
What is K-Means Clustering?
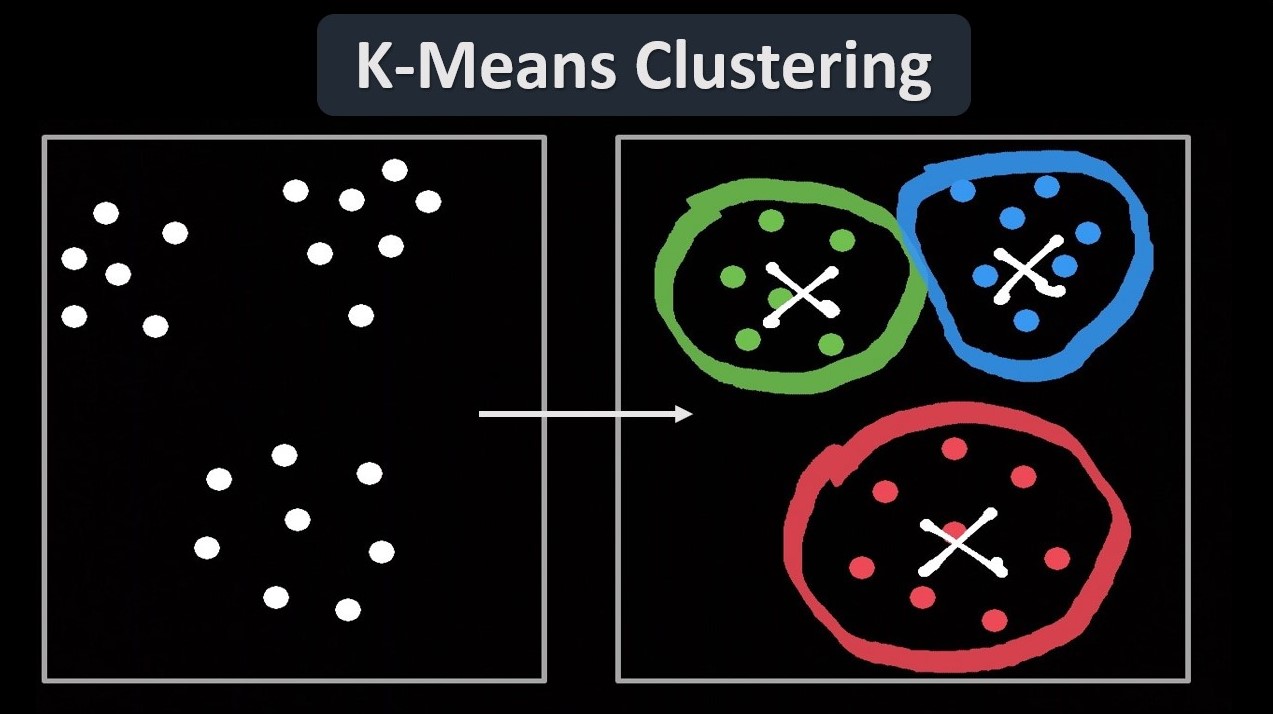
K-Means clustering is a popular unsupervised machine learning algorithm that is used to divide a given dataset into clusters based on similarity. It is a simple yet powerful algorithm that helps in exploring patterns and relationships within data. By grouping similar data points together, K-Means clustering enables us to gain a deeper understanding of the underlying structure of the dataset.
The algorithm is based on the concept of centroids, which are representative points within each cluster. K-Means clustering works by iteratively assigning data points to their nearest centroid and recalculating the centroids based on the newly assigned points. This process continues until convergence, where the centroids no longer change significantly.
One of the defining characteristics of K-Means clustering is that it requires a predetermined number of clusters, also known as K. This means that the analyst must have some prior knowledge or intuition about the expected number of underlying clusters in the dataset.
Once the algorithm has completed, it assigns each data point to one of the K clusters, making it easier to interpret and analyze the data. The goal of K-Means clustering is to minimize the intra-cluster variance, i.e., the distance between data points within a cluster, while maximizing the inter-cluster variance, i.e., the distance between different clusters.
K-Means clustering is widely used in various fields, including data mining, pattern recognition, image analysis, and market segmentation. It helps in identifying natural groupings within the data, enabling businesses to make informed decisions and gain valuable insights.
How Does K-Means Clustering Work?
K-Means clustering follows a straightforward iterative process to group similar data points together. Let’s take a closer look at the steps involved in this algorithm:
- Step 1: Initialization
- Step 2: Assignment
- Step 3: Recalculation
- Step 4: Iteration
- Step 5: Final Clustering
First, we need to select the number of clusters, K, that we want to create. Additionally, K initial centroids are randomly chosen from the dataset.
Each data point is assigned to the nearest centroid based on the distance metric used, such as Euclidean distance. The distance between a data point and each centroid is computed, and the point is assigned to the centroid with the minimum distance.
The centroids are recalculated based on the newly assigned points. The mean of all the data points assigned to each centroid is taken, and that becomes the new centroid.
Steps 2 and 3 are repeated iteratively until convergence. Convergence occurs when the centroids no longer change significantly or when a maximum number of iterations is reached.
Once the algorithm converges, each data point is assigned to a specific cluster based on the final centroids. These clusters represent groups of similar data points within the dataset.
It’s worth noting that the selection of initial centroids can impact the final clustering result. In some cases, the algorithm may converge to a suboptimal solution. To mitigate this, researchers often perform multiple runs of K-Means with different initial centroids and choose the solution with the lowest within-cluster variance.
Overall, K-Means clustering is an iterative process that finds the best representation of clusters within a given dataset, based on minimizing the variance within clusters and maximizing the variance between clusters.
Unsupervised Learning
K-Means clustering falls under the category of unsupervised learning algorithms. Unlike supervised learning, where a model is trained on labeled data to make predictions, unsupervised learning deals with unlabeled data.
In unsupervised learning, the goal is to discover patterns or structures within the data without prior knowledge or guidance. The algorithms are tasked with finding hidden relationships and grouping similar data points together. This makes unsupervised learning particularly useful in exploratory data analysis and understanding complex datasets.
Unsupervised learning is advantageous when the data lacks labeled examples or when the underlying structure of the data is unknown. It allows for identifying clusters, outliers, and anomalies within the dataset. Moreover, unsupervised learning can assist in feature extraction, dimensionality reduction, and data preprocessing tasks.
K-Means clustering is one of the most widely used unsupervised learning algorithms. It does not require any labels or target variables to train the model. Instead, it analyzes the data based on the similarity of data points and groups them into clusters. This can provide valuable insights into the structure and inherent patterns of the dataset.
Other examples of unsupervised learning algorithms include hierarchical clustering, Gaussian mixture models, and self-organizing maps. These algorithms enable data scientists and researchers to uncover hidden patterns, segment customers, identify market trends, and improve decision-making processes.
However, it is important to note that without labels, the evaluation and interpretation of unsupervised learning results can be more challenging compared to supervised learning. Nevertheless, unsupervised learning techniques are powerful tools for data exploration and pattern recognition in various domains.
Clustering Algorithm
Clustering algorithms play a crucial role in unsupervised learning by grouping data points based on their similarities. These algorithms aim to identify natural clusters within a dataset, where data points within the same cluster are more similar to each other than to those in other clusters.
K-Means clustering is one of the popular and widely used clustering algorithms. However, it is important to note that there are other clustering algorithms as well, each with its own characteristics and suitability for different types of data. Some of the commonly used clustering algorithms include:
- Hierarchical Clustering: This algorithm builds clusters in a hierarchical manner, starting from individual data points and gradually merging them together. It can create a tree-like structure called a dendrogram, which provides insights into the hierarchical relationships between data points.
- DBSCAN (Density-Based Spatial Clustering of Applications with Noise): DBSCAN is a density-based clustering algorithm that groups together data points that are close to each other and have a sufficient number of neighboring points. It is effective in identifying clusters of arbitrary shape and handling noisy data.
- Agglomerative Clustering: Agglomerative clustering is a bottom-up approach where each data point is initially treated as a separate cluster. The algorithm then repeatedly merges the closest pairs of clusters until the desired number of clusters is achieved.
- Mean Shift Clustering: Mean Shift clustering is a density-based algorithm that attempts to find the modes or high-density regions of the data points. It iteratively calculates the mean of the data points within a window and shifts the window until it reaches a region with the maximum density.
- Gaussian Mixture Models: Gaussian Mixture Models (GMM) represent each cluster as a multivariate Gaussian distribution. The algorithm estimates the parameters of the Gaussian distributions to fit the data and assigns each data point to the most probable cluster based on the probabilities.
Choosing the most appropriate clustering algorithm depends on various factors, including the nature of the data, the desired number of clusters, the presence of noise or outliers, and the shape and size of the clusters. It is essential to analyze and understand the characteristics of the dataset before deciding on the most suitable clustering algorithm.
Overall, clustering algorithms play a vital role in unsupervised learning by effectively grouping similar data points together and assisting in uncovering the hidden structures within the data.
Distance Metrics
Distance metrics, also known as similarity measures, are essential components of clustering algorithms. They quantify the similarity or dissimilarity between pairs of data points and help determine the proximity of data points in the clustering process. Several distance metrics are commonly used in clustering algorithms, including:
- Euclidean Distance: The Euclidean distance is a widely used distance metric that calculates the straight-line distance between two points in a multidimensional space. It is computed as the square root of the sum of the squared differences of the coordinates.
- Manhattan Distance: The Manhattan distance, also known as the City Block distance or L1 distance, measures the sum of the absolute differences between the coordinates of two points. It calculates the distance as the sum of the horizontal and vertical distances.
- Cosine Similarity: Cosine similarity measures the cosine of the angle between two vectors, representing the directional similarity of the vectors. It considers the magnitude and orientation of the vectors rather than their absolute values.
- Minkowski Distance: The Minkowski distance is a generalized distance metric that encompasses the Euclidean distance and the Manhattan distance as special cases. It is computed as the nth root of the sum of the absolute values raised to the power of n.
- Hamming Distance: The Hamming distance is specifically used for comparing binary data. It calculates the number of positions at which the corresponding bits in two binary vectors differ.
The choice of distance metric depends on the nature of the data and the characteristics of the clustering problem. Euclidean distance is commonly used when dealing with continuous data, while Manhattan distance is preferable when dealing with data represented by coordinates. Cosine similarity is often used for text mining and recommendation systems, while Hamming distance is useful for comparing categorical variables.
It’s important to consider the scale and normalization of the data when using distance metrics. In some cases, preprocessing techniques such as standardization or normalization may be applied to ensure that each feature has a similar impact on the distance calculation.
By selecting an appropriate distance metric, clustering algorithms can effectively measure the similarity or dissimilarity between data points and accurately identify clusters based on the data patterns.
Finding Optimal Clusters
One of the challenges in clustering is determining the optimal number of clusters, especially when the number of clusters is not known in advance. Finding the right number of clusters is crucial for effective interpretation and analysis of the data. Here are a few methods commonly used to estimate the optimal number of clusters:
- Elbow Method: The Elbow method is a heuristic technique that aims to find the number of clusters that best balances the reduction in within-cluster variance with the simplicity of the model. It involves plotting the within-cluster variance against the number of clusters and selecting the number of clusters corresponding to the point where the plot starts to form an elbow-like bend.
- Silhouette Score: The Silhouette score is a measure of how well each data point fits into its assigned cluster. It calculates the average distance between a data point and all other data points within the same cluster (a) and the average distance between the data point and all data points in the nearest neighboring cluster (b). The Silhouette score ranges from -1 to 1, with values close to 1 indicating well-separated clusters.
- Density-based Clustering: Density-based clustering algorithms, such as DBSCAN, do not require a predetermined number of clusters. They identify clusters based on the density of the data points. By varying the density thresholds, one can obtain different numbers of clusters.
- Gap Statistics: Gap Statistics compare the within-cluster dispersion of data points in a given clustering solution to the expected dispersion under a null reference distribution. The optimal number of clusters corresponds to the value for which the gap statistic is significantly larger than the expected dispersion of the null reference distribution.
- Information Criteria: Information criteria, such as the Akaike Information Criterion (AIC) and Bayesian Information Criterion (BIC), provide a quantitative measure of the goodness of fit of a model. These criteria penalize models with higher complexity and help choose the number of clusters that minimizes the information criterion.
It is important to note that these methods provide insights and guidelines for estimating the optimal number of clusters, but they are not definitive. The choice of the number of clusters ultimately depends on the specific dataset and the domain knowledge of the researcher. Additionally, it is worthwhile to compare results obtained from multiple methods to gain a better understanding of the data structure and to make informed decisions.
Through the utilization of these methods, data scientists and researchers can determine the optimal number of clusters for their clustering analysis, ensuring meaningful and accurate clustering results.
Advantages of K-Means Clustering
K-Means clustering offers several advantages that make it a popular choice for data analysis and exploration. Here are some key advantages of using K-Means clustering:
- Simplicity: K-Means clustering is easy to understand and implement. Its simplicity makes it accessible to both beginners and experienced data analysts.
- Efficiency: K-Means clustering is computationally efficient, making it suitable for analyzing large datasets. Its runtime complexity is generally linear with the number of data points, making it scalable.
- Ability to Handle Large Datasets: K-Means clustering can effectively handle datasets with a large number of variables and data points. It is particularly useful when working with high-dimensional datasets where interpreting the data becomes challenging.
- Flexibility: K-Means clustering can be applied to various types of data, including numeric, categorical, and binary data. It is not restricted to any specific type of input or data distribution.
- Interpretability: The clustering results produced by K-Means are easy to interpret. Each data point is assigned to a specific cluster, making it easier to understand the groupings and patterns within the dataset.
- Fast Convergence: K-Means clustering typically converges relatively quickly, especially with proper initialization and stopping criteria. This allows for rapid experimentation and analysis of different configurations.
Moreover, K-Means clustering serves as a foundation for more advanced clustering algorithms and techniques. It provides a fundamental understanding of clustering principles and prepares individuals for exploring and applying other clustering methodologies.
While K-Means clustering offers several advantages, it is important to consider its limitations and potential challenges. It assumes that the clusters are spherical, equally sized, and have similar densities. K-Means is also sensitive to the initial centroid selection and can get stuck in local optima. Therefore, careful data preprocessing, initialization, and evaluation are necessary to obtain meaningful results.
Overall, the simplicity, efficiency, flexibility, and interpretability of K-Means clustering make it a valuable tool for various data analysis tasks, providing insights into the underlying structure and patterns within datasets.
Disadvantages of K-Means Clustering
While K-Means clustering offers numerous advantages, it is important to be aware of its limitations and potential drawbacks. Here are some of the main disadvantages associated with K-Means clustering:
- Sensitivity to Initial Centroid Selection: The choice of initial centroids can significantly impact the clustering results. K-Means clustering is sensitive to the initial centroid positions, which may lead to different local optima.
- Dependency on the Number of Clusters: K-Means clustering requires the prior specification of the number of clusters, denoted as K. Selecting the optimal K value can be subjective, and a poor choice may result in suboptimal clustering solutions.
- Assumption of Spherical Clusters and Equal Variances: K-Means clustering assumes that the clusters are spherical, equally sized, and have similar variances. This assumption may not hold in all cases, leading to suboptimal clustering results.
- Difficulty Handling Outliers and Noise: K-Means clustering treats all data points equally and is sensitive to outliers or noisy data. Outliers can significantly impact the positions of the centroids and distort the clustering results.
- Impact of Feature Scaling: K-Means clustering is influenced by feature scaling, as it is based on distance calculations. In scenarios where features have different scales or units, normalization or standardization may be required to ensure fair and meaningful cluster assignments.
- Biased Towards Convex Clusters: K-Means clustering tends to perform well on datasets with convex-shaped clusters. However, when faced with datasets containing non-convex or irregularly shaped clusters, K-Means may fail to accurately capture the underlying structure.
It is important to acknowledge these limitations and consider them when applying K-Means clustering to a given dataset. Researchers and practitioners should carefully evaluate the data and assess the suitability of K-Means clustering for their specific problem domain.
Despite these limitations, K-Means clustering remains a valuable and widely used technique. Researchers have devised various enhancements and variants of K-Means clustering to address some of these issues, such as initialization strategies, kernel-based methods, and model-based clustering algorithms.
By understanding the limitations of K-Means clustering and exploring alternative clustering algorithms, data analysts can overcome specific challenges and obtain more accurate and meaningful clustering results.
Real-World Applications of K-Means Clustering
K-Means clustering has found numerous applications across various industries and domains. Its simplicity, efficiency, and interpretability make it a versatile tool for data analysis and pattern recognition. Here are some real-world applications of K-Means clustering:
- Customer Segmentation: K-Means clustering is widely used for customer segmentation in marketing and e-commerce. By grouping customers based on their purchasing behavior, preferences, or demographics, businesses can tailor marketing strategies, personalize recommendations, and optimize customer experiences.
- Image Compression: K-Means clustering is employed in image compression algorithms. By clustering similar colors together, pixel values are replaced with their corresponding cluster centroids, reducing the amount of storage space required without compromising the perceived image quality.
- Anomaly Detection: K-Means clustering can be used for anomaly detection by identifying data points that do not conform to the majority pattern. Unusual patterns or outliers stand out from the clusters formed by K-Means clustering, helping in detecting fraud, network intrusions, or anomalous behavior in various fields.
- Market Segmentation: K-Means clustering assists in segmenting markets based on customer preferences, behavior, or demographics. This enables businesses to tailor their marketing strategies, create targeted campaigns, and effectively reach specific market segments.
- Recommendation Systems: K-Means clustering plays a crucial role in building recommendation systems. By grouping users or items based on their similarities, personalized recommendations can be provided to users, enhancing user experience and increasing engagement.
- Bioinformatics: K-Means clustering is widely used in bioinformatics for gene expression analysis and protein sequence classification. By clustering genes or proteins based on their expression patterns or structural characteristics, researchers can gain insights into genetic relationships, identify disease markers, and develop targeted therapies.
These are just a few examples of how K-Means clustering is applied in various industries and domains. Its versatility and ability to uncover patterns and similarities within data make it a valuable tool for businesses, researchers, and data analysts.
Furthermore, as more advanced clustering algorithms and techniques continue to emerge, K-Means clustering sets the foundation for exploring and understanding more complex data structures and patterns.