
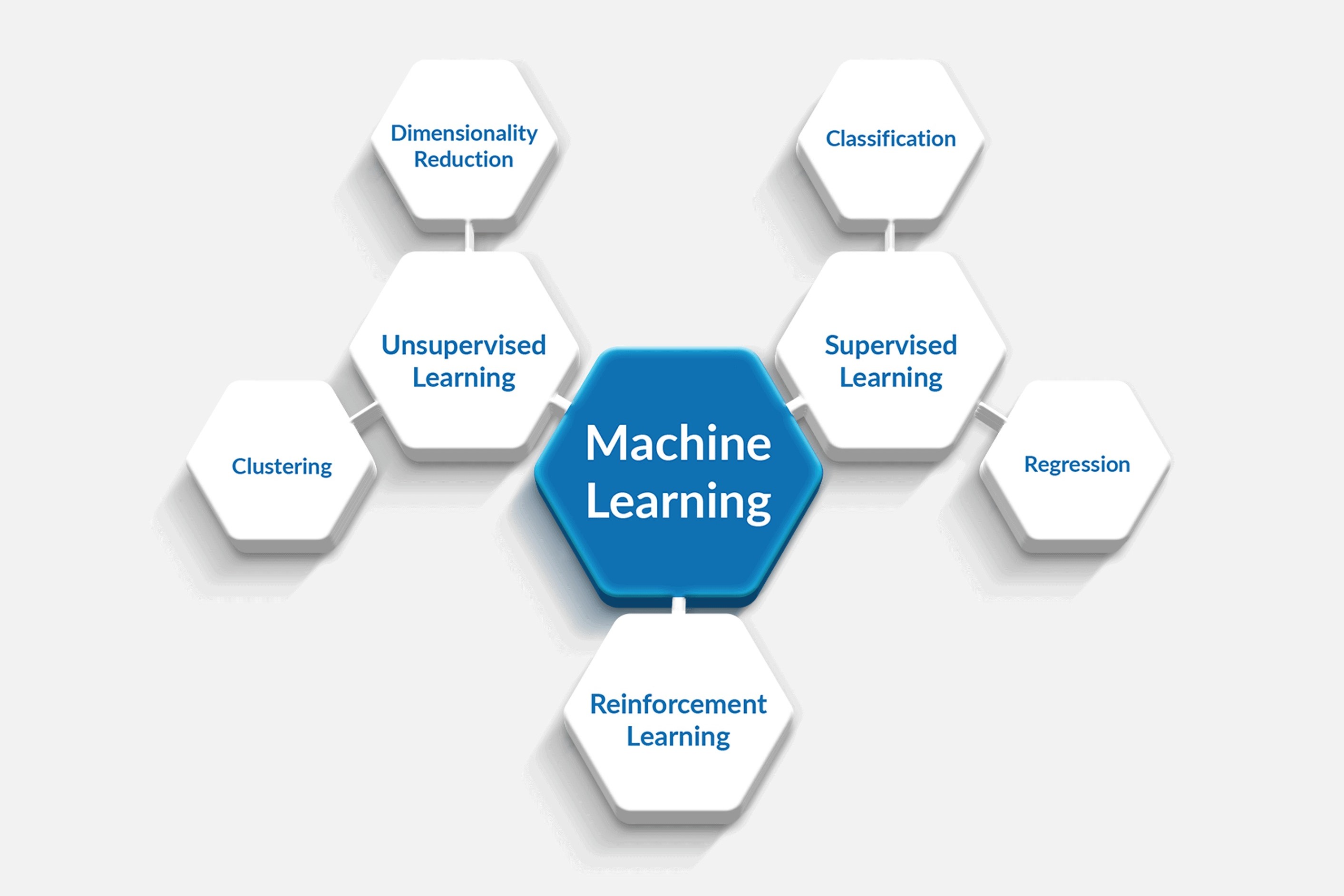
Supervised Learning
Supervised learning is a widely used approach in machine learning, wherein the algorithm learns from a labeled dataset. In this type of learning, the input data is paired with corresponding output labels. The main objective is to train the algorithm to predict the correct output when presented with new, unseen input data.
The labeled dataset acts as a guide for the learning process. It consists of input-output pairs, where the inputs are the features and the outputs are the desired target values. During training, the algorithm analyzes the relationship between the inputs and outputs and creates a model that can make accurate predictions.
There are various techniques employed in supervised learning, including classification and regression. In classification, the algorithm learns to categorize data into predefined classes or categories. For example, given a dataset of emails, the algorithm can be trained to classify them as spam or non-spam based on a set of features.
On the other hand, regression is used when the objective is to predict a continuous value. For instance, a regression model can be trained to estimate the price of a house based on factors such as location, size, and number of bedrooms.
Supervised learning algorithms make use of different approaches, such as decision trees, support vector machines (SVM), naive Bayes, and artificial neural networks (ANN). These algorithms analyze the patterns and relationships in the labeled data to make accurate predictions on new, unseen data.
Applications of supervised learning are abundant across various domains. It is commonly used in email filtering, sentiment analysis, spam detection, image recognition, and recommendation systems. The availability of labeled data is crucial for the success of supervised learning algorithms, as it provides the necessary information for training and evaluation.
Overall, supervised learning has proven to be a powerful and effective approach in machine learning. By leveraging labeled data, these algorithms can make accurate predictions and contribute to solving complex real-world problems.
Unsupervised Learning
Unsupervised learning is a branch of machine learning where the algorithm learns to detect patterns and relationships in unlabeled data. Unlike supervised learning, there are no predefined output labels provided during training. The goal of unsupervised learning is to discover hidden structures or groupings within the data without any prior knowledge.
Clustering is one of the key techniques used in unsupervised learning, where the algorithm groups similar data points together based on certain criteria. This helps in identifying patterns and trends in the data. For example, in customer segmentation, unsupervised learning can be used to group customers with similar purchasing behavior, allowing businesses to tailor their marketing strategies accordingly.
Another important approach in unsupervised learning is dimensionality reduction. This involves reducing the number of features in the dataset while preserving the essential information. Dimensionality reduction techniques like Principal Component Analysis (PCA) and t-Distributed Stochastic Neighbor Embedding (t-SNE) are commonly used to visualize high-dimensional data and extract meaningful insights.
Unsupervised learning algorithms also include methods such as anomaly detection, where the goal is to identify unusual or outlier data points in the dataset. This can be useful for fraud detection, network intrusion detection, or identifying rare diseases in medical data.
One advantage of unsupervised learning is its ability to automatically discover patterns and structures in the data, without requiring a labeled dataset for training. This makes it particularly useful in scenarios where labeled data is scarce or costly to obtain.
Some common applications of unsupervised learning include market basket analysis, image and text clustering, recommendation systems, and data preprocessing for other machine learning tasks. It plays a crucial role in exploratory data analysis, enabling researchers and analysts to gain insights into the dataset before moving on to more advanced analyses.
In summary, unsupervised learning is a valuable approach in machine learning that allows algorithms to uncover patterns and structures in unlabeled data. It provides a means to gain deeper insights into the data and can be applied to a wide range of real-world problems across various domains.
Semi-supervised Learning
Semi-supervised learning is a hybrid approach that combines elements of supervised and unsupervised learning. It leverages both labeled and unlabeled data to train a machine learning model. While labeled data plays a crucial role in traditional supervised learning, semi-supervised learning uses the availability of a small amount of labeled data along with a larger amount of unlabeled data to improve the model’s performance.
The idea behind semi-supervised learning is that unlabeled data can provide additional information to enhance the learning process. By utilizing both labeled and unlabeled data, the model can capture the underlying structure of the data more effectively and make more accurate predictions.
There are different approaches to semi-supervised learning. One common method is to use the labeled data to initially train a model and then incorporate the unlabeled data to fine-tune and improve the model’s performance. This can be done through techniques like self-training, where the model makes predictions on the unlabeled data and uses them as additional labeled examples for training.
Another approach in semi-supervised learning is to leverage the clustering or grouping of unlabeled data to assign labels to similar data points. This is known as the “cluster assumptions” where the assumption is that points within the same cluster are likely to have the same label. This can be particularly useful when the labeled data is limited or costly to obtain.
Semi-supervised learning has various applications, especially in scenarios where gathering large amounts of labeled data is difficult or expensive. It has been successfully applied in fields such as natural language processing, speech recognition, image recognition, and cybersecurity.
The effectiveness of semi-supervised learning depends on the availability of a well-labeled dataset and the quality of the unlabeled data, as well as the ability of the algorithm to extract meaningful information from both sources. While it offers a promising middle ground between supervised and unsupervised learning, careful consideration and validation are required to ensure its successful implementation in specific problems.
In summary, semi-supervised learning provides a powerful approach that combines elements of both supervised and unsupervised learning to leverage labeled and unlabeled data for improved model performance. By utilizing additional information from unlabeled data, it offers a cost-effective and efficient way to enhance predictions and solve complex real-world problems.
Reinforcement Learning
Reinforcement learning is a type of machine learning that focuses on training agents to make sequential decisions in dynamic environments. Unlike supervised and unsupervised learning, reinforcement learning involves learning from interactions with the environment rather than relying on labeled or unlabeled data.
In reinforcement learning, the agent learns through a trial-and-error process, receiving feedback in the form of rewards or penalties based on its actions. The objective is to maximize the cumulative reward over time by selecting the actions that lead to the highest possible outcome.
The core concept in reinforcement learning is the notion of an agent and an environment. The agent takes actions in the environment, and the environment responds with state transitions and rewards. The agent learns by exploring different actions and observing the consequences of those actions in terms of rewards or penalties.
One of the key features of reinforcement learning is the use of an exploration-exploitation trade-off. To maximize long-term rewards, the agent needs to explore different actions to discover the best strategies. At the same time, it also needs to exploit the knowledge it has acquired to make optimal decisions based on previous experiences.
Reinforcement learning algorithms utilize various techniques, such as value-based methods, policy-based methods, and model-based methods. Value-based methods aim to learn the optimal value function that estimates the expected future rewards for each state or action. Policy-based methods, on the other hand, directly learn the policy that maps states to actions. Model-based methods involve building a model of the environment and using it to simulate interactions and make predictions.
Reinforcement learning has been applied successfully in a wide range of domains, including robotics, game playing, recommendation systems, finance, and autonomous vehicles. One notable example is AlphaGo, a reinforcement learning system developed by DeepMind, which achieved remarkable success in playing the ancient board game Go.
While reinforcement learning offers great potential, it also poses unique challenges. The agent needs to strike a balance between exploration and exploitation, and the learning process can be time-consuming and computationally intensive. Additionally, designing appropriate reward functions and handling sparse rewards can be challenging in complex environments.
In summary, reinforcement learning provides a powerful framework for training agents to make sequential decisions in dynamic environments. Through a process of learning from interaction and maximizing future rewards, reinforcement learning enables agents to learn optimal strategies and solve complex problems in a variety of domains.
Transfer Learning
Transfer learning is a machine learning technique that allows the knowledge gained from training one model to be applied to solve a different but related task. It involves taking a pre-trained model, which has been trained on a large dataset for a specific task, and using it as a starting point for training a new model for a related task.
With transfer learning, the pre-trained model acts as a feature extractor, where the learned representations of the input data are transferred to the new model. This initialization helps the new model to perform better and requires less training data compared to training a model from scratch.
There are two main scenarios in transfer learning:
- Application transfer: In this scenario, the pre-trained model is applied directly to a similar task. For example, a model trained on a large image dataset for image classification can be fine-tuned and transferred to a new image classification task with a smaller dataset. The lower layers of the pre-trained model, which capture general features, remain unchanged, while the higher layers are adjusted to fit the new task.
- Domain transfer: In this scenario, the pre-trained model is applied to a different domain but a related task. For instance, a model trained on a dataset of natural images can be used as a starting point for a model that detects objects in medical images. Although the domains are different, the lower-level features learned by the pre-trained model can still be useful.
Transfer learning offers several benefits. It helps in overcoming the limitation of limited training data, as pre-trained models have already learned valuable representations from large, diverse datasets. The use of transfer learning can speed up the training process and improve the overall performance of the model, especially in scenarios where labeled data is scarce or expensive to obtain.
However, transfer learning also has some considerations. The pre-trained model should be chosen carefully to ensure that it is well-suited for the new task. The similarity between the original task and the new task will determine how much knowledge can be transferred. Fine-tuning the pre-trained model requires careful adjustment of hyperparameters and regularization techniques to avoid overfitting.
Transfer learning has found applications in various areas, including computer vision, natural language processing, and audio processing. It has enabled breakthroughs in tasks such as object recognition, sentiment analysis, and speech recognition. Researchers and practitioners continue to explore and develop new techniques to push the boundaries of transfer learning.
In summary, transfer learning is a valuable technique in machine learning that allows the transfer of knowledge from pre-trained models to new tasks. By leveraging the learned representations, it enables the improvement of model performance, reduces the need for large amounts of labeled data, and accelerates the training process.
Active Learning
Active learning is a machine learning approach that involves an interactive process of data labeling, where the algorithm actively selects the most informative or uncertain data points to be labeled by an expert or a human annotator. By iteratively incorporating feedback and updating the model, active learning aims to achieve higher accuracy with fewer labeled examples.
In traditional supervised learning, a large labeled dataset is required upfront, but in active learning, the algorithm starts with a small labeled dataset. The algorithm then selects unlabeled data points from a larger pool and presents them to the annotator for labeling. The goal is to strategically choose data points that are likely to improve the model’s performance the most.
There are different strategies employed in active learning for selecting the most informative data points. One common approach is uncertainty sampling, where the algorithm selects instances that it is most uncertain about or for which it has low confidence in its predictions. This allows the model to learn from the most challenging and informative examples.
Another strategy is to select data points that are on the decision boundary between different classes. This helps the algorithm to refine its boundaries and create a more accurate decision boundary. Sampling based on diversity is also employed, aiming to ensure a diverse representation of the data distribution, avoiding redundancy and bias in the training data.
Active learning can be particularly beneficial in scenarios where the cost of labeling new data or obtaining expert annotations is high. By actively selecting the most informative data points, active learning reduces the labeling effort and time required to train a model.
Active learning has practical applications in various domains, including text classification, image classification, and document analysis. It is used in tasks such as sentiment analysis, object detection, and document categorization. The potential applications of active learning are vast, especially in situations where labeled data collection is challenging or expensive.
However, active learning also presents its own challenges. The effectiveness of the active learning process highly depends on the quality of the selection strategy and the expertise of the annotator. The selection strategy needs to strike a balance between exploration and exploitation, selecting both representative points and points that challenge the current model’s understanding.
In summary, active learning is an iterative approach in machine learning that actively selects the most informative data points to be labeled, reducing the labeling effort and increasing the model’s accuracy. By intelligently choosing which examples to be labeled, active learning streamlines the annotation process and enhances the learning process.
Deep Learning
Deep learning is a subfield of machine learning that focuses on training artificial neural networks with multiple layers of interconnected nodes, known as artificial neurons or units. It involves the creation and training of deep neural networks to learn and extract patterns and representations from complex data.
The key advantage of deep learning is its ability to automatically learn hierarchical representations of data at different levels of abstraction. Each layer in a deep neural network learns to extract increasingly complex features from the input data, allowing the model to capture intricate patterns and relationships that may be difficult to discern with traditional machine learning algorithms.
Deep learning has gained significant attention and popularity in recent years due to its remarkable performance in various areas. Convolutional Neural Networks (CNNs) have revolutionized computer vision tasks, such as image classification, object detection, and image generation. Recurrent Neural Networks (RNNs) have shown exceptional results in natural language processing tasks, such as language translation, speech recognition, and text generation.
One of the reasons for the success of deep learning is the availability of vast amounts of data, as deep neural networks require substantial data for training. Another crucial factor is the advancement of computational resources, particularly the availability of powerful Graphics Processing Units (GPUs), which enable the efficient training and evaluation of deep neural networks.
Training deep neural networks involves a process called backpropagation, where the model adjusts its internal parameters or weights to minimize the difference between predicted and actual outputs. The optimization is typically performed using gradient descent or variations of it, which optimize the network’s performance by fine-tuning the weights of the connections between units.
While deep learning has achieved significant breakthroughs, it also poses certain challenges. Deep neural networks are prone to overfitting, where the model becomes too specialized in the training data and performs poorly on unseen examples. Regularization techniques and large diverse datasets can help mitigate this issue.
Deep learning has been applied successfully in various domains, including healthcare, finance, natural language processing, computer vision, and robotics. Its capability to extract complex features and learn representations directly from raw data has led to unprecedented advancements in tasks such as disease diagnosis, autonomous driving, fraud detection, and voice assistants.
In summary, deep learning is a powerful branch of machine learning that leverages deep neural networks to learn hierarchical representations and extract patterns from complex data. With its ability to handle large and diverse datasets, deep learning has transformed many fields and continues to drive innovation in artificial intelligence and machine learning.