
What Is Clustering?
Clustering is a fundamental concept in machine learning that involves grouping similar data points together based on certain characteristics. It is a technique used to uncover patterns, structures, or relationships in a dataset without any prior knowledge of the data labels or categories. Clustering can be applied to a wide range of fields, including data analysis, pattern recognition, image segmentation, customer segmentation, and more.
In simple terms, clustering aims to divide a dataset into distinct groups, or clusters, so that data points within a cluster are more similar to each other than to those in other clusters. The goal is to maximize intra-cluster similarity and minimize inter-cluster similarity. This enables us to identify groups or clusters of data points that exhibit similar behaviors or properties, providing valuable insights and facilitating further analysis.
To achieve clustering, various algorithms and techniques are employed, each with its own advantages and assumptions. These algorithms analyze the input data and assign each data point to a cluster based on predefined criteria. The clustering process can be influenced by variables such as distance metrics, similarity measures, and the number of clusters to be generated.
Clustering plays a crucial role in unsupervised learning, where the data does not have known target labels. Unlike in supervised learning, where the model is trained on labeled data to make predictions, clustering focuses on exploring the inherent structure within the data and extracting meaningful information.
By clustering data, we can uncover hidden trends or patterns that may not be apparent at first glance. This can help with various tasks such as customer segmentation for targeted marketing, anomaly detection for fraud prevention, document grouping for information retrieval, and image processing for object recognition, among others.
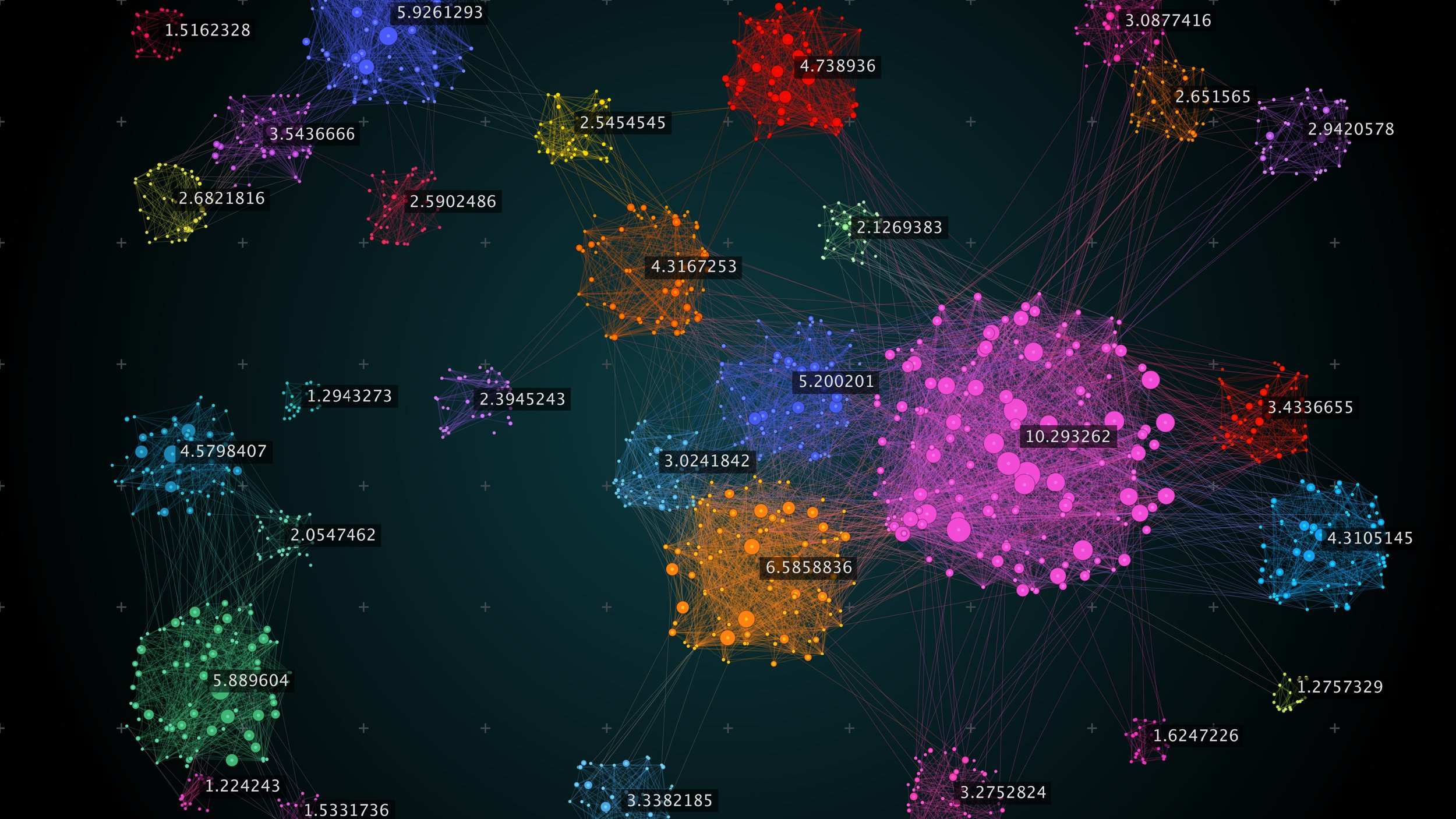
The results of clustering algorithms are often visualized in graphs or plots, where each cluster is represented by different colors, shapes, or symbols. These visual representations make it easier to interpret and analyze the clusters and their relationships.
Overall, clustering is a powerful technique in machine learning that enables data scientists and researchers to gain insights and make data-driven decisions without preconceived notions. It allows us to discover underlying structures within the data and can serve as a foundation for further analysis and modeling.
The Need for Clustering in Machine Learning
Clustering is an essential technique in machine learning due to its ability to identify and group similar data points together. It plays a crucial role in various areas and provides valuable insights that can drive decision-making processes. Let’s explore the reasons why clustering is necessary in machine learning:
Pattern Discovery: Clustering helps in uncovering hidden patterns or structures within a dataset. By grouping similar data points together, we can identify trends, relationships, and correlations that may not be immediately apparent. This can be particularly useful in data analysis, where the ability to detect patterns can lead to more accurate predictions and better understanding of the data.
Data Exploration: Clustering allows us to explore the characteristics and properties of the data in an unsupervised manner. Without any prior knowledge of the data labels or categories, clustering algorithms can reveal clusters that exhibit similar behaviors or attributes. This helps in gaining a deeper understanding of the data and can guide further analysis and modeling tasks.
Segmentation: One of the key applications of clustering is data segmentation. By dividing a dataset into meaningful groups, such as customer segments or market segments, clustering helps in identifying distinct subsets of data with similar characteristics. This segmentation enables businesses to tailor their strategies and offerings to specific target groups, leading to more personalized and effective decision-making.
Anomaly Detection: Clustering can also be used to detect anomalies or outliers within a dataset. By examining the distance or dissimilarity between data points and their assigned clusters, clustering algorithms can identify data points that do not conform to the expected patterns. These anomalies may indicate rare events, outliers, or potential errors in the data, allowing for further investigation and corrective actions.
Feature Engineering: Clustering can be instrumental in feature engineering, which involves the creation of new features or transformations of existing features to improve the performance of machine learning models. By grouping similar data points, clustering can help in identifying relevant features or dimensions that are most influential in differentiating between clusters. This information can guide the selection and engineering of features for improved model accuracy.
Data Visualization: Clustering provides a visual representation of the underlying structure in a dataset. Through plots or graphs, where each cluster is displayed with distinct characteristics, clustering enables easier interpretation and understanding of the data. Visualization can assist in communicating insights to stakeholders and facilitate decision-making processes.
Overall, clustering plays a vital role in machine learning by enabling pattern discovery, data exploration, segmentation, anomaly detection, feature engineering, and data visualization. It helps reveal hidden relationships and provides valuable insights that can enhance decision-making processes and drive business outcomes.
Types of Clustering Algorithms
Clustering algorithms are the backbone of clustering techniques in machine learning. They serve as the foundation for grouping similar data points together. Various clustering algorithms exist, each with its own approach and characteristics. Let’s explore some of the most commonly used types of clustering algorithms:
K-Means Clustering: K-means clustering is one of the most widely used clustering algorithms. It partitions the data into k non-overlapping clusters, where k is pre-defined. The algorithm starts by randomly assigning k centroids and iteratively updates them to minimize the sum of squared distances between data points and their assigned centroids. K-means clustering is efficient, easy to implement, and works well with large datasets. However, it requires specifying the number of clusters beforehand.
DBSCAN: Density-Based Spatial Clustering of Applications with Noise (DBSCAN) is another popular clustering algorithm. It groups data points based on their density within a defined neighborhood. It identifies dense regions as clusters and classifies low-density regions as noise or outliers. DBSCAN is robust to different shapes and sizes of clusters and does not require specifying the number of clusters in advance. It can handle noise in the data and is effective in identifying clusters of varying densities.
Hierarchical Clustering: Hierarchical clustering creates a hierarchy of clusters by iteratively merging or splitting clusters based on their similarity. There are two main approaches to hierarchical clustering: Agglomerative and Divisive. Agglomerative clustering starts with each data point as a separate cluster and merges the most similar clusters until a single cluster is formed. Divisive clustering begins with all data points in a single cluster and recursively divides it into smaller clusters. Hierarchical clustering provides a complete clustering structure, allowing for different levels of granularity.
Gaussian Mixture Models (GMM): GMM assumes that the data points are generated from a mixture of Gaussian distributions. It estimates the parameters of these distributions to fit the data and assigns each data point a probability of belonging to each of the Gaussian distributions. GMM allows for soft assignments, meaning that data points can belong to multiple clusters with varying probabilities. GMM is effective for modeling complex datasets with overlapping clusters.
Other Clustering Algorithms: Apart from the aforementioned algorithms, there are other clustering techniques such as Mean Shift, Spectral Clustering, Affinity Propagation, and more. Mean Shift identifies modes or high-density regions in the data and iteratively adjusts the cluster centers. Spectral Clustering uses the eigenvalues and eigenvectors of the data’s affinity matrix to partition it into clusters. Affinity Propagation models the similarity between data points and iteratively assigns data points as exemplars to represent clusters.
These are just a few examples of clustering algorithms, and there are many more variations and hybrid approaches available. The choice of clustering algorithm depends on the specific characteristics of the dataset, the desired output, computational resources, and the goals of the analysis.
It is important to understand the strengths and limitations of each algorithm before selecting the most appropriate one for a particular clustering task. Experimentation and evaluation of different algorithms are often required to determine the best fit for the data.
K-Means Clustering
K-means clustering is a popular algorithm used for partitioning a dataset into k non-overlapping clusters. It is an iterative algorithm that aims to minimize the sum of squared distances between data points and their assigned cluster centroids. The steps involved in K-means clustering are as follows:
Step 1: Initialization: Randomly select k data points as initial centroids.
Step 2: Assignment: Assign each data point to the cluster with the nearest centroid based on the Euclidean distance or other distance metrics.
Step 3: Update Centroids: Recalculate the centroids by taking the mean of all data points assigned to each cluster.
Step 4: Repeat: Repeat steps 2 and 3 until convergence criteria are met, such as when the centroids no longer move significantly or the maximum number of iterations is reached.
K-means clustering is computationally efficient and can handle large datasets. However, it requires specifying the number of clusters, k, in advance, which can be a challenge in some cases. Choosing an inappropriate value for k can lead to poor clustering results.
The algorithm works by minimizing the within-cluster sum of squared distances, also known as the inertia or distortion. The objective is to create compact, well-separated clusters. The quality of the clustering depends on the initial centroid selection and the convergence criteria.
There are variations of the K-means algorithm that address some of its limitations. One such variation is the K-means++ initialization, which improves the initial centroid selection by ensuring better spread across the dataset. Other variants include Mini-Batch K-means, which uses random subsets of the data to accelerate the convergence, and online K-means, which updates the centroids incrementally as new data arrives.
K-means clustering has a wide range of applications, including image segmentation, document clustering, customer segmentation, and anomaly detection. It provides interpretable results, where each cluster represents a distinct group of data points with similar characteristics. Visualizing the clusters can provide insights into the underlying structure and patterns within the data.
It is important to note that K-means clustering can produce different results depending on the initial centroids and the dataset’s characteristics. It may not work well for datasets with unevenly sized or non-convex clusters. Therefore, it is advisable to preprocess the data, scale the features, and try different values of k to achieve the best clustering performance.
DBSCAN
Density-Based Spatial Clustering of Applications with Noise (DBSCAN) is a popular density-based clustering algorithm. Unlike other algorithms, DBSCAN does not require specifying the number of clusters in advance and can discover clusters of arbitrary shapes. DBSCAN identifies clusters based on the density of data points within a defined neighborhood.
The key idea behind DBSCAN is that dense regions in the data space are considered to be clusters, while sparse regions are classified as noise or outliers. The algorithm defines two important parameters:
Epsilon (ε): Also known as the neighborhood radius, it specifies the maximum distance within which two data points are considered to be neighbors of each other.
Minimum Points (MinPts): It specifies the minimum number of data points required within the ε neighborhood to define a dense region or core point. Points that do not meet this criteria are classified as border points.
The DBSCAN algorithm proceeds as follows:
Step 1: Core Point Selection: For each data point, calculate the number of data points within the ε neighborhood. If this count is greater than or equal to MinPts, mark the point as a core point.
Step 2: Cluster Expansion: For each core point, expand the cluster by iteratively adding reachable data points within the ε neighborhood. A data point is considered reachable if it is a core point or a border point of another core point.
Step 3: Noise Assignment: Assign any data points that are not part of any cluster as noise or outliers.
DBSCAN is effective in identifying clusters of varying densities and can handle datasets with outliers. It does not make any assumptions about the shape or size of the clusters, making it versatile for different types of data. The algorithm is also robust to parameter selection. However, tuning the ε and MinPts parameters can significantly impact the clustering results.
DBSCAN has several advantages over other clustering algorithms. It can handle datasets where clusters have irregular shapes, overlapping regions, or varying densities. It does not rely on global distance thresholds and is resistant to the effects of noise and outliers. DBSCAN is widely used in various fields such as image processing, spatial data analysis, and anomaly detection.
It is important to note that DBSCAN may struggle with datasets that have high dimensionalities or large differences in densities. In such cases, it is recommended to preprocess the data, apply dimensionality reduction techniques, or consider other clustering algorithms tailored to handle specific data characteristics.
Hierarchical Clustering
Hierarchical clustering is a popular clustering algorithm that builds a hierarchy of clusters by iteratively merging or splitting clusters based on their similarity. It does not require specifying the number of clusters in advance and provides a complete clustering structure, allowing for different levels of granularity.
There are two main approaches to hierarchical clustering:
Agglomerative Clustering: Agglomerative clustering starts with each data point as a separate cluster and iteratively merges the most similar clusters until a single cluster is formed. In the beginning, each data point is considered a separate cluster. At each step, the two closest clusters are merged based on a similarity measure, such as distance or linkage criteria (e.g., single linkage, complete linkage, average linkage). This process continues until a single cluster containing all data points is created.
Divisive Clustering: Divisive clustering begins with all data points in a single cluster and recursively divides it into smaller clusters. It starts by considering all data points as one cluster and then splits it into two based on the dissimilarity or distance between points. This process is repeated recursively for each newly formed cluster until a stopping criterion is met, such as reaching a desired number of clusters or a specific level of dissimilarity.
Hierarchical clustering can produce different solutions based on the chosen similarity measure and the linkage criteria. The linkage criteria determine how the distance between two clusters is calculated based on their constituent data points. Commonly used linkage criteria include:
- Single Linkage: Measures the distance between the closest two points in different clusters.
- Complete Linkage: Measures the distance between the furthest two points in different clusters.
- Average Linkage: Measures the average distance between all pairs of points in different clusters.
Hierarchical clustering produces a dendrogram, which is a tree-like diagram that represents the merging or splitting of clusters at different levels. The dendrogram provides a visual representation of the clustering process and allows for the identification of optimal cluster numbers and cutoff points.
Hierarchical clustering is beneficial when the underlying structure of the data is not well-defined or when exploring data at different levels of granularity is desired. It is widely used in various fields, including biology, image analysis, social network analysis, and document clustering. However, hierarchical clustering can be computationally expensive, especially for large datasets, and is sensitive to noise and outliers.
It is essential to choose appropriate linkage criteria and consider the characteristics of the data when applying hierarchical clustering. Understanding the dendrogram and interpreting the results require careful analysis and domain knowledge to extract meaningful insights from the clustering process.
Gaussian Mixture Models
Gaussian Mixture Models (GMM) is a clustering algorithm that assumes the data points are generated from a mixture of Gaussian distributions. It is a probabilistic model that estimates the parameters of these distributions to fit the data and assigns each data point a probability of belonging to each of the Gaussian components.
The key idea behind GMM is to model the underlying density of the data by combining multiple Gaussian distributions. Each Gaussian component represents a cluster, and the mixture coefficients determine the proportion of data points assigned to each component. The algorithm iteratively updates the parameters to maximize the likelihood of the observed data.
GMM allows for soft assignments, meaning that data points can belong to multiple clusters with varying probabilities. This is in contrast to hard assignments in other clustering algorithms, where each data point is assigned to only one cluster.
The steps involved in GMM are as follows:
Step 1: Initialization: Randomly initialize the parameters of the Gaussian components (mean, covariance, and mixture coefficients).
Step 2: Expectation-Maximization (EM) Algorithm: Iterate between the Expectation and Maximization steps until convergence is achieved.
- Expectation Step: Calculate the posterior probabilities for each data point, representing the likelihood of it belonging to each Gaussian component.
- Maximization Step: Update the parameters of the Gaussian components based on the weighted average of the data points, considering their posterior probabilities.
The Expectation-Maximization algorithm continues iterating until the parameters converge or a maximum number of iterations is reached.
GMM is capable of modeling complex datasets with overlapping clusters and capturing the underlying data distribution. It can be used for density estimation, anomaly detection, and generating new samples. GMM is also useful for feature engineering, where the learned probabilities can serve as informative features for subsequent machine learning tasks.
However, GMM has several limitations. It assumes that the clusters are Gaussian shaped, which may not be appropriate for all datasets. It can also struggle with high-dimensional data due to the curse of dimensionality. Estimating the number of Gaussian components can be challenging and has a significant impact on the clustering results.
To mitigate these limitations, techniques such as model selection criteria (e.g., Akaike Information Criterion or Bayesian Information Criterion) or Bayesian approaches can be employed to determine the optimal number of components. Additionally, dimensionality reduction techniques, such as Principal Component Analysis (PCA), can be applied to address the curse of dimensionality and improve the performance of GMM.
GMM is widely used in various domains, including image and speech processing, bioinformatics, and generative modeling, where capturing the underlying distribution of the data is essential.
Evaluating Clustering Results
Evaluating the quality of clustering results is crucial to assess the performance and reliability of clustering algorithms. However, unlike supervised learning tasks, clustering is an unsupervised process, making it challenging to have a definitive ground truth for evaluation. Nevertheless, various evaluation metrics and techniques can provide insights into the effectiveness and validity of clustering results.
Here are some common methods for evaluating clustering results:
External Evaluation: External evaluation measures assess the agreement between the clustering results and externally available class labels or ground truth. These metrics include Adjusted Rand Index (ARI), Normalized Mutual Information (NMI), and Fowlkes-Mallows Index (FMI). Higher values indicate better agreement between the clustering and true labels.
Internal Evaluation: Internal evaluation metrics evaluate the quality of clustering results based solely on the characteristics of the data itself. Silhouette Score, Davies-Bouldin Index (DBI), and Calinski-Harabasz Index (CHI) are commonly used internal evaluation measures. Higher Silhouette Score and CHI, and lower DBI, indicate better clustering quality.
Visual Inspection: Visual inspection involves visually examining the clustering results through scatter plots, dendrograms, or other visualization techniques. It can provide valuable insights into the structure and separation of clusters, helping to assess the clustering quality. Visual inspection can reveal patterns, overlaps, and outliers within the data.
Domain Expertise: Domain experts can provide valuable insights and evaluate the clustering results based on their knowledge and expertise in the specific field. Their insights can help to identify meaningful clusters and determine whether the results align with the expectations and requirements of the domain.
It is important to note that the choice of evaluation method depends on the specific application, dataset, and clustering goals. No single metric can capture all aspects of clustering performance, and a combination of evaluation techniques is often employed for a comprehensive analysis.
Furthermore, evaluating the stability and robustness of the clustering results is essential. Robustness can be assessed through techniques such as cluster stability analysis, bootstrapping, or perturbation analysis. These methods help determine the consistency and reliability of the obtained clusters.
Finally, it is crucial to consider the limitations and assumptions of the evaluation metrics. Some metrics may be sensitive to the number of clusters or subject to bias based on certain data characteristics. Hence, it is recommended to choose appropriate evaluation methods based on the specific requirements and nuances of the clustering task.
Choosing the Right Clustering Algorithm
Choosing the right clustering algorithm is essential to ensure accurate and meaningful results. With various clustering algorithms available, it is crucial to consider the characteristics of the data, the desired outcomes, and the algorithm’s assumptions and limitations. Here are some factors to consider when selecting a clustering algorithm:
Data Characteristics: Understand the nature of the data, such as its dimensionality, size, sparsity, and distribution. Some algorithms may be better suited for handling high-dimensional data, while others may perform well with data of specific distributions or sizes. It is important to assess how well the algorithm can capture the underlying structure and patterns of the data.
Clustering Task: Clearly define the goals and requirements of the clustering task. Are you looking for dense, well-separated clusters or clusters of irregular shapes? Do you need the algorithm to handle noise or outliers? Consider the specific objectives and constraints of the clustering task to choose an algorithm that aligns with those requirements.
Scalability: Evaluate the algorithm’s scalability to handle the size of the dataset. Some algorithms, such as K-means, are known for their efficiency and ability to handle large datasets. However, more complex algorithms, like DBSCAN or hierarchical clustering, may be computationally expensive and less suitable for large-scale data.
Desired Output: Consider the type of output that the algorithm produces. Do you need hard assignments of data points to clusters, or soft assignments with associated probabilities? Determine whether the algorithm’s output aligns with your specific needs and if the results are interpretable and meaningful for your application.
Assumptions and Limitations: Understand the assumptions and limitations of each clustering algorithm. For example, K-means assumes clusters of similar sizes and shapes, while Gaussian Mixture Models assume that the data follows a Gaussian distribution. Be aware of these assumptions and assess the compatibility of the algorithm with your data.
Domain Knowledge: Consider your domain knowledge and expertise in the problem area. Different algorithms may be more suitable for specific domains or applications. Consulting with domain experts can provide insights into the suitability of different algorithms and their applicability to the problem at hand.
Experimental Evaluation: Experiment with different algorithms using a subset of your data. Evaluate their performance and compare the clustering results using appropriate evaluation measures. This empirical investigation will help determine which algorithm works best for your specific dataset and goals.
It may also be beneficial to combine multiple clustering algorithms or use ensemble methods to improve the robustness and accuracy of the results. Some algorithms may work well in conjunction with others, complementing their strengths and mitigating their weaknesses.
Remember that there is no one-size-fits-all clustering algorithm, and the choice of algorithm depends on a variety of factors. Careful consideration of the data, task requirements, and algorithm properties is crucial in selecting the most appropriate clustering algorithm to obtain meaningful and reliable results.
Applications of Clustering in Machine Learning
Clustering is a versatile technique in machine learning that finds application in several domains. It enables the discovery of hidden structures within data and provides valuable insights for various tasks. Here are some common applications of clustering:
Customer Segmentation: Clustering is extensively used in marketing to segment customers into distinct groups based on their behaviors, preferences, purchasing patterns, or demographics. By identifying customer segments, businesses can personalize marketing strategies, targeted promotions, and product recommendations to improve customer satisfaction and increase revenue.
Image Segmentation: Clustering is valuable in image processing to segment images into regions with similar characteristics, such as color, texture, or intensity. This facilitates object recognition, image editing, and computer vision tasks. Cluster-based image segmentation helps in medical imaging, autonomous vehicles, and content-based image retrieval.
Document Clustering: Clustering is employed to organize large document collections, such as news articles, research papers, or customer reviews, into meaningful groups. Document clustering aids in information retrieval, topic modeling, sentiment analysis, and recommendation systems. It enhances search functionality, content categorization, and knowledge discovery.
Anomaly Detection: Clustering helps in identifying anomalies or outliers within a dataset. It can detect data points that deviate significantly from the expected pattern or behavior. Anomaly detection is crucial in fraud detection, network security, predictive maintenance, and fault diagnosis. By isolating unusual data points, clustering assists in detecting and addressing critical irregularities.
Social Network Analysis: Clustering is utilized in social network analysis to identify communities or groups within a network of individuals or entities. This facilitates understanding the structure, relationships, and influence within social networks. Cluster-based analysis aids in targeted marketing, recommendation systems, and understanding the spread of information or opinions in social media.
Genomics and Bioinformatics: Clustering plays a vital role in analyzing genetic data and biological sequences. It helps in gene expression analysis, protein sequence classification, DNA microarray data analysis, and identifying functional groups or pathways. Clustering facilitates identifying disease subtypes, drug discovery, and personalized medicine.
Market Segmentation: Clustering is applied in market research to segment markets based on consumer preferences, buying behaviors, or demographic characteristics. It helps businesses understand target markets, define marketing strategies, and tailor product offerings to specific customer segments. Market segmentation assists in new product development, competitive analysis, and market trend identification.
Pattern Recognition: Clustering aids in uncovering patterns and structures within data for pattern recognition tasks. It is used in speech and handwriting recognition, object detection, anomaly detection in time series data, and pattern matching in data mining. Cluster-based pattern recognition facilitates understanding and predicting complex patterns.
These are just a few examples of the diverse applications of clustering in machine learning. Clustering enables data-driven insights, facilitates decision-making, and supports various tasks across different industries. The versatility and wide range of applications make clustering a valuable technique in the field of machine learning.
Limitations and Challenges in Clustering
While clustering is a powerful technique in machine learning, it is not without limitations and challenges. It is important to be aware of these factors when applying clustering algorithms to ensure accurate and meaningful results. Here are some common limitations and challenges in clustering:
Determining the Number of Clusters: One of the significant challenges in clustering is determining the optimal number of clusters, especially when the ground truth is not available. The choice of the number of clusters can significantly impact the results. Selecting an inappropriate value can lead to poor cluster quality and interpretation.
Defining Cluster Boundaries: Clustering algorithms often assume that clusters have well-defined boundaries. However, in real-world scenarios, clusters may have overlapping regions or irregular shapes, making it challenging to define precise boundaries. This can lead to ambiguity in the cluster assignments and difficulty in accurately separating data points.
Sensitivity to Initialization: Many clustering algorithms, such as K-means, are sensitive to the initial centroid selection. Small changes in the initial centroids can lead to different clustering results. This sensitivity to initialization requires multiple runs of the algorithm with different initializations to ensure stability and consistency in clustering outcomes.
Data Dimensionality: The curse of dimensionality poses a challenge in clustering high-dimensional data. As the number of dimensions increases, the distance between data points becomes less meaningful, making it difficult to identify meaningful clusters. Dimensionality reduction techniques, such as PCA or feature selection, are often employed to address this challenge.
Cluster Validity: Evaluating the quality and validity of clusters is a subjective task. There is no universal definition of a “good” cluster, and the evaluation depends on the specific context and objectives of the clustering task. Different evaluation metrics and criteria can lead to varying interpretations of cluster quality.
Handling Outliers and Noise: Clustering algorithms can be sensitive to outliers and noise in the data. Outliers may disrupt the formation of meaningful clusters or cause clusters to be biased towards the outliers. It is essential to preprocess the data, apply outlier detection techniques, or consider robust clustering algorithms to mitigate the impact of outliers.
Computational Complexity: Some clustering algorithms, such as hierarchical clustering or density-based methods, can be computationally expensive, especially for large datasets. The computational complexity of these algorithms limits their scalability and can be a challenge when working with high-dimensional or streaming data.
Interpretability and Subjectivity: Clustering results are often interpreted and analyzed by domain experts or stakeholders. The interpretation of clusters involves subjective judgment and domain knowledge. Subjectivity can introduce biases and inconsistencies in the analysis, requiring careful interpretation and validation of the clustering results.
It is important to be aware of these limitations and challenges while applying clustering algorithms. Understanding the specific characteristics of the dataset, choosing appropriate evaluation measures, and adopting robust methods can help address these limitations and improve the quality and reliability of the clustering results.