
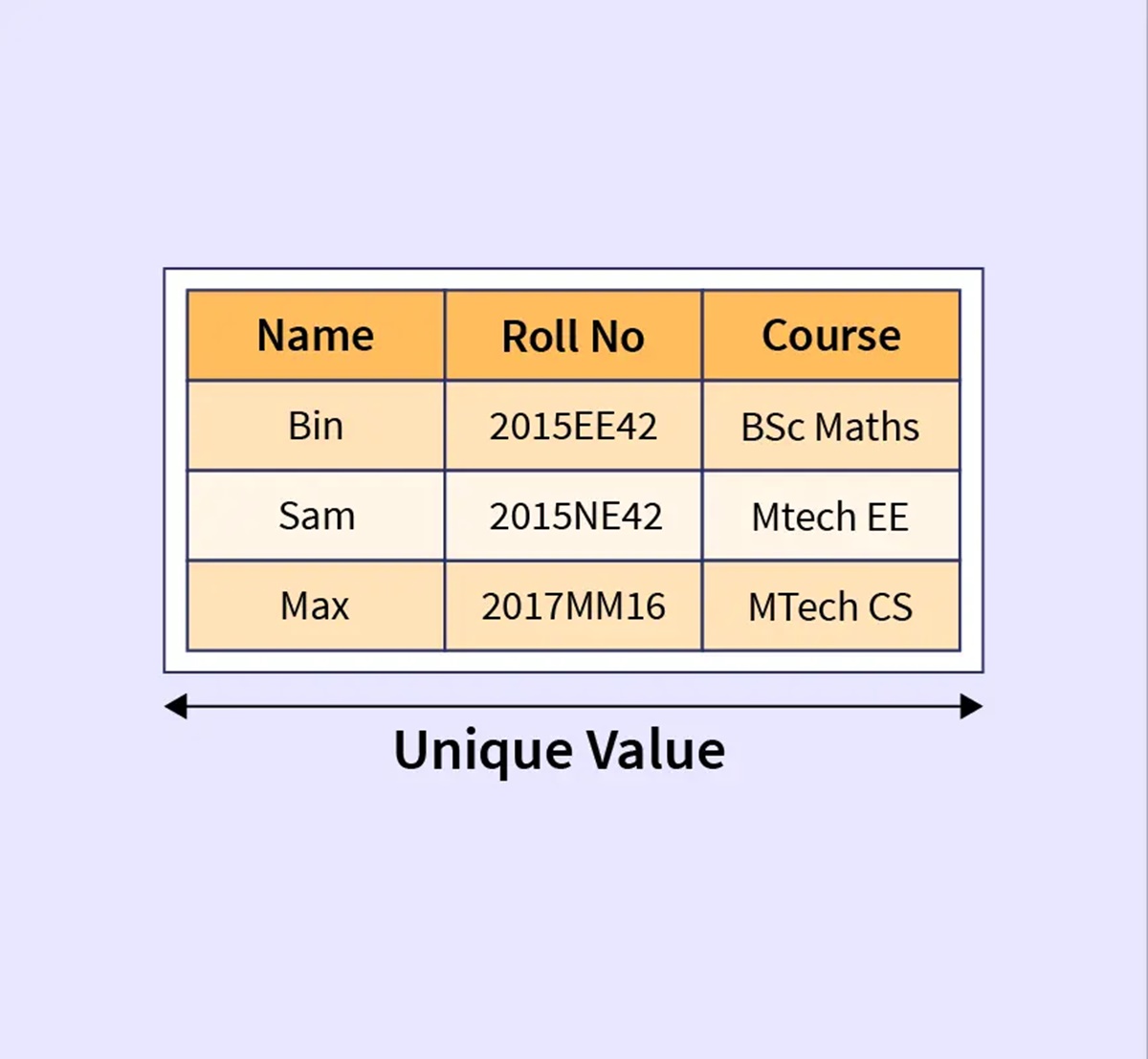
What is a Database Domain?
A database domain refers to the set of values that a particular field in a database table can contain. It defines the acceptable range and type of data that can be stored in a specific field. In simple terms, it determines the characteristics and limitations of a data field, ensuring data integrity and consistency within the database.
Imagine a database as a filing system, with different folders containing various types of documents. Each folder represents a table, and each document within the folder represents a record. Now, within each record, we have different fields to store specific information like names, addresses, or phone numbers. The database domain defines the structure and constraints of these fields, ensuring that the data entered is accurate, valid, and meaningful.
For example, consider a field that stores the age of individuals. The database domain for this field would specify that the values must be numeric and within a certain range, such as 0-120. This prevents incorrect data, like negative or unrealistic age values, from being entered.
A database domain also helps in optimizing storage space and query performance. By defining the appropriate data types and field lengths, we can minimize the amount of storage required and improve the speed of data retrieval and manipulation.
Moreover, a well-defined database domain serves as a blueprint for designing effective validation rules and data constraints. It enables the system to enforce the consistency, accuracy, and integrity of the data, reducing the chances of errors or inconsistencies in the database.
Overall, the database domain plays a crucial role in establishing the foundation for a well-structured and efficient database system. It sets the guidelines for storing and organizing data, ensuring its accuracy, integrity, and reliability.
Why is Defining a Database Domain Important?
Defining a database domain is imperative for creating a solid foundation for database management. It offers a myriad of benefits that contribute to the overall efficiency, accuracy, and reliability of the data stored within the system.
First and foremost, defining a database domain ensures data integrity. By specifying the allowed data types, ranges, and constraints for each field, it prevents the entry of invalid or inconsistent data. This helps maintain the overall quality of the database, as erroneous or irrelevant data can hinder decision-making processes and compromise the reliability of the system.
Additionally, a well-defined database domain enhances data consistency. It enforces standardized formatting and structure, reducing duplication and ensuring uniformity across all records. This standardization facilitates easy data retrieval and analysis, enabling users to generate accurate reports and draw meaningful insights.
Defining a database domain also contributes to system performance and efficiency. By precisely defining the data types and field lengths, it optimizes storage space and improves query performance. This streamlined approach accelerates data retrieval, manipulation, and reporting, enabling faster and more efficient operations within the database.
Furthermore, a database domain aids in establishing robust validation rules and data constraints. By defining the criteria for acceptable data, it helps maintain data accuracy and consistency. This minimizes the risk of input errors and ensures that only valid and meaningful information is stored in the database.
In addition, a properly defined database domain simplifies system maintenance and future enhancements. Database administrators can easily identify and understand the purpose and restrictions of each field, simplifying the modification, expansion, or integration of new functionalities into the existing system.
Lastly, a well-defined database domain promotes data security and privacy. By implementing appropriate constraints and access controls, it helps protect sensitive information from unauthorized access and improper usage. This is particularly crucial in industries where data confidentiality and compliance are paramount.
Key Components of a Database Domain
A database domain consists of several key components that define the characteristics and limitations of the data stored within a field. These components play a crucial role in ensuring data integrity, accuracy, and consistency. Let’s explore the key components of a database domain:
Data Type: The data type is an essential component of a database domain. It determines the kind of data that can be stored in a field, such as integers, strings, dates, or booleans. Choosing the appropriate data type is vital as it affects the storage space, query performance, and validity of the data entered.
Field Length: The field length specifies the maximum number of characters or digits that a field can hold. It is crucial to define an appropriate field length to avoid truncation of data or excessive storage space consumption.
Validation Rules: Validation rules are used to define criteria that data must meet to be considered valid. These rules ensure that the entered data conforms to specific formats or meets certain conditions. For example, a validation rule can specify that an email address must contain an “@” symbol and a domain name. Implementing validation rules helps maintain data accuracy and consistency.
Field Constraints: Field constraints set additional restrictions on the data stored in a field. These constraints can include specifying a required field, limiting the range of allowed values, or setting default values. By enforcing field constraints, any attempts to enter invalid or inappropriate data can be prevented.
Data Integrity: Data integrity ensures that data remains accurate, consistent, and valid throughout its lifecycle. It encompasses various techniques, such as primary key constraints, unique constraints, and referential integrity. By maintaining data integrity, the database can avoid discrepancies, conflicts, and data corruption.
Relations: Relations define the connections and dependencies between different tables within a database. They establish relationships, such as one-to-one, one-to-many, or many-to-many, allowing data to be efficiently organized and retrieved. Defining and properly implementing relationships is essential for maintaining data consistency and enabling efficient data retrieval.
Indexing and Query Optimization: Indexing is a technique used to improve query performance by creating an index on specific fields. It enables faster data retrieval by storing a sorted copy of the indexed field’s values. Query optimization involves analyzing and optimizing the execution plans of queries to minimize response times and resource usage. These techniques are crucial for efficient data retrieval and manipulation.
Data Migration and Conversion: Data migration and conversion involve transferring data from one type of database or system to another. Properly defining the database domain ensures a smooth transition of data by mapping the source data to the target databases’ field types, lengths, and constraints. This process ensures the integrity and compatibility of the migrated data.
Defining the Data Type
Defining the data type is an essential component of a database domain. The data type determines the kind of data that can be stored in a field and plays a critical role in maintaining data integrity, optimizing storage space, and improving query performance.
Choosing the appropriate data type is crucial to ensure the accuracy and validity of the stored data. Different data types are available to accommodate various types of information, such as numbers, text, dates, and binary data. Here are some commonly used data types:
- Integer: This data type is used to store whole numbers without decimal places. It is suitable for fields that represent quantities or identifiers.
- Float/Double: Float or double data types are used to store numeric values with decimal places. They are suitable for fields that require precise calculations, such as financial data or measurements.
- String/Character: String or character data types are used to store textual data, such as names, addresses, or descriptions. They have a defined length or can be variable-length.
- Date/Time: Date and time data types are used to store calendar dates or specific time values. They allow for date-based calculations and sorting.
- Boolean: Boolean data type is used to store true/false or yes/no values. It is commonly used for fields that require binary choices.
- Binary: Binary data types are used to store non-textual data, such as images, documents, or multimedia files.
When defining the data type, it is important to choose the most appropriate one based on the nature of the data being stored. This ensures that the database remains efficient and accurately represents the real-world information it is designed to store.
Defining the data type also impacts storage space and query performance. Choosing the most fitting data type helps optimize storage requirements. For example, using an integer data type instead of a string data type to store numeric data can significantly reduce the storage size.
In addition, proper data type selection can improve query performance. By choosing the data type that best represents the data, the database can more efficiently execute queries and perform calculations. For example, using appropriate numeric data types for mathematical operations ensures accurate results and faster computation.
It is essential to define the data type accurately and consistently across the database to maintain data integrity. Inconsistent or incorrect data types can lead to data corruption, calculation errors, or difficulties in data retrieval and analysis.
Overall, defining the data type is a fundamental step in designing a database domain. It ensures the integrity and accuracy of the stored data, optimizes storage space, improves query performance, and facilitates efficient data retrieval and manipulation.
Setting the Field Length
Setting the field length is a critical aspect of defining a database domain. The field length determines the maximum number of characters or digits that a field can accommodate. Properly setting the field length is essential for data integrity, storage optimization, and ensuring the accurate representation of information.
When setting the field length, it is important to consider the expected length of data that will be stored in the field. For example, if the field is intended to store names or addresses, the length should be sufficient to accommodate the maximum expected length of those values. Setting a field length that is too short may lead to data truncation and loss of information, while setting it too long may result in wasted storage space.
The field length should also take into account any potential future changes in the data requirements. Anticipating future expansion needs can help avoid unnecessary modifications and migration efforts. However, it is crucial to strike a balance between future scalability and present storage efficiency.
Setting the field length appropriately impacts data integrity by ensuring that the entered data remains accurate and complete. If the field length is too short for a particular value, it may get truncated, leading to incorrect or incomplete data. This can have cascading effects on the database and any processes that rely on that data.
Furthermore, setting the field length properly can optimize storage space within the database. It helps to determine the minimum amount of storage required for each field, which can lead to substantial storage savings, especially for large databases with millions of records. Efficient storage utilization can also contribute to improved performance by reducing disk I/O and memory consumption.
Another consideration when setting the field length is the potential impact on query performance. Longer field lengths can lead to slower query execution and retrieval times. It is important to strike a balance between accommodating the required data length and maintaining optimal query performance.
Regular database maintenance and monitoring are vital to identify any anomalies related to field length. As data usage patterns change, it may be necessary to reassess and adjust field lengths to ensure continued data integrity and efficient storage utilization.
Creating Validation Rules
Creating validation rules is an essential step in defining a database domain. Validation rules ensure that the data entered into a field meets specific criteria and constraints, promoting data accuracy, consistency, and reliability. By enforcing validation rules, potential errors or inconsistencies in the database can be minimized, improving overall data quality.
When creating validation rules, it is important to consider the specific requirements and standards of the data being stored. These rules can include constraints such as data type, format, range, uniqueness, or relationships with other fields. Here are some common examples of validation rules:
- Required Fields: A validation rule can specify that certain fields must be filled in before a record can be saved. This ensures that essential information is provided and prevents the storage of incomplete or unreliable data.
- Data Type Format: Validation rules can enforce specific formatting requirements for fields. For instance, a rule can mandate that a phone number field should contain only numeric characters or that an email field should have a valid email format.
- Range Validation: Validation rules can define acceptable ranges for numeric or date fields. For example, a rule can enforce that a birthdate must be within a certain range or that a sales value should not exceed a predefined limit.
- Uniqueness: Validation rules can ensure that certain fields or combinations of fields in a table must contain unique values. This is commonly used for primary keys or other unique identifiers to prevent duplicate records.
- Relationship Constraints: Validation rules can define relationships between fields in different tables. For example, a rule can specify that foreign keys in a table must match primary keys in a related table, ensuring data consistency across related records.
Creating validation rules helps maintain data integrity and consistency by preventing the entry of invalid, incorrect, or irrelevant data. This ensures that the data stored in the database accurately reflects the real-world information it represents. Furthermore, validation rules contribute to better data quality and reliability, enabling more accurate reporting and analysis.
Implementing validation rules also enhances the user experience by providing immediate feedback on data entry errors. By validating data as it is entered, users can be alerted to potential mistakes and can correct them promptly. This reduces data entry mistakes and saves time by avoiding the need to manually identify and correct errors later on.
Moreover, validation rules play a crucial role in system security. By validating data integrity and adherence to predefined rules, the risk of malicious data manipulation or injection attacks can be mitigated.
Regular review and maintenance of validation rules are essential to ensure their continued relevance and effectiveness. As data requirements evolve or business processes change, it may be necessary to adjust or add new validation rules to align with updated standards and expectations.
Specifying Field Constraints
Specifying field constraints is a crucial aspect of defining a database domain. Constraints set additional restrictions and conditions on the data stored in a field, ensuring data accuracy, integrity, and consistency. By specifying field constraints, potential data inconsistencies or invalid entries can be prevented, leading to a more reliable and robust database.
There are various types of field constraints that can be applied based on the specific requirements of the data. Some common field constraints include:
- Required Field Constraint: This constraint ensures that a field must have a value before a record can be saved. It prevents the storage of incomplete or missing data, ensuring data accuracy and completeness.
- Unique Field Constraint: Unique field constraints ensure that a specific field or combination of fields must contain unique values within a table. This constraint is commonly used for primary keys or other unique identifiers to prevent duplicate records.
- Default Value Constraint: Default value constraints specify a default value that is automatically assigned to a field if no other value is provided. This constraint helps streamline data entry and ensures that fields have a meaningful default value when not explicitly specified.
- Check Constraint: Check constraints define specific conditions or expressions that the data in a field must meet. It allows for more complex validation beyond the standard data type or range checks. For example, a check constraint might require a postal code field to match a specific pattern.
Specifying constraints at the field level is critical in maintaining data integrity and consistency. These constraints eliminate the need to rely solely on application logic or manual checks to ensure the validity of data. They act as a safety net, preventing data entry errors or inconsistencies at the database level.
Field constraints also play a significant role in database performance. By specifying constraints, the database query optimizer can better optimize query execution plans, resulting in improved query performance. Constraints can also facilitate the use of database indexes, allowing faster data retrieval.
When defining field constraints, it is important to strike a balance between enforcing necessary restrictions and providing flexibility for valid data entry. Overly strict constraints might prevent legitimate data from being entered, while lenient constraints could compromise data quality and integrity.
Regular monitoring and maintenance are essential to ensure that field constraints remain relevant and effective. As data requirements or business rules evolve, it may be necessary to modify or add new constraints to align with changing standards and expectations.
By specifying field constraints effectively, a database can ensure the accuracy, integrity, and reliability of the data it stores, leading to more meaningful insights, reliable reports, and confident decision-making.
Implementing Data Integrity
Implementing data integrity is a critical aspect of database design and maintenance. Data integrity ensures the accuracy, validity, and consistency of data stored within a database. By implementing measures to maintain data integrity, potential errors, inconsistencies, and data corruption can be prevented, resulting in a reliable and trustworthy database.
One of the key aspects of implementing data integrity is the enforcement of data constraints. These constraints can be defined at the field level, table level, or through relationships between tables. They specify rules and conditions that the data must meet to maintain consistency and validity.
Some common forms of data integrity constraints include:
- Entity Integrity Constraint: This constraint ensures that each record in a database table is unique and uniquely identifiable. Typically, this is enforced using primary keys.
- Referential Integrity Constraint: Referential integrity constraints establish relationships between tables and ensure that these relationships are maintained. They enforce the validity of foreign key references and prevent data inconsistencies.
- Domain Integrity Constraint: Domain integrity constraints define rules and restrictions on the values that can be stored in a field. This includes data types, ranges, required values, and validation rules.
- Business Rules Constraint: Business rule constraints are specific rules that align with the business logic and requirements of the organization. They are designed to ensure that data adheres to specific business rules, norms, and policies.
Implementing data integrity also involves implementing mechanisms to detect and handle data anomalies or inconsistencies. These mechanisms can include database triggers, stored procedures, or data validation routines that automatically check and validate data before it is stored or updated in the database.
Another crucial aspect of data integrity is implementing proper data backup and recovery mechanisms. By regularly backing up data and maintaining disaster recovery plans, the risk of permanent data loss due to hardware failure, human error, or natural disasters can be mitigated.
Furthermore, implementing security measures such as access controls and encryption helps protect the integrity of the database by preventing unauthorized access and maintaining data confidentiality and privacy.
Regular monitoring and periodic audits are essential to ensure the continued implementation of data integrity measures. This includes reviewing database logs, analyzing error reports, and conducting data quality checks to identify and resolve potential issues and anomalies.
By implementing and maintaining data integrity measures, a database can maintain the accuracy, validity, and reliability of the information it stores. This not only facilitates effective data analysis and decision-making but also builds trust and confidence in the integrity of the database system.
Defining Relationships
Defining relationships is a key aspect of database design that ensures the organization and integrity of data. Relationships establish connections and dependencies between tables, enabling efficient data retrieval, storage, and maintenance. By defining relationships, data is structured in a logical and meaningful way, promoting data consistency and accuracy.
There are three common types of relationships that can be defined between tables:
- One-to-One (1:1) Relationship: In a one-to-one relationship, each record in one table is associated with only one record in another table. This type of relationship is typically used when two tables share a closely related set of fields or when certain data needs to be separated for organizational purposes.
- One-to-Many (1:N) Relationship: In a one-to-many relationship, a record in one table can be associated with multiple records in another table. This relationship is commonly used when a single record in one table is related to multiple records in another table. For example, a customer may have multiple orders in an e-commerce system.
- Many-to-Many (N:N) Relationship: In a many-to-many relationship, multiple records in one table can be associated with multiple records in another table. This relationship is implemented using an intermediate joining table that contains foreign keys from both related tables. For example, in a student-course registration system, each student can enroll in multiple courses, and each course can have multiple students.
Defining relationships between tables is crucial for maintaining data consistency and integrity. By establishing relationships, redundant data is minimized, and data is stored in a more efficient and organized manner. Updates or modifications to related data are automatically propagated, reducing the risk of data inconsistencies and improving overall data quality.
In addition to defining relationships, it is important to consider the appropriate referential integrity constraints. Referential integrity constraints ensure that the relationships between tables are upheld. These constraints include rules such as foreign key constraints, cascading deletes, and cascading updates that maintain data consistency and prevent orphaned records.
When defining relationships, it is essential to understand the nature and requirements of the data being stored. Analyzing the business processes and data flow helps determine the appropriate relationships and establish the necessary constraints.
Properly documenting and representing relationships through entity-relationship diagrams or schema diagrams is also crucial for effective communication and understanding among database administrators, developers, and stakeholders.
Regular evaluation and adjustment of relationships are necessary as business requirements evolve. Analyzing performance bottlenecks, frequent data retrieval patterns, and future expansion plans helps optimize and modify relationships to ensure efficient data management and retrieval.
By defining relationships in a database, data is organized, related information can be easily accessed, and data integrity is maintained. This promotes efficient data management, facilitates accurate reporting and analysis, and enables the database to support evolving business needs.
Indexing and Query Optimization
Indexing and query optimization are crucial techniques in database management that improve the speed and efficiency of data retrieval and manipulation. By implementing appropriate indexes and optimizing queries, database performance can be significantly enhanced, resulting in faster response times and improved overall system efficiency.
Indexing involves creating data structures, known as indexes, on specific columns or fields in database tables. These indexes allow the database management system to quickly locate relevant data during query execution. Indexes organize data in a way that facilitates efficient searching, sorting, and filtering operations.
Creating indexes on commonly accessed or frequently queried columns can greatly reduce the time required for queries to retrieve the requested information. By providing quicker access to data, indexes significantly improve query performance, especially in large databases with millions of records.
There are different types of indexes based on the data structure used, including B-tree, hash, and bitmap indexes. The selection of the appropriate index type depends on the specific database system, the type of data, and the querying patterns of the application.
Query optimization involves analyzing and rearranging queries to minimize response time and resource usage. The query optimizer, a component of the database management system, determines the most efficient execution plan for a given query. It considers factors such as index usage, join methods, and selectivity estimation to optimize the execution order of operations.
Optimizing queries can involve actions such as reordering joins, rewriting subqueries, or utilizing advanced indexing techniques. These optimizations help eliminate unnecessary computations, reduce disk I/O, and minimize the impact on system resources.
Query optimization is an ongoing process that requires monitoring and tuning as the database and workload evolve. Regularly analyzing query performance, identifying bottlenecks, and adjusting indexing and query structures can further improve system efficiency and response times.
It’s important to note that while indexing and query optimization provide significant performance improvements, they also come with additional storage overhead. Indexes require storage space, and their creation and maintenance may impact the performance of data modification operations such as inserts, updates, and deletes. Therefore, careful consideration should be given to the balance between query performance gains and the associated costs.
Database administrators and developers should have a comprehensive understanding of data access patterns and query requirements to make informed decisions regarding index creation and query optimization. Profiling and testing different index configurations and query structures can help identify the most effective optimizations for specific use cases.
By applying indexing and optimizing queries, databases can achieve faster and more efficient data retrieval, enhancing overall system performance and user experience.
Data Migration and Conversion
Data migration and conversion are crucial processes in database management that involve transferring data from one system or database to another, while ensuring data integrity and compatibility. These processes are often necessary when upgrading systems, changing database vendors, or consolidating data from multiple sources.
Data migration involves transferring data from a source system or database to a target system or database. It includes mapping the structure and format of the source data to the target system’s requirements. Data migration ensures a smooth transition, allowing the new system to efficiently process and utilize the migrated data.
Data conversion is a subtask of data migration that focuses on transforming the data from one format or structure to another. This may involve converting data types, rearranging field values, or reformatting data to align with the target system’s requirements. Data conversion ensures that the migrated data retains its integrity and can be effectively utilized in the new system.
During data migration and conversion, it is essential to consider various factors:
- Data Mapping and Transformation: Mapping the structure and formatting of the source data to the target system is crucial. Field names, data types, lengths, and constraints need to be aligned with the target system’s specifications. Additionally, any necessary transformations, such as changing date formats or scaling numeric values, should be implemented to ensure seamless data migration.
- Data Validation and Verification: As data is migrated and converted, it is vital to validate and verify the accuracy and integrity of the data. This involves performing data quality checks, ensuring referential integrity, and validating against predefined business rules or constraints.
- Data Consistency and Data Privacy: During the migration and conversion process, data consistency should be maintained. Relationships between tables and interdependent data should be preserved to ensure the data remains coherent. Any sensitive or personally identifiable information should be handled securely and in compliance with relevant data privacy regulations.
- Testing and Rollback: Rigorous testing should be conducted before and after the migration and conversion process to identify any issues or discrepancies. It is crucial to have a well-defined rollback plan that can revert the changes in case of unexpected problems.
- Data Transfer and Performance: Consideration should be given to the data transfer mechanisms and the overall performance impact of the migration and conversion process. Optimal methods for data transfer, such as bulk loading or using data integration tools, should be employed to minimize downtime and ensure efficient data transfer.
Expertise in database systems and data migration tools is vital for successful data migration and conversion. Developing detailed migration plans, documenting data mapping and conversion rules, and conducting thorough testing are all essential to ensure a smooth and accurate migration process.
Regular backups of data before and after migration are also recommended to ensure data availability and to mitigate any potential data loss during the migration and conversion process.
By effectively managing data migration and conversion, organizations can seamlessly transition to new systems or consolidate data while maintaining data integrity, consistency, and compatibility.