.
Labelled and Unlabelled Data
In the context of machine learning, data can be categorized into two main types: labelled and unlabelled. The distinction between these types of data is crucial for understanding the different approaches used in supervised and unsupervised learning.
Labelled data refers to a dataset where each data point is accompanied by a corresponding output label. The labels provide information about the ground truth or the desired outcome for each input data point. For example, in a binary classification task, the labelled data would include input features as well as the respective labels indicating whether each data point belongs to class A or class B.
Unlabelled data, on the other hand, consists of input data without any associated output labels. It represents a collection of raw data points or observations that do not have predefined categories or classes. Unlabelled data is often used in unsupervised learning, where the goal is to discover patterns and structures within the data without prior knowledge of the output labels.
The availability of labelled data is paramount in supervised learning as it serves as the basis for training models. By providing input data along with their corresponding labels, models can learn to identify patterns and make accurate predictions for new, unseen data points. Labelled data acts as a valuable guide for supervised learning algorithms, enabling them to generalize from the training dataset to handle new data.
On the other hand, unlabelled data plays a crucial role in unsupervised learning, where the objective is to uncover hidden patterns and structures within the dataset. Without predefined labels, unsupervised learning algorithms rely solely on the inherent structure or relationships within the unlabelled data to identify similarities, clusters, or anomalies in the dataset.
It is worth noting that in many real-world applications, obtaining labelled data can be expensive, time-consuming, or even impossible in some cases. This scarcity of labelled data is a common challenge in machine learning projects. To address this, semi-supervised learning emerges as a promising approach that combines a limited amount of labelled data with a large amount of unlabelled data, creating a cost-effective solution for training models with enhanced performance.
The Importance and Challenges of Labelling Data
Labelling data is a crucial step in machine learning as it provides the necessary information for training models and making predictions. The process involves assigning meaningful and accurate labels or categories to the input data, enabling the model to learn from the labeled examples. While data labelling is essential, it can present various challenges and considerations that need to be addressed.
The importance of labelling data cannot be overstated. It serves as the foundation for supervised learning, where the goal is to train models to make accurate predictions based on the labelled examples. Without proper labelling, models would not have a reference point to learn from and would struggle to generalize to new, unseen data. Accurate labelling ensures that the model receives the correct information about the ground truth or desired outcome, allowing it to learn the relevant patterns and make informed predictions.
Despite its importance, labelling data can be a complex and labor-intensive process. Some of the challenges involved in data labelling include:
- Subjectivity: Labelling data can be subjective, especially when different annotators may have different interpretations or criteria for assigning labels. Ensuring consistency and reliability in the labeling process is crucial to obtain accurate and reliable training data.
- Expertise: Certain domains or industries require specialized knowledge to label data accurately. For example, medical data often requires expert knowledge to identify and label abnormalities or diseases correctly. Acquiring the necessary expertise or partnering with domain experts is essential to ensure accurate labelling in such cases.
- Cost and Time: Labeling large datasets can be time-consuming and costly. Hiring human annotators or utilizing crowdsourced platforms can help expedite the process, but it still requires significant resources and careful quality control to ensure accurate and reliable labelling.
- Unbalanced Classes: Imbalanced classes, where certain labels are overrepresented or underrepresented, can pose challenges in data labelling. Models trained on imbalanced data may exhibit biases or struggle to perform well on underrepresented classes. Careful sampling and data augmentation techniques are employed to alleviate this issue.
- Label Noise: In some cases, the labelled data may contain errors or inconsistencies that can introduce noise into the training process. Cleaning and validating the labelled data to minimize label noise is a critical preprocessing step in machine learning.
Overcoming these challenges requires careful planning, quality control measures, and continuous evaluation of the labelled data. It is essential to invest time and effort into ensuring accurate and reliable labelling to improve the performance and generalization capabilities of machine learning models.
Combining Labelled and Unlabelled Data
Combining labelled and unlabelled data is a fundamental concept in semi-supervised learning. This approach leverages the strengths of both types of data to improve the performance and generalization capabilities of machine learning models. By incorporating unlabelled data alongside labelled data, semi-supervised learning offers a cost-effective and efficient solution for training models in scenarios where labelled data is limited.
The combination of labelled and unlabelled data allows models to benefit from the specific patterns and relationships in the labelled data, while also capturing the more general underlying structure of the unlabelled data. This approach takes advantage of the fact that unlabelled data can contain valuable information that complements the labeled examples by providing a broader perspective on the data distribution.
There are various methods for effectively combining labelled and unlabelled data in semi-supervised learning. One common approach is to use the labeled data to train an initial model, which is then used to predict the labels of the unlabelled data. These predicted labels are then incorporated into the training process to refine the model further. This process, known as self-training, iteratively improves the model’s performance by utilizing both the labeled and pseudo-labeled examples.
Another approach involves using unsupervised learning algorithms to identify clusters or patterns within the unlabelled data. These identified clusters can then be used to augment the labeled data or guide the model’s learning process. This technique, known as cluster-based semi-supervised learning, can be particularly effective when the underlying structure of the data is complex or when the distribution of the labeled data is limited.
By combining labelled and unlabelled data, semi-supervised learning addresses the challenge of limited labeled data availability and improves the model’s ability to generalize to new, unseen data. This approach has shown promising results across various domains, including text classification, image recognition, and anomaly detection.
It is important to note, however, that the success of combining labelled and unlabelled data relies on the quality of the labeled data and the ability to effectively leverage the unlabelled data. Careful selection, preprocessing, and validation of the labeled data, as well as the consideration of the underlying data distribution, are crucial to ensure the effectiveness of the semi-supervised learning approach.
Overall, combining labelled and unlabelled data in semi-supervised learning offers a powerful approach to tackle the challenges of limited labeled data. By carefully incorporating the strengths of both types of data, models can achieve enhanced performance, improved generalization, and cost-effective training.
Semi-supervised Learning Algorithms
There are several algorithms and techniques available for implementing semi-supervised learning and effectively harnessing the power of both labelled and unlabelled data. These algorithms aim to leverage the benefits of both supervised and unsupervised learning and improve the performance of machine learning models.
One commonly used algorithm in semi-supervised learning is the self-training algorithm. This iterative method starts with a model trained using the labeled data. The model is then used to make predictions on the unlabelled data, and the predicted labels are incorporated into the training set as pseudo-labels. The model is then retrained using the augmented training set, and this process is repeated for a certain number of iterations or until convergence. Self-training can be effective when the initial model’s predictions on the unlabelled data are reliable.
Another popular algorithm is co-training, which utilizes multiple classifiers or models trained on different subsets of features. Each model is initially trained using the labeled data and then used to make predictions on the unlabelled data. The predictions of one model act as pseudo-labels for the other model, and vice versa. The models are then retrained using the augmented training sets, and this iterative process continues until convergence. Co-training is effective when the different subsets of features provide complementary information.
There is also the active learning approach, which involves selecting the most informative instances from the unlabelled data for manual labelling. Initially, a model is trained using a small portion of the labeled data. The model then identifies instances from the unlabelled data that it is uncertain about or has low confidence in predicting. These instances are selected for manual labelling, and the model is retrained using the augmented training set. This process is iterated, with the model actively selecting additional instances for labelling based on its current knowledge. Active learning aims to make efficient use of the available labelling resources by focusing on the most informative instances.
Semi-supervised learning can also be combined with techniques from unsupervised learning, such as clustering or dimensionality reduction. In these approaches, the unlabelled data is first processed using unsupervised techniques to identify clusters or reduce the dimensionality of the data. The resulting structures or representations are then used to guide the learning process of the model. This can help capture the underlying structure of the data and improve the model’s generalization abilities.
It is important to note that the choice of algorithm depends on various factors such as the nature of the data, the availability of labeled and unlabeled data, and the specific problem at hand. Each algorithm has its own advantages and considerations, and selecting the most appropriate one is crucial for achieving optimal results in semi-supervised learning tasks.
By utilizing these semi-supervised learning algorithms, researchers and practitioners can effectively leverage labeled and unlabeled data to enhance the performance and generalization capabilities of machine learning models. These algorithms offer a flexible and efficient approach for training models in scenarios where labeled data is limited.
Advantages of Semi-supervised Learning
Semi-supervised learning offers several advantages compared to traditional supervised or unsupervised learning approaches. By leveraging both labeled and unlabeled data, this approach provides a cost-effective and efficient solution for training machine learning models with enhanced performance and generalization capabilities.
One of the significant advantages of semi-supervised learning is the ability to utilize the large amount of unlabeled data that is often readily available. In many real-world scenarios, collecting and labeling large amounts of data can be time-consuming, costly, or even infeasible. By incorporating unlabeled data into the training process, semi-supervised learning effectively makes use of this valuable resource and improves the model’s ability to capture the underlying patterns and structures within the data.
Another advantage of semi-supervised learning is its potential to improve the model’s generalization capabilities. In supervised learning, models trained solely on limited labeled data may struggle to accurately classify or predict data points that deviate from the training distribution. By incorporating unlabeled data, semi-supervised learning allows models to capture a more comprehensive representation of the data distribution and generalize better to unseen data. This can result in improved performance and robustness of the models.
Semi-supervised learning also provides a flexible framework for handling real-world scenarios where labeled data is scarce or imbalanced. Traditional supervised learning may struggle with imbalanced classes, where certain labels are overrepresented or underrepresented in the training data. Semi-supervised learning offers the ability to incorporate additional information from the unlabeled data, which can help address the imbalance issue and improve the model’s performance on underrepresented classes.
Furthermore, the combination of labeled and unlabeled data in semi-supervised learning can lead to better utilization of available resources and time. Rather than relying solely on labeled data that may be limited in quantity or quality, semi-supervised learning expands the training set by leveraging the vast unlabeled data. This can result in more comprehensive learning and better utilization of computational resources, ultimately improving the efficiency of the learning process.
Overall, the advantages of semi-supervised learning include the ability to leverage unlabeled data, improved generalization capabilities, handling of imbalanced classes, and enhanced utilization of available resources. By exploiting both labeled and unlabeled data, semi-supervised learning presents a powerful approach that enhances the performance and efficiency of machine learning models. It offers a promising avenue for real-world applications where labeled data is limited or costly to obtain.
Applications of Semi-supervised Learning
Semi-supervised learning has wide-ranging applications across numerous domains, benefiting from the ability to leverage both labeled and unlabeled data. The flexible and efficient nature of semi-supervised learning makes it suitable for various real-world scenarios, where obtaining large amounts of labeled data can be challenging or expensive.
One prominent application of semi-supervised learning is in natural language processing. Language-related tasks such as text classification, sentiment analysis, and named entity recognition often benefit from the use of unlabeled data. By incorporating unannotated text data, semi-supervised learning algorithms can effectively learn language patterns, word embeddings, and semantic relationships, leading to improved performance in language processing tasks.
Medical research and healthcare also benefit from the application of semi-supervised learning. In medical imaging, where manual annotation of images is often time-consuming and requires expert knowledge, semi-supervised learning can assist in improving diagnosis and detection. By combining labeled medical images with large amounts of unlabeled images, machine learning models can learn to identify patterns and anomalies more accurately, leading to more precise medical predictions and diagnoses.
In the field of computer vision, the application of semi-supervised learning is valuable for tasks such as object recognition, image segmentation, and video analysis. Unlabeled images can be used to effectively learn visual features and representations, aiding in the development of more robust and accurate computer vision models. Semi-supervised learning can also be particularly useful in scenarios where labeled training datasets contain only a limited number of object instances or categories.
Another area where semi-supervised learning finds application is in fraud detection and anomaly detection. By combining labeled instances of fraudulent or anomalous behavior with large amounts of unlabeled data, machine learning algorithms can better learn the patterns and characteristics associated with potential fraud or anomalies. This application is particularly useful in industries like finance, cybersecurity, and network intrusion detection.
Semi-supervised learning also plays a role in recommendation systems and personalized advertising. By leveraging unlabeled data, such as user browsing histories or clickstream data, machine learning models can identify consumer preferences, uncover hidden patterns, and make more accurate predictions for personalized recommendations or targeted advertisements. Semi-supervised learning enables the models to adapt to individual user behavior while taking advantage of the collective insights from large amounts of unlabeled data.
These are just a few examples showcasing the diverse range of applications for semi-supervised learning. From language processing to healthcare, computer vision to fraud detection, and personalized advertising to recommendation systems, semi-supervised learning proves to be a valuable technique for leveraging the power of both labeled and unlabeled data. Its ability to utilize unlabeled data efficiently improves the accuracy, robustness, and efficiency of machine learning models across various domains and industries.
Ethical Considerations in Semi-supervised Learning
While semi-supervised learning offers numerous benefits, it is important to consider the ethical implications that arise when leveraging unlabeled data and incorporating it into the training process. Ethical considerations play a vital role in ensuring that the use of semi-supervised learning is responsible, fair, and respects individual privacy and data protection rights.
One ethical consideration is the potential for unintended biases in the training data. If the unlabeled data used in semi-supervised learning contains inherent biases, these biases may be amplified and perpetuated in the learning process. Biased data can lead to discriminatory or unfair outcomes, especially in applications involving sensitive attributes such as race, gender, or socioeconomic status. Careful preprocessing and bias detection techniques are necessary to mitigate the risk of perpetuating biases in semi-supervised learning models.
Privacy is another crucial ethical consideration in semi-supervised learning. Unlabeled data often includes personally identifiable information (PII) that can compromise individuals’ privacy rights. Anonymization techniques, data minimization, and ensuring compliance with privacy regulations are necessary to protect individuals’ privacy when using unlabeled data. Organizations must be transparent in their data collection and usage practices and ensure that individuals’ consent and privacy are respected.
Additionally, transparency and explainability are important ethical considerations in semi-supervised learning. Models trained on semi-supervised learning algorithms may be more complex than models trained solely on labeled data. It is essential to ensure that the decision-making process of the model is transparent and interpretable. Explaining how the model arrived at its predictions can help build trust and accountability and ensure that decisions made by the model can be justified and understood.
Data security is another ethical concern in semi-supervised learning. Unlabeled data, if compromised, can lead to violations of data security and breaches of sensitive information. Organizations must implement robust data security measures to protect both labeled and unlabeled data throughout the training and deployment process.
Furthermore, the responsible use of unlabeled data in semi-supervised learning requires ongoing monitoring and evaluation. Regular assessments of model performance, fairness, and ethical implications must be conducted to ensure that the learning process remains unbiased, fair, and aligned with ethical principles.