
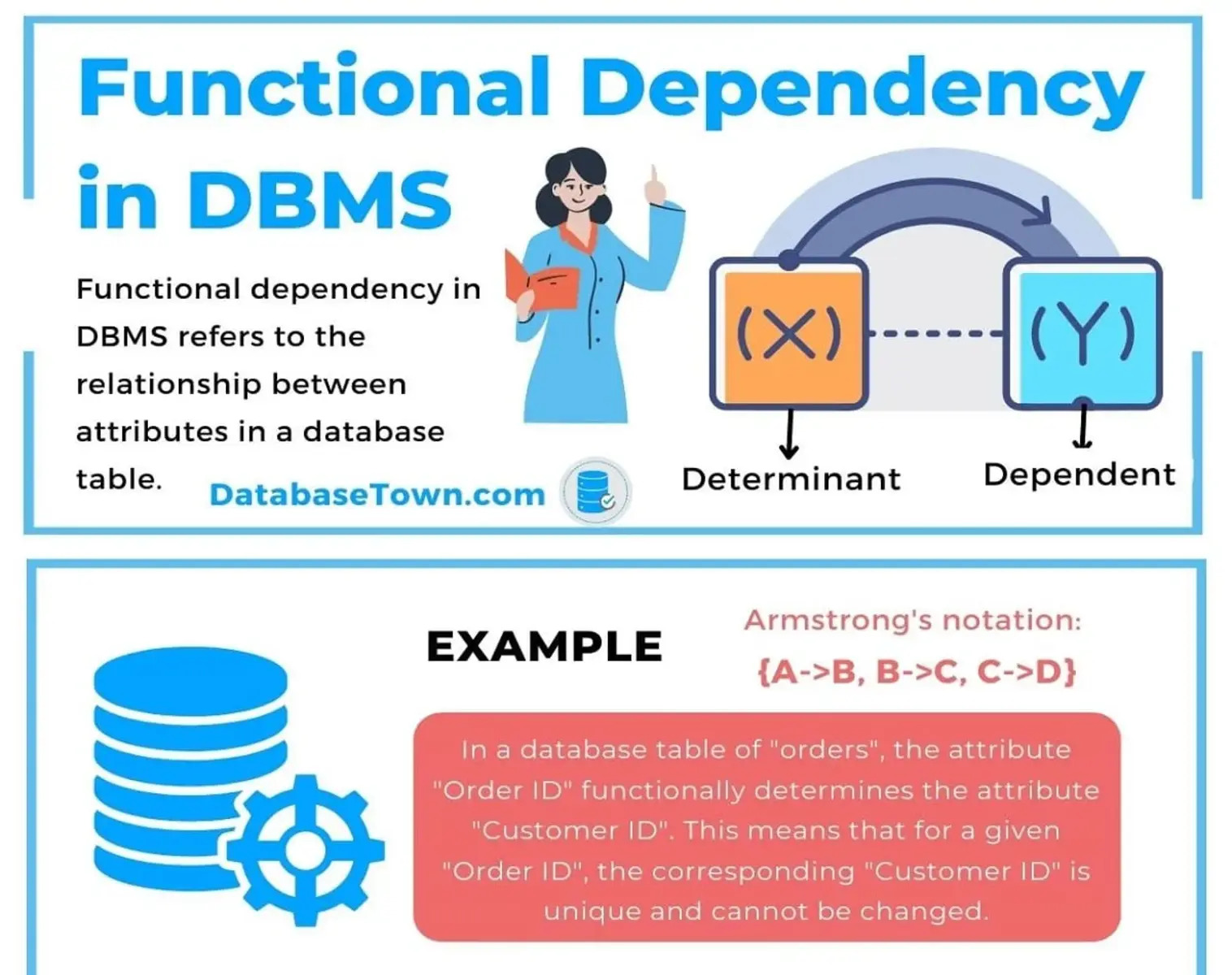
What is Functional Dependency?
Functional Dependency is a fundamental concept in databases that describes the relationship between attributes or columns in a table. It helps to define the dependencies and associations between different attributes in a database schema. In simple terms, it states that the value of one attribute determines the value of another attribute in a table.
Functional dependency is based on the idea that each attribute in a table should be uniquely identified by its key attribute(s). This means that the value of a non-key attribute is dependent on the value of the key attribute(s) in the same table. For example, in a table that stores customer information, the customer ID can be considered the key attribute. The customer’s name, address, and phone number are dependent on the customer ID, as each customer ID uniquely identifies the corresponding information.
Functional dependency is denoted using the arrow notation (->). Let’s say we have two attributes, A and B, in a table. If the value of attribute A determines the value of attribute B, we represent it as A -> B. This means that for each value of A, there is only one corresponding value of B.
It’s important to understand that functional dependency is not limited to just two attributes. It can involve multiple attributes as well. For example, if A determines B, and B determines C, we can represent it as A -> B -> C. This means that the value of attribute C depends on both attributes A and B.
Functional dependencies play a crucial role in database normalization. By identifying and defining functional dependencies, we can eliminate redundant and inconsistent data in the database and ensure data integrity. Normalization helps in organizing data efficiently and reduces data redundancy, making the database more flexible and maintainable.
Purpose of Functional Dependency
The purpose of functional dependency in the context of database design is to provide a clear understanding of how attributes in a table relate to each other. By defining functional dependencies, we can determine the dependencies and associations between different attributes, which helps in maintaining data integrity and optimizing database performance.
One of the primary purposes of functional dependency is to aid in database normalization. Normalization is a process of organizing data in a database to minimize redundancy and inconsistency. By identifying functional dependencies, we can ensure that data is stored in a non-redundant and consistent manner, which leads to more efficient querying and reduces the chances of data anomalies.
Another purpose of functional dependency is to provide guidelines for database design. By understanding the dependencies between attributes, database designers can make informed decisions about table structures, relationships, and keys. This helps in creating efficient and effective databases that meet the requirements of the application.
Functional dependency also helps in data validation and constraint enforcement. By knowing the dependencies between attributes, we can define constraints that ensure the validity of data stored in the database. For example, if attribute A determines attribute B, we can enforce a constraint to prevent any updates that violate this dependency, thus maintaining data consistency.
Additionally, functional dependencies help in data analysis and extraction. By understanding the dependencies between attributes, we can identify patterns and relationships within the data. This can be beneficial for performing data analytics, generating reports, and making data-driven decisions.
The Concept of Keys
In the context of functional dependency, the concept of keys is essential in defining relationships and ensuring data uniqueness in a database. A key is a unique identifier that helps distinguish each record in a table from other records. It is used to establish relationships between tables and maintain data integrity.
There are different types of keys in database design, including primary keys, candidate keys, and foreign keys. The primary key is a unique identifier for each record in a table and is chosen from the candidate keys. A candidate key is a set of attributes that can uniquely identify a record in a table. It could be a single attribute or a combination of multiple attributes. The primary key is selected from the candidate keys based on factors such as uniqueness, simplicity, and stability.
The primary key plays a crucial role in defining functional dependencies. It serves as the determinant for other attributes in the table, meaning that the value of the primary key determines the value of other attributes. For example, in a table that stores employee information, the employee ID could be the primary key. The employee’s name, address, and salary are all dependent on the employee ID. By defining this functional dependency, we ensure that each attribute is uniquely determined by the primary key.
Foreign keys, on the other hand, establish relationships between tables. They reference the primary key of another table and are used to enforce data integrity and maintain referential integrity. By defining a foreign key constraint, we ensure that any values in the referencing table match the values in the referenced table’s primary key.
Keys, especially primary keys, are crucial for indexing and searching data efficiently. They help in optimizing database performance by providing a basis for creating indexes, which allow for quick access and retrieval of data based on the key values.
Determinants and Dependents
In the realm of functional dependency, the terms “determinant” and “dependent” are significant in understanding the relationships between attributes in a database table. The determinant is the attribute or set of attributes that determine the value of one or more other attributes, known as the dependents.
The determinant is the attribute(s) upon which the value of another attribute is entirely dependent. It acts as the “cause” or “driver” for the dependent attribute(s). For example, in a table that stores student information, the student ID could be a determinant for attributes such as student name, address, and phone number. The value of these dependents is entirely determined by the student ID. This is represented as Student ID -> Student Name, Student ID -> Address, and Student ID -> Phone Number.
Determinants can be a single attribute or a combination of multiple attributes. When multiple attributes are combined to form a determinant, it is often referred to as a composite determinant. Continuing with the student example, we might have a composite determinant of Student ID + Course Code -> Grade. This means that both the student ID and the course code together determine the grade obtained by the student in that particular course.
Dependents, on the other hand, are the attributes whose values are determined by the determinant. They rely on the value of the determinant to exist. As illustrated in the previous examples, attributes like student name, address, phone number, and grade are all dependents, as their values are dependent on the respective determinants.
Understanding determinants and dependents is crucial for identifying functional dependencies and normalizing databases. By identifying the determinants and dependents, we can establish the dependencies between attributes and ensure that data is stored in a consistent and non-redundant manner. This ensures data integrity and enables efficient querying and manipulation of data.
Types of Functional Dependencies
In the realm of functional dependency, there are various types that encompass different relationships between attributes in a database table. Understanding these types is crucial for effectively analyzing and organizing data. Here are some common types of functional dependencies:
- Full Functional Dependency: A full functional dependency occurs when an attribute is functionally dependent on the entire combination of attributes in a composite determinant. In other words, removing any attribute from the determinant will break the dependency. For example, if we have A and B as attributes, and A -> B, where A is a composite determinant, then this is a full functional dependency.
- Partial Functional Dependency: As the name suggests, a partial functional dependency occurs when an attribute is functionally dependent on only a part of the composite determinant. Unlike a full functional dependency, removing other attributes from the determinant will not break the dependency. For instance, if we have A, B, and C as attributes, and A + B -> C, then C being dependent on A alone is a partial functional dependency.
- Transitive Dependency: A transitive dependency occurs when an attribute is determined by another attribute through a chain of dependencies. In simple terms, it is an indirect dependency. For example, if we have A -> B and B -> C, then we have a transitive dependency of A -> C. In this case, C is dependent on A indirectly through B.
- Multivalued Dependency: A multivalued dependency occurs when attributes are mutually independent of each other, meaning that the presence or absence of one attribute does not affect the existence of others. This type of dependency is commonly seen between attributes that represent sets of values. For example, if we have A and B as attributes, and A determines a set of values for B, then we have a multivalued dependency.
- Trivial and Non-Trivial Dependency: Functional dependencies can be categorized as either trivial or non-trivial. A trivial dependency occurs when the dependent attribute(s) are also part of the determinant. It is considered trivial because it merely states that the value of an attribute determines itself. On the other hand, a non-trivial dependency occurs when the dependent attribute(s) are not part of the determinant and provide additional information.
Understanding the types of functional dependencies is crucial for database design and normalization. It helps in organizing data efficiently, eliminating redundancies, and ensuring data integrity.
Transitive Dependency
Transitive dependency is a type of relationship that occurs between attributes in a database table. It describes an indirect or chain-like dependency between attributes, where the value of one attribute determines the value of another attribute through a series of intermediate dependencies.
In a transitive dependency, three attributes are involved: A, B, and C. Attribute A determines attribute B, and attribute B determines attribute C. As a result, attribute A indirectly determines attribute C. This can be represented as A -> B -> C.
For example, consider a table that stores information about students, with attributes for student ID, course ID, and course grade. If the student ID determines the course ID, and the course ID determines the grade, then we have a transitive dependency. The student ID indirectly determines the course grade through the intermediate dependency of the course ID.
Transitive dependencies introduce redundancy and can lead to issues in database design and normalization. They violate the principle of data normalization, which aims to eliminate redundancy and ensure data integrity. Redundancy can result in data inconsistencies and anomalies, such as update anomalies and insertion anomalies.
To address transitive dependencies and achieve normalization, the tables need to be appropriately decomposed. This process involves breaking down the tables into smaller, more logically independent tables, to eliminate the transitive dependencies and ensure each table only contains attributes that are directly dependent on the primary key.
By decomposing the table and eliminating transitive dependencies, we can reduce redundancy and improve data integrity. It also simplifies querying and manipulation of the data, as each table represents a distinct and well-defined entity.
Identifying and resolving transitive dependencies is an important step in database design and normalization. It ensures that the database schema is properly structured and optimized for efficient storage, retrieval, and maintenance of data.
Trivial and Non-Trivial Functional Dependencies
In the context of functional dependency, the terms “trivial” and “non-trivial” are used to differentiate between different types of dependencies based on their significance and impact on the database.
A functional dependency is considered trivial when the dependent attribute(s) are also part of the determinant. In other words, the dependency states that the value of an attribute determines itself. For example, if we have an attribute A that determines attribute A, this is a trivial dependency. Trivial dependencies do not provide any additional information or contribute to the understanding of the data.
On the contrary, non-trivial functional dependencies are more meaningful and provide valuable insights into the relationships between attributes. In a non-trivial dependency, the dependent attribute(s) are not part of the determinant and provide additional information. These dependencies reveal dependencies and associations between different attributes that are not immediately apparent.
For instance, let’s consider a table that stores employee information, with attributes for employee ID, name, and department. If we have a functional dependency where the employee ID determines the name, this is a non-trivial dependency. It provides valuable information, indicating that each employee ID uniquely corresponds to a specific name. This dependency helps in ensuring the accuracy and consistency of the data.
Non-trivial dependencies are crucial for data normalization and database design. By identifying and defining these dependencies, we can organize data efficiently and eliminate redundancies, ensuring data integrity and avoiding data anomalies. They help in creating well-structured and meaningful schemas that accurately represent the relationships and dependencies within the data.
Trivial dependencies, on the other hand, do not contribute much to the understanding or organization of the data. They simply state that an attribute determines itself, which does not provide any additional value in terms of data analysis or queries. However, it is important to note that trivial dependencies do not cause any harm or issues in the database. They are simply considered trivial due to their lack of meaningful information.
When working with functional dependencies, it is essential to identify and focus on the non-trivial dependencies that provide valuable insights into the data. By doing so, database designers and administrators can create a well-structured and efficient database that accurately represents the relationships and dependencies within the data.
Importance of Functional Dependency in Database Design
Functional dependency is of utmost importance in database design as it helps in the organization, normalization, and optimization of data. Understanding and defining functional dependencies is crucial for creating efficient and effective databases. Here are some key reasons why functional dependency is important in database design:
Elimination of Redundancy: Functional dependency plays a significant role in eliminating data redundancy. By identifying and defining the dependencies between attributes, we can ensure that each piece of information is stored once and only once in the database. This reduces the chances of inconsistent or conflicting data, making the database more reliable and efficient.
Data Integrity: Functional dependency helps in maintaining data integrity. By determining the relationships between attributes, it ensures that data is stored in a consistent and meaningful manner. This helps in avoiding data anomalies, such as update anomalies and insertion anomalies, which can compromise the accuracy and reliability of data.
Normalization: Functional dependency is closely tied to database normalization. Normalization is a process of organizing data to reduce redundancy and dependency issues. By identifying and resolving functional dependencies, we can break down tables into smaller, well-structured entities, ensuring each table has attributes that are directly dependent on the primary key. This helps in improving efficiency in data storage and manipulation.
Optimized Queries: Defining functional dependencies assists in optimizing database queries. By understanding the relationships between attributes, we can strategically design queries that retrieve the necessary information efficiently. Queries can be optimized by utilizing the dependencies to minimize the need for additional joins or calculations during data retrieval, leading to improved query speed and performance.
Flexible Database Structure: Functional dependency allows for a more flexible database structure. By defining dependencies, we can establish the relationships between tables and attributes, which provides a foundation for creating effective database designs. This flexibility allows for easier modifications, updates, and expansions of the database, adapting to changing business requirements.
Overall, functional dependency is a critical aspect of database design. It helps in organizing data efficiently, reducing redundancy, ensuring data consistency, and optimizing database performance. By understanding and utilizing functional dependency, database designers can create robust and scalable databases that meet the needs of the application and the users.
Functional Dependency in Normalization
Functional dependency forms the foundation of the normalization process in database design. Normalization is a technique used to eliminate data redundancy, minimize data anomalies, and ensure data consistency in a database. Functional dependency plays a central role in achieving these objectives. Here’s how functional dependency is applied during normalization:
First Normal Form (1NF): The first step in the normalization process is to ensure that each attribute in a table contains only atomic values. Functional dependency helps in achieving this by identifying and eliminating multi-valued attributes. By breaking down multi-valued attributes into separate attributes, each attribute becomes dependent on the primary key, establishing a functional dependency.
Second Normal Form (2NF): The second normal form is achieved by eliminating partial dependencies. Partial dependencies occur when a non-key attribute is functionally dependent on only a part of the composite key. Functional dependency helps to identify partial dependencies and break down the table into separate tables, each containing a primary key and its dependent attributes.
Third Normal Form (3NF): The goal of the third normal form is to eliminate transitive dependencies. Transitive dependencies occur when an attribute is dependent on another attribute through a chain of dependencies. Functional dependency helps in identifying and resolving transitive dependencies by decomposing the table into smaller tables, each containing only attributes that are directly dependent on the primary key.
Higher Normal Forms: Functional dependency is important in achieving higher normal forms, such as the Boyce-Codd Normal Form (BCNF) and Fourth Normal Form (4NF). These normal forms focus on ensuring that all functional dependencies are preserved during decomposition, and no redundant dependencies exist. Functional dependency helps in identifying and preserving these dependencies, leading to more refined and efficient database schemas.
By using functional dependency to guide the normalization process, databases can be structured in a more logical and efficient manner. It helps in reducing redundancy, eliminating data anomalies, ensuring data consistency, and optimizing data storage and retrieval operations.
It is important to note that normalization is an iterative process, and the application of functional dependency analysis may vary depending on the specific requirements of the database design and the complexities of the data being stored.
Redundancy and Functional Dependency
Redundancy occurs when the same information is unnecessarily duplicated in a database. It is a common issue that can lead to data inconsistencies and inefficiencies. Functional dependency plays a crucial role in identifying and addressing redundancy within a database. Here’s how functional dependency helps in preventing redundancy:
Elimination of Data Repetition: Functional dependency helps in identifying attributes that are functionally dependent on each other. By understanding these dependencies, we can ensure that attribute values are stored only once and not unnecessarily repeated across multiple records or tables. This eliminates redundancy and reduces the risk of inconsistent or conflicting data.
Minimizing Storage Requirements: Storing redundant data consumes additional storage space. By eliminating redundancy through functional dependency analysis, we can optimize data storage requirements. Storage space can be conserved by storing each attribute value only once, which leads to a more efficient use of disk space.
Preventing Update Anomalies: Redundancy increases the chances of update anomalies, where changes made to one instance of the data may not be reflected in all other instances. This can result in inconsistencies and inaccuracies. Functional dependency helps in identifying the correct place to store data, ensuring that updates are made in one central location and propagate correctly to all dependent attributes.
Ensuring Consistency: Functional dependency helps in maintaining data consistency by ensuring that related attributes are always in sync. By correctly identifying the dependencies between attributes, we can avoid situations where updates to one attribute are not properly reflected in other dependent attributes. This helps to maintain the integrity and accuracy of the data.
Improving Query Performance: Reducing redundancy through functional dependency analysis can improve query performance. With redundant data eliminated, queries can be executed more efficiently as there is less unnecessary data to process. This leads to faster query execution and improved overall database performance.
By utilizing functional dependency analysis, database designers can identify and eliminate redundancy, resulting in a more compact, efficient, and consistent database. This approach not only improves data integrity but also enhances the overall performance of the database system.
Dependency Preservation in Decomposition
Decomposition is a key step in the normalization process, where a table is broken down into smaller tables to eliminate redundancy and achieve higher normal forms. The challenge during decomposition is to ensure that the functional dependencies present in the original table are preserved in the resulting tables. This is known as dependency preservation, and it is essential to maintain the integrity and consistency of the data. Here’s why dependency preservation is crucial during decomposition:
Maintaining Data Integrity: When a table is decomposed, it is important to ensure that the dependencies between attributes are not lost. If a functional dependency exists in the original table, it should continue to hold true in the decomposed tables. This ensures that the data remains consistent and accurate.
Avoiding Redundancy: Dependency preservation helps in avoiding the introduction of redundant data during decomposition. By preserving dependencies, we can identify which attributes need to be included in each decomposed table, and avoid splitting dependent attributes into separate tables. This reduces the chances of data redundancy and associated issues.
Supporting Querying and Join Operations: Preserving dependencies allows for efficient querying and join operations. If the dependencies are preserved during decomposition, it becomes easier to retrieve data that is related across multiple tables. The preserved dependencies serve as a guide for performing joins and retrieving the necessary information efficiently.
Ensuring Consistency: Dependency preservation ensures that changes made to the database are accurately reflected across the decomposed tables. If a dependency is preserved, updates to one attribute will correctly propagate to other attributes that depend on it. This helps in maintaining data integrity and consistency throughout the decomposed structure.
Facilitating Database Maintenance and Evolution: By preserving dependencies, the decomposed database schema remains logically consistent and easier to maintain. If changes or updates need to be made to the database, understanding the preserved dependencies helps in identifying the affected attributes and tables. This allows for efficient database maintenance and evolution over time.
During decomposition, it is crucial to analyze and carefully choose decomposition strategies that preserve the functional dependencies present in the original table. This ensures that the resulting decomposed database maintains the integrity, consistency, and optimal performance of the original schema.