
Types of Database Relationships
When designing a database, it’s essential to understand the different types of relationships that can exist between tables. These relationships determine how data is connected and organized within the database. In this section, we will explore the three main types of database relationships: one-to-one, one-to-many, and many-to-many.
1. One-to-One Relationship: In a one-to-one relationship, each record in the first table is associated with exactly one record in the second table, and vice versa. This type of relationship is often used to split a table into two for better organization or to store optional or additional information. For example, in a database for employee records, a separate table may be created to store details about the employee’s benefits package.
2. One-to-Many Relationship: A one-to-many relationship is the most common type of relationship. In this scenario, a record in the first table can be associated with one or more records in the second table. However, each record in the second table can only be linked to one record in the first table. An example of this relationship would be a database that links customers to orders. One customer can have multiple orders, but each order is associated with only one customer.
3. Many-to-Many Relationship: In a many-to-many relationship, each record in the first table can be associated with multiple records in the second table, and vice versa. This type of relationship requires a third table, known as a junction or mapping table, to connect the two tables. An example of this relationship would be a database for students and courses. Each student can enroll in multiple courses, and each course can have multiple students.
Understanding these types of relationships is crucial for database management and ensuring data integrity. By establishing the appropriate relationships, you can efficiently organize and retrieve data based on the desired connections. It’s important to consider the nature of the data and the specific requirements of your database when determining the appropriate relationship type to implement.
Continue reading to learn about primary keys and foreign keys, which play a vital role in establishing and maintaining these relationships.
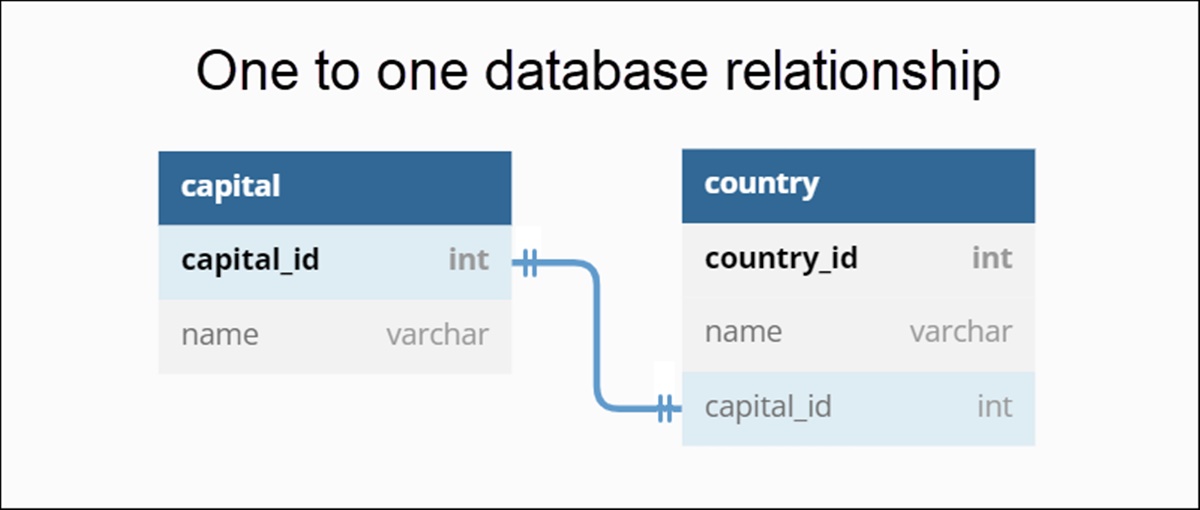
One-to-One Relationship
In a one-to-one relationship, each record in the first table is associated with exactly one record in the second table, and vice versa. This type of relationship is often used to split a table into two for better organization or to store optional or additional information.
To understand this relationship, let’s consider a hypothetical example of a company’s employee database. The main table contains essential employee information such as name, address, and contact details. However, there may be additional information that is not relevant for all employees, such as benefits details or emergency contact information.
To handle this scenario, a separate table can be created specifically for storing this optional information. Each record in the additional information table is linked to a corresponding record in the employee table through a shared key, typically a unique identifier such as an employee ID.
One advantage of implementing a one-to-one relationship in this scenario is the ability to efficiently manage and update the optional information. Since this information is stored in a separate table, it can be easily added, modified, or removed without impacting the main employee table. It also ensures that the database remains well-organized, with relevant information kept together.
However, it’s important to note that not all scenarios may require a one-to-one relationship. If the optional information is relevant to all employees, it can simply be included as additional columns in the main employee table. The decision to implement a one-to-one relationship depends on the specific requirements of the database and the nature of the data being stored.
In summary, a one-to-one relationship is used when each record in one table is associated with exactly one record in another table. It offers the flexibility to store optional or additional information separately, providing a more streamlined and efficient database design. By understanding the different types of database relationships, you can optimize your database structure to store and retrieve data effectively.
One-to-Many Relationship
A one-to-many relationship is the most common type of relationship in database design. In this scenario, a record in the first table can be associated with one or more records in the second table. However, each record in the second table can only be linked to one record in the first table.
To better understand this relationship, let’s consider an example of an e-commerce database. The main table in this case would be the “Customers” table, which stores information about each customer, such as their name, address, and contact details. The second table, the “Orders” table, would contain details about each order placed by a customer, including the order ID, date, and total price.
Each customer can have multiple orders in the “Orders” table, but each order is associated with only one customer in the “Customers” table. This linkage is achieved by creating a foreign key in the “Orders” table that references the primary key in the “Customers” table.
One of the advantages of a one-to-many relationship is the ability to efficiently retrieve and manage data. For example, if you want to view all orders placed by a specific customer, you can leverage the relationship between the two tables to easily filter the data. This allows for effective tracking of customer orders and facilitates targeted marketing or customer support efforts.
It’s important to ensure data integrity in a one-to-many relationship. The foreign key in the second table should always refer to a valid primary key in the first table. Additionally, database constraints can be used to enforce referential integrity, preventing the deletion of a record in the first table if it is associated with records in the second table.
In summary, a one-to-many relationship is used when a record in one table can be associated with one or more records in another table, but each record in the second table can only be linked to one record in the first table. It is commonly employed in scenarios where there is a hierarchy or a collection of related data. By understanding and implementing this type of relationship correctly, you can ensure a well-structured and efficiently managed database.
Many-to-Many Relationship
A many-to-many relationship is a type of relationship in database design where each record in one table can be associated with multiple records in another table, and vice versa. This relationship requires the use of a third table, known as a junction or mapping table, to connect the two tables together.
To illustrate this relationship, let’s consider a hypothetical example of a student-course database. The first table, the “Students” table, stores information about each student, such as their name, student ID, and contact details. The second table, the “Courses” table, contains details about each course, including the course ID, title, and instructor.
In a many-to-many relationship, each student can enroll in multiple courses, and each course can have multiple students. To establish this relationship, a third table, often named “Enrollment” or “StudentCourses,” is created. This table acts as a bridge between the “Students” and “Courses” tables, containing the foreign keys from both tables as its primary key.
The “Enrollment” table typically includes additional information specific to the student’s enrollment in a particular course, such as the date of enrollment or the final grade achieved. This table allows for a flexible and dynamic association between students and courses.
A many-to-many relationship provides several advantages. It facilitates efficient retrieval and analysis of data, allowing you to easily answer questions such as which students are enrolled in a specific course or which courses a particular student is taking. It also allows for flexibility in managing course offerings and student enrollment over time, as records can be added or removed from the “Enrollment” table as needed.
It’s important to note that the implementation of a many-to-many relationship using a junction table helps maintain data integrity and reduces data duplication. It also provides a scalable solution to handle complex relationships, enabling connections between multiple entities in the database.
In summary, a many-to-many relationship is used when each record in one table can be associated with multiple records in another table, and vice versa. It requires the use of a junction table to connect the two tables together. This relationship is commonly used in scenarios where there is a need for flexible associations between entities, such as students and courses. By understanding and properly implementing many-to-many relationships, you can create a robust and versatile database structure.
Understanding Primary Keys and Foreign Keys
Primary keys and foreign keys are essential concepts in database design that play a crucial role in establishing and maintaining relationships between tables. Let’s take a closer look at each of these concepts.
Primary Key: A primary key is a unique identifier for each record in a table. It ensures that each record can be uniquely identified and accessed within the table. Typically, primary keys are implemented using an auto-incrementing integer column or a unique combination of columns that uniquely identify a record. The primary key provides a reference point for other tables to establish relationships.
An example of a primary key can be found in the “Customers” table, where each customer is assigned a unique customer ID. This ID serves as the primary key, enabling quick and efficient identification of specific customers in other tables.
Foreign Key: A foreign key is a field in a table that references a primary key in another table. It establishes a link between two tables and represents the relationship between them. By utilizing foreign keys, you can establish relationships such as one-to-one, one-to-many, or many-to-many between tables.
Continuing with the “Customers” table example, suppose there is a second table named “Orders” that stores details about each order placed by customers. In the “Orders” table, a foreign key can be created that references the primary key in the “Customers” table. This foreign key connects each order to the corresponding customer, establishing a one-to-many relationship.
Foreign keys help maintain referential integrity in the database. They ensure that records in related tables remain consistent and properly connected. For instance, if a customer record is deleted from the “Customers” table, the related order records in the “Orders” table can be automatically updated or cascaded to maintain data integrity.
It’s important to note that primary keys and foreign keys are not limited to simple numeric or alphanumeric values. They can also be composite keys, which are formed by a combination of multiple columns to create a unique identifier.
Overall, primary keys and foreign keys are crucial components in designing a well-structured and interconnected database. They enable relationships between tables, maintain data integrity, and facilitate efficient data retrieval and management. By understanding the concept and implementation of primary keys and foreign keys, you can create robust and meaningful relationships within your database.
Creating Database Relationships
Creating relationships between tables in a database involves defining and implementing the appropriate keys and constraints. Let’s explore the steps involved in creating database relationships.
1. Identify the Relationship Type: Determine the type of relationship that exists between the tables. Is it a one-to-one, one-to-many, or many-to-many relationship?
2. Establish Primary Keys: Each table should have a primary key, which uniquely identifies each record within the table. Choose a suitable column or combination of columns to serve as the primary key for each table.
3. Define Foreign Keys: Identify the tables that need to be linked together and determine which table will hold the foreign key. Create a foreign key column in the referencing table that corresponds to the primary key of the referenced table.
4. Set Referential Integrity Constraints: Establish referential integrity constraints to maintain data consistency. This ensures that the foreign key values in the referencing table match the primary key values in the referenced table. Constraints such as “ON DELETE CASCADE” or “ON UPDATE CASCADE” can be applied to automatically update or delete related records when changes are made to the primary key.
5. Implement Indexes: Create indexes on the columns used as primary and foreign keys. Indexes improve the performance of queries by speeding up data retrieval.
6. Test the Relationships: Verify that the relationships are correctly established by performing test queries and operations. Ensure that data is being properly retrieved and modified without integrity violations.
It’s important to note that database management systems (DBMS) often provide graphical tools or query languages to facilitate the creation of relationships. These tools simplify the process by allowing you to visually define the relationships between tables and automatically generate the corresponding keys and constraints.
By carefully creating database relationships, you can ensure efficient data management, maintain data integrity, and optimize query performance. Understanding the relationship types and following best practices in establishing and managing relationships are key aspects in designing a well-organized and functional database system.
BONUS: Common Challenges in Database Relationships
Building and managing database relationships can present various challenges that need to be addressed for a successful database design. Let’s explore some common challenges that arise when working with database relationships.
1. Data Integrity: Maintaining data integrity is crucial in database relationships. It becomes a challenge when updates or deletions are made, and the referential integrity constraints are not properly enforced. This can result in orphaned records or integrity violations, jeopardizing the accuracy and reliability of the data.
2. Performance Optimization: In a database with complex relationships, fetching and manipulating data from multiple tables can impact query performance. This challenge can be addressed by optimizing queries, using appropriate indexes, and considering database caching techniques to improve overall system performance.
3. Handling Many-to-Many Relationships: Many-to-many relationships require the use of a junction or mapping table, which can introduce complexities. Properly designing and managing the junction table, handling cascading operations, and efficiently retrieving data from many-to-many relationships can be challenging.
4. Redundancy and Data Duplication: When multiple tables have redundant data, it can lead to data duplication and inconsistencies. This challenge can be addressed by identifying common fields and creating separate tables to store shared data, reducing redundancy and ensuring data consistency.
5. Evolving Relationships: As business requirements change over time, the relationships between entities may also evolve. Adapting the database structure to accommodate these changes without causing data inconsistencies can be a challenge. Proper planning, effective migration strategies, and using tools with schema evolution capabilities can help mitigate this challenge.
6. Complex Queries: Sometimes, retrieving data from multiple tables with complex relationships involves writing intricate SQL queries. Ensuring the accuracy and efficiency of these queries, as well as managing query complexity, can be challenging. Proper indexing, optimizing query execution plans, and breaking down complex queries into manageable subqueries or views can help address this challenge.
It’s essential to identify and address these challenges during the database design and maintenance process. This involves employing best practices, utilizing robust database management systems, and staying updated with the latest techniques and tools available.
By understanding and effectively managing these challenges, you can ensure a well-structured and efficient database system that meets the needs of your organization and supports data integrity and performance requirements.