
What is Multivalued Dependency?
Multivalued dependency is a concept in the field of databases that deals with the relationship between attributes in a table. It occurs when there is a dependency between two sets of attributes, where one set determines multiple values of another set. In simpler terms, it identifies a situation where an attribute or a group of attributes can have multiple values for a single value of another attribute or set of attributes.
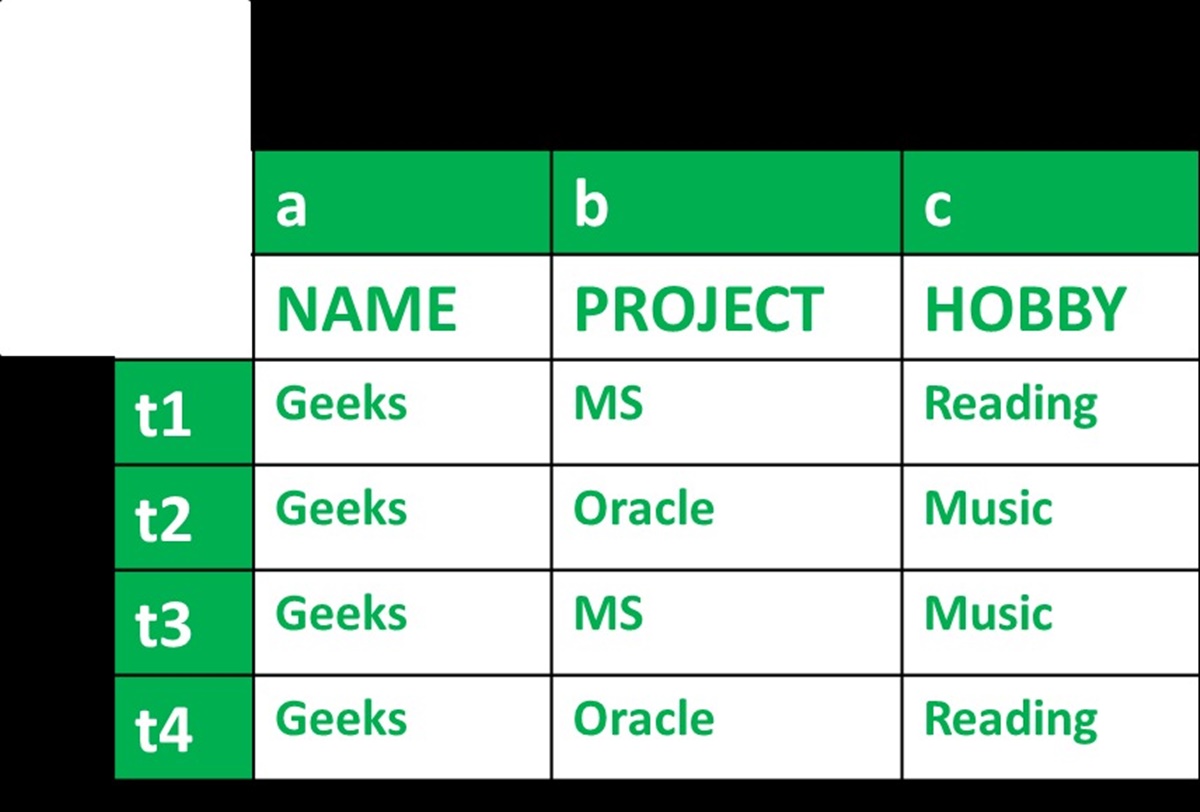
To better understand multivalued dependency, let’s consider an example. Suppose we have a table called “Employees” with attributes such as EmployeeID, FirstName, LastName, and Skills. In this scenario, the Skills attribute can have multiple values for a single combination of FirstName and LastName.
For instance, let’s say we have an employee named John Smith who possesses skills in both programming and graphic design. The multivalued dependency exists because a single combination of FirstName (John) and LastName (Smith) can have multiple values in the Skills attribute (programming, graphic design).
To represent this multivalued dependency, we can write it as:
EmployeeID → → FirstName, LastName → → Skills
Where the double arrow symbol ( → → ) signifies multivalued dependency.
Multivalued dependencies are important in database design, as they help maintain the integrity and consistency of data. They provide insights into the relationships between attributes and assist in database normalization, which ensures efficient storage and retrieval of data.
Understanding multivalued dependency can aid in identifying potential issues with data redundancy and anomalies. By properly addressing and normalizing data affected by multivalued dependency, we can create well-structured and efficient databases.
Example of Multivalued Dependency
To illustrate the concept of multivalued dependency, let’s consider a practical example involving a table called “Employees” with attributes like EmployeeID, FirstName, LastName, and Skills.
Suppose we have the following data in the Employees table:
- EmployeeID: 1
- FirstName: John
- LastName: Smith
- Skills: Programming, Graphic Design
- EmployeeID: 2
- FirstName: Sarah
- LastName: Johnson
- Skills: Database Management, Communication
In this scenario, we can observe a multivalued dependency between the FirstName and LastName attributes, which determine the multiple values in the Skills attribute. The values in the Skills attribute are not directly dependent on the EmployeeID attribute but are associated with specific combinations of First Name and Last Name.
This means that for a given combination of FirstName (John) and LastName (Smith), there can be multiple values in the Skills attribute (Programming, Graphic Design).
Similarly, for a different combination, such as FirstName (Sarah) and LastName (Johnson), the Skills attribute can have another set of multiple values (Database Management, Communication).
This example demonstrates how multivalued dependency occurs when one set of attributes determines multiple values in another set. It highlights the need to identify and handle such dependencies correctly in database design and normalization processes.
By recognizing and addressing multivalued dependencies, we can ensure that the database structure is optimized, avoiding data redundancy and maintaining data integrity.
Functional Dependency vs Multivalued Dependency
In the field of database design, understanding the difference between functional dependency and multivalued dependency is crucial. Both concepts deal with the relationships between attributes, but they have distinct characteristics and implications.
Functional dependency is a fundamental concept in database management. It occurs when the value of one or more attributes uniquely determines the value of another attribute in a table. In other words, given a set of values for one attribute, there is a unique set of values for another attribute. This dependency is represented as A → B, where A determines B.
On the other hand, multivalued dependency arises when there is a dependency between two sets of attributes, where one set determines multiple values of another set. This means that for a given combination of attribute values, there can be multiple values associated with another set of attributes. It is denoted as A → → B, indicating that A determines multiple values of B.
The key difference between functional dependency and multivalued dependency lies in the cardinality of the dependency. In functional dependency, the dependency is one-to-one, meaning that for every value in attribute A, there is a unique value in attribute B.
On the other hand, multivalued dependency involves a one-to-many relationship, where for a given combination of attribute values, there can be multiple associated values in another set of attributes. This allows for more flexibility and complexity in the relationships between attributes.
Functional dependencies are vital in the process of database normalization, as they help eliminate data redundancy and anomalies, ensuring data integrity. They enable database designers to break down tables into smaller, well-structured entities.
Multivalued dependencies, on the other hand, play a significant role in database normalization beyond the third normal form (3NF). They help identify and address situations where an attribute or group of attributes can have multiple values for a single combination of attribute values.
Understanding the distinction between functional dependency and multivalued dependency allows database designers to make informed decisions when structuring and normalizing databases. By recognizing the nature of the dependencies, they can create efficient and well-organized database structures that promote data integrity and optimize data retrieval.
Properties of Multivalued Dependency
When working with multivalued dependency in databases, it is important to understand its properties. These properties provide insights into the behavior and implications of multivalued dependencies and help in analyzing and normalizing database structures.
Here are some key properties of multivalued dependency:
- Reflexivity: A multivalued dependency is reflexive if the set of attributes on the left side of the dependency includes the set of attributes on the right side. In other words, A → → A is a reflexive multivalued dependency. For example, if the Skills attribute is determined by the combination of FirstName and LastName, it logically follows that FirstName and LastName together also determine the Skills attribute. This property ensures self-consistency in the relationship between attributes.
- Augmentation: The augmentation property states that if a multivalued dependency A → → B holds, then adding additional attributes to either A or B does not affect the dependency. For instance, if FirstName and LastName determine multiple values of Skills, adding more attributes to FirstName or LastName will not change the multivalued dependency relationship. This property guarantees the robustness of the dependency.
- Transitivity: Transitivity refers to the property that if A → → B and B → → C hold, then A → → C also holds. In the context of multivalued dependency, if one set of attributes determines multiple values of another set, and that set determines multiple values of a third set, then the first set indirectly determines multiple values of the third set. This property allows for the cascade of dependencies and helps in analyzing complex relationships between attributes.
- Intersection: The intersection property states that if A → → B and A → → C hold, then A → → B ∩ C also holds, where ∩ denotes the intersection of two sets. In simpler terms, if one set of attributes determines multiple values of another set, and another set determines multiple values of a different set, then the intersection of the two sets will also have multivalued dependency. This property aids in understanding the interplay between different dependencies.
These properties of multivalued dependency provide a solid foundation for analyzing and manipulating relationships between attributes in a database. By leveraging these properties, a database designer can ensure data consistency, eliminate redundancy, and achieve a well-normalized database structure.
Closure of Multivalued Dependency
In the realm of database design, the concept of closure plays a crucial role in understanding and analyzing multivalued dependency. The closure of a multivalued dependency refers to the complete set of all dependencies that can be derived from the original dependency, including indirect dependencies.
When working with multivalued dependencies, it is essential to determine the closure to explore all possible dependency relationships accurately. The closure helps identify the complete set of attributes on the left side of the multivalued dependency that determines all possible values on the right side.
Here is an example to illustrate the concept of closure:
Let’s consider a multivalued dependency A → → B, where A and B are sets of attributes. To find the closure of this dependency, we need to consider all possible combinations of A and iteratively determine their dependencies using the augmentation and transitivity properties.
For instance, if we have A1 → → B1 and B1 → → B2, we can apply the transitivity property to derive A1 → → B2. Similarly, if we have A2 → → B2 and B2 → → B3, we can use the transitivity property again to obtain A2 → → B3.
By repeatedly applying the augmentation and transitivity properties, we can identify all the attributes on the left side of the dependency that determine the values on the right side. This set of attributes constitutes the closure of the multivalued dependency.
Understanding the closure of a multivalued dependency is fundamental in the process of normalization. By identifying the closure, we can decompose the original table into smaller, well-structured entities. This decomposition helps eliminate data redundancy, maintain data integrity, and optimize the database’s performance.
Armstrong’s Axioms for Multivalued Dependency
Armstrong’s Axioms provide a set of rules or principles that can be used to derive and prove various functional and multivalued dependencies. These axioms form the foundation for dependency theory in the field of database management and normalization.
There are three main axioms proposed by Armstrong that are specifically applicable to multivalued dependencies:
- Reflexivity: According to the reflexivity axiom, if a set of attributes X is a subset of another set of attributes Y, then Y → → X holds. In other words, any set of attributes is multivalued dependent on itself. This axiom ensures self-consistency in multivalued dependency relationships.
- Augmentation: The augmentation axiom states that if A → → B holds, then AY → → BY also holds, where X and Y are sets of attributes and Y is a subset of X. This means that adding more attributes to the left-hand side of a multivalued dependency does not affect the dependency relationship. The augmentation axiom guarantees that dependency relationships remain unchanged when additional attributes are considered.
- Transitivity: The transitivity axiom states that if A → → B and B → → C hold, then A → → C also holds. This axiom allows for the derivation of new multivalued dependencies by combining and extending existing ones. It enables the analysis and inference of complex multivalued dependency relationships by cascading dependencies.
These axioms can be used to derive and validate the correctness of multivalued dependencies in a database. By applying these axioms, database designers can ensure the integrity and consistency of data and make informed decisions regarding database structure and normalization.
Armstrong’s Axioms provide a solid theoretical framework for understanding and manipulating dependencies in databases. They are fundamental in the process of database design and normalization, helping in the elimination of data redundancy, preservation of data integrity, and optimization of database performance.
Multivalued Dependency Preservation
When performing operations such as decomposition or restructuring of a database, it is essential to ensure the preservation of multivalued dependencies. Multivalued dependency preservation refers to the property of preserving the original multivalued dependencies when transforming or splitting a table into multiple smaller tables.
The preservation of multivalued dependencies is crucial because it helps maintain data integrity and consistency. If a multivalued dependency is lost during the decomposition process, it can lead to data anomalies and inconsistencies, resulting in a loss of data reliability.
To preserve multivalued dependencies, it is important to follow certain guidelines and techniques:
- Dependency Analysis: Before performing any decomposition or restructuring, thoroughly analyze the existing multivalued dependencies in the table. Identify all the multivalued dependencies and understand their significance in preserving data integrity.
- Canonical Cover: The canonical cover is the minimal set of dependencies that is equivalent to the original set of dependencies. By obtaining the canonical cover, you can ensure that you have the essential dependencies to preserve during the decomposition process.
- Decomposition Algorithms: Use decomposition algorithms that specifically target multivalued dependency preservation, such as the Fourth Normal Form (4NF) decomposition algorithm. These algorithms aim to maintain multivalued dependencies while breaking down the original table into smaller, well-structured entities.
- Dependency Checking: After the decomposition, perform dependency checking to ensure that the preserved multivalued dependencies still hold. This involves verifying that the original dependencies and any derived dependencies from the decomposition are still valid in the newly created tables.
- Data Integration: If multiple tables are created during the decomposition, consider how the data will be integrated and reconstructed when querying the database. Plan for appropriate join conditions and relationships between the tables to ensure the retrieval of accurate and consistent results.
By following these approaches, you can mitigate the risk of losing multivalued dependencies during database restructuring. Preserving multivalued dependencies helps maintain data consistency, eliminate data redundancy, and ensure the accuracy and reliability of query results.
Decomposition and Normalization using Multivalued Dependency
In database design, decomposition is the process of breaking down a single table into multiple smaller tables to eliminate data redundancy and achieve a normalized database structure. Multivalued dependency plays a crucial role in the decomposition and normalization process, particularly beyond the third normal form (3NF).
When applying decomposition and normalization using multivalued dependency, the following steps are typically followed:
- Identify the multivalued dependencies: Analyze the existing table and identify all the multivalued dependencies that exist. These dependencies represent the relationships between sets of attributes where one set determines multiple values of another set.
- Create new tables based on dependencies: Based on the identified multivalued dependencies, create new tables to represent each dependency. Each table should contain a key attribute and the attributes determined by the dependency.
- Preserve required functional dependencies: Ensure that any functional dependencies that exist in the original table are preserved in the new tables. Functional dependencies are essential for maintaining data integrity and consistency.
- Eliminate redundant attributes: Remove any redundant attributes from the new tables. Redundant attributes are those that can be derived from other attributes in the table. This helps in reducing data redundancy and improving data storage efficiency.
- Establish relationships between tables: Establish appropriate relationships between the new tables using keys and foreign key constraints to maintain data consistency and enable proper data retrieval.
The decomposition and normalization process using multivalued dependency helps in achieving higher levels of database normalization, such as the Fourth Normal Form (4NF) and beyond. By breaking down the original table into smaller, well-structured entities, redundancy is eliminated, and data integrity is maintained.
However, it is crucial to ensure that the decomposition and normalization process does not result in the loss of any essential multivalued dependencies. Careful analysis and validation should be performed to ensure that the dependencies are preserved during the decomposition process.
Overall, utilizing multivalued dependency in the decomposition and normalization process helps create a well-structured and efficient database that minimizes redundancy and maintains data integrity.
Lossless Join Decomposition using Multivalued Dependency
Lossless join decomposition is a crucial aspect of database design that ensures the integrity of data during the decomposition process. When applying lossless join decomposition using multivalued dependency, the goal is to break down a table into smaller tables while preserving the ability to reconstruct the original table through a join operation without losing any information.
The following steps outline the process of achieving lossless join decomposition using multivalued dependency:
- Identify the multivalued dependencies: Analyze the original table and identify all the multivalued dependencies present. These dependencies define the relationships between sets of attributes where one set determines multiple values of another set.
- Create new tables based on dependencies: Based on the multivalued dependencies identified, create new tables to represent each dependency. Each table should contain a key attribute and the attributes determined by the dependency.
- Ensure no loss of information: Verify that the decomposition does not result in any loss of information. This can be done by performing the natural join operation on the new tables and comparing the result with the original table’s contents. If the result matches, then the decomposition is lossless.
- Establish relationships between tables: Establish appropriate relationships between the new tables using primary key and foreign key constraints to maintain data consistency and enable proper data retrieval.
The goal of lossless join decomposition using multivalued dependency is to ensure that no data is lost during the decomposition process. By establishing relationships and reconstructing the original table through the join operation, the database remains intact and the original information can be replicated.
It is crucial to note that while lossless join decomposition preserves data integrity, it may still introduce redundancy in the form of joined attributes. To address this, additional normalization techniques, such as normalization beyond the Third Normal Form (3NF), can be applied to eliminate redundancy while maintaining lossless join decomposition.
By carefully decomposing the original table based on multivalued dependencies, the lossless join property is maintained, ensuring the preservation of data and enabling efficient data retrieval and manipulation in the normalized database structure.
Fourth Normal Form (4NF) and Multivalued Dependency
The Fourth Normal Form (4NF) is an extension of the normalization process in database design that addresses the issue of multivalued dependencies. 4NF aims to eliminate redundancy and dependency anomalies that arise from the presence of multivalued dependencies in a table.
A multivalued dependency occurs when a set of attributes determines multiple values of another set of attributes. When a table contains such dependencies, it can lead to data redundancy and update anomalies. These anomalies arise when modifications are made to one set of attributes, resulting in inconsistencies in the other set.
4NF addresses multivalued dependencies by requiring that all non-key attributes of a table are functionally dependent on the table’s primary key. In other words, for a table to adhere to 4NF, any attributes that are not part of the primary key must be dependent only on the primary key and not on other non-key attributes.
By decomposing a table into smaller, well-structured entities, 4NF helps eliminate redundancy and preserve data integrity in the presence of multivalued dependencies. This decomposition is achieved by identifying the primary key and creating separate tables to represent the multivalued dependencies.
For example, let’s consider a table called “Employees” with attributes EmployeeID, FirstName, LastName, and Skills. If the Skills attribute is multivalued dependent on the combination of FirstName and LastName, adhering to 4NF would involve creating a separate table for Skills that includes EmployeeID as the primary key and the corresponding skills for each employee.
By separating the attributes with multivalued dependencies into their own tables, we eliminate redundancy and ensure that modifications to one set of attributes do not affect the other sets. This improves data consistency and simplifies database maintenance and updating processes.
It’s important to note that achieving 4NF is a more advanced level of normalization beyond the Third Normal Form (3NF). 4NF helps resolve the data anomalies that can arise from multivalued dependencies, ensuring a well-structured, efficient, and normalized database design.