
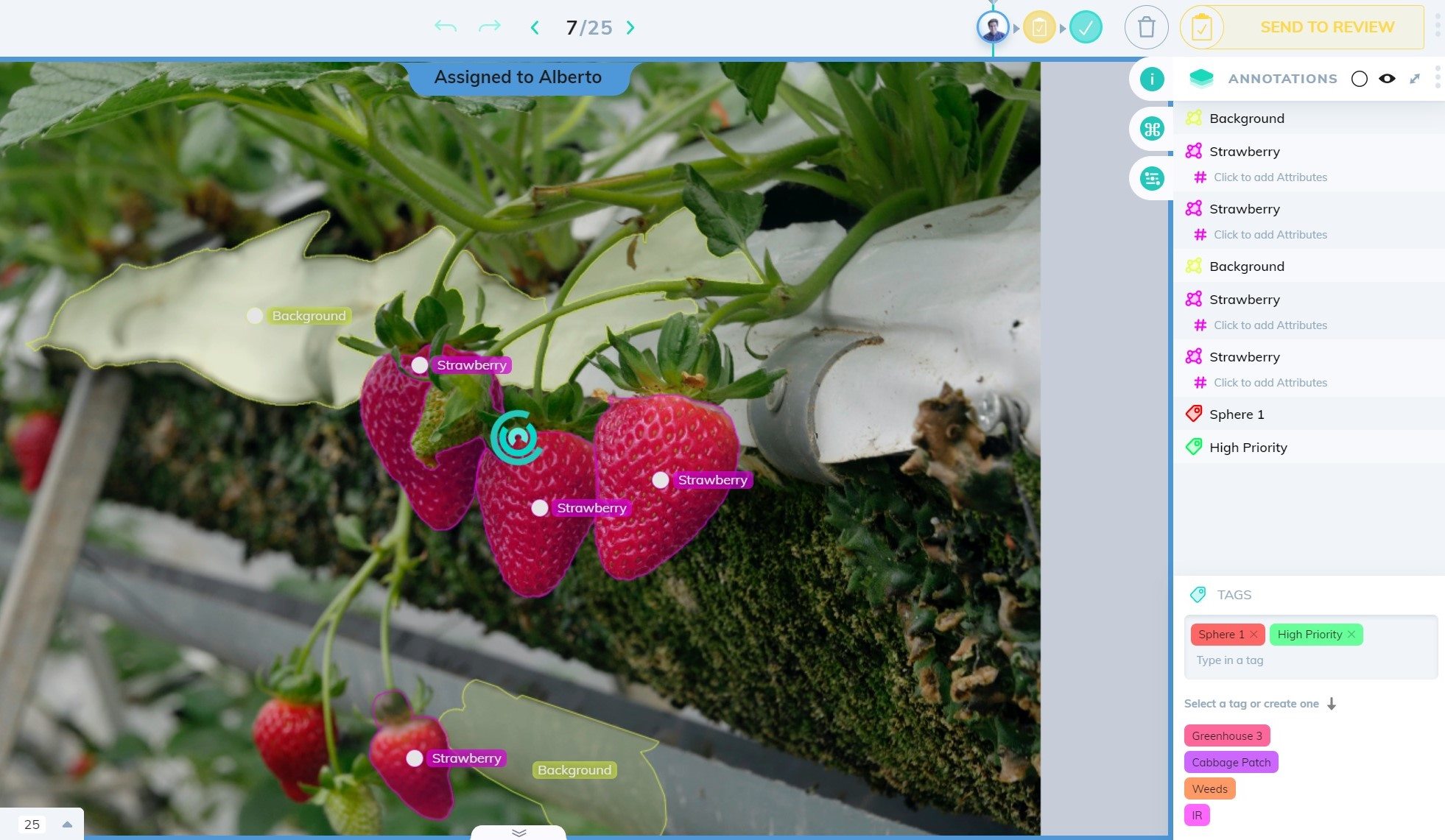
The Importance of Accurate Image Labeling
Image labeling is a critical step in machine learning projects, particularly those involving computer vision. It involves assigning relevant and meaningful labels or annotations to images, enabling algorithms to understand and interpret visual data accurately. Accurate image labeling is vital for several reasons:
Improved Model Performance: Labeling images with precision enhances the performance and effectiveness of machine learning models. By providing accurate annotations, models can identify and classify objects, people, or scenes within images with a higher level of accuracy. This leads to more accurate predictions and better overall model performance.
Data Enrichment: Accurate image labeling adds valuable information to the dataset. Labels provide context and additional insights about the content of the images, enabling models to learn from a more comprehensive and diverse set of data. This enrichment helps models generalize better and improve their ability to recognize different variations of objects or scenes.
Training Set Creation: Image labeling plays a crucial role in creating the training set for machine learning models. A well-labeled dataset is essential for training models to recognize specific patterns, features, or objects. Without accurate labels, the model may fail to learn the desired concepts, resulting in lower performance and unreliable predictions.
Domain-specific Applications: Accurate labeling is particularly important for domain-specific applications. For example, in medical imaging, precise labeling is necessary to identify specific anatomical structures or abnormalities. In autonomous driving, accurately labeled images help models detect road signs, pedestrians, and other vehicles, ensuring safe and efficient navigation.
High-quality Datasets: Accurate image labeling contributes to the creation of high-quality datasets, which are crucial for the success of machine learning projects. Well-labeled datasets are not only more reliable and trustworthy but also support better collaboration and reproducibility among researchers and data scientists.
Different Types of Image Labels
When it comes to image labeling, there are various types of labels that can be assigned to different objects, regions, or attributes within an image. These labels provide information for training machine learning models to recognize and classify visual elements accurately. Some common types of image labels include:
Object Labels: Object labels involve identifying and labeling specific objects or regions of interest within an image. For example, in an image of a park, object labels could include “tree,” “person,” “bench,” and “dog.” Object labels help models understand the different elements present in an image and learn to distinguish between them.
Attribute Labels: Attribute labels describe specific characteristics or attributes of objects within an image. These labels provide additional information about an object’s properties or features. For instance, in an image of clothing items, attribute labels could include “color,” “pattern,” “sleeve length,” or “material.” Attribute labels help models learn to recognize and differentiate objects based on their specific attributes.
Scene Labels: Scene labels focus on identifying and categorizing different types of scenes or environments depicted in an image. Examples of scene labels can include “beach,” “urban street,” “mountain landscape,” or “kitchen.” Scene labels enable models to understand the context and setting of an image, which is crucial for accurate scene recognition and understanding.
Anomaly Labels: Anomaly labels are used to identify irregular or uncommon objects or regions within an image. These labels help models detect and flag unexpected or outlier instances. Detecting anomalies is valuable in various applications, such as identifying defects in manufacturing, detecting anomalies in medical images, or identifying unusual behavior in surveillance videos.
Temporal Labels: Temporal labels are used when labeling images that are part of a sequence or a time series. These labels assign timestamps or time-related information to the images, allowing models to learn temporal dependencies and patterns. Temporal labels are crucial for tasks such as action recognition, video analysis, or predicting future states based on historical data.
These are just a few examples of the different types of image labels that can be assigned to enhance the understanding and analysis of visual data. The choice of labels depends on the specific requirements of the machine learning task and the desired insights that need to be derived from the image dataset.
Defining Annotation Guidelines
Annotation guidelines serve as a set of instructions and rules that annotators follow when labeling images. These guidelines play a critical role in ensuring consistency, accuracy, and reliability in image annotation. Defining clear and comprehensive annotation guidelines is essential for achieving high-quality annotations and minimizing ambiguity. Here are some key factors to consider when defining annotation guidelines:
Task-specific Instructions: Annotation guidelines should provide clear instructions that align with the specific task or objective of the machine learning project. These instructions should outline the desired labeling approach, the types of objects or attributes to be labeled, and any specific requirements or limitations.
Clear Object Definitions: The guidelines should include precise definitions and examples of the objects or regions to be labeled. This ensures that annotators have a clear understanding of what constitutes an object and helps avoid potential confusion or misinterpretation.
Labeling Consistency: Consistency in labeling is crucial for training accurate machine learning models. Annotation guidelines should address any potential ambiguities and provide rules or examples to handle cases where objects may overlap, partially occlude each other, or have varying levels of visibility.
Labeling Granularity: Guidelines should specify the desired level of labeling granularity. This can include determining whether to label objects at the instance level (individual objects) or at a category level (grouping similar objects together). The granularity choice depends on the specific requirements and objectives of the machine learning task.
Handling Ambiguity: Annotation guidelines should address situations where there is ambiguity or uncertainty in labeling. This can involve providing guidelines on how to handle cases where an object is partially visible or when distinguishing between similar objects is challenging. Clear instructions can help annotators make informed labeling decisions.
Quality Control Measures: Guidelines should outline quality control measures to maintain the accuracy and consistency of annotations. This can include periodic review of annotations, addressing questions or clarifications from annotators, and conducting regular meetings or training sessions to ensure annotation guidelines are being followed correctly.
Iterative Refinement: Annotation guidelines should be seen as a living document that can be refined and updated based on feedback and experience from annotators and model performance. Regularly revisiting and refining guidelines ensures continuous improvement in annotation quality and contributes to the overall success of the machine learning project.
Defining clear and well-structured annotation guidelines is essential for achieving high-quality and reliable annotations. These guidelines provide a common understanding and framework for annotators, enabling them to produce accurate and consistent annotations in line with the objectives of the machine learning project.
Choosing the Right Annotation Tools
When it comes to image labeling, selecting the right annotation tools is crucial for efficient and accurate annotation. These tools provide the necessary functionality and features to streamline the annotation process and enhance productivity. Here are some key factors to consider when choosing the right annotation tools:
Annotation Capabilities: The chosen annotation tools should have the required annotation capabilities to fulfill the specific labeling needs of the machine learning project. This includes support for different types of annotations such as bounding boxes, polygons, keypoints, or semantic segmentation masks.
User-Friendly Interface: The annotation tools should have an intuitive and user-friendly interface that is easy to navigate and understand. A well-designed interface helps annotators quickly grasp the annotation process, reducing the learning curve and ensuring efficient and accurate annotations.
Customizability: The ability to customize the annotation tools to match the specific requirements of the project is essential. This includes the option to define custom annotation types, create labeling templates, or adapt the tool to domain-specific labeling guidelines.
Collaboration Features: If multiple annotators or teams are involved in the annotation process, the chosen tools should have collaboration features in place. These features allow for seamless communication, collaboration, and version control, ensuring consistency and reducing the chances of errors or duplications.
Automation and Assistance: Annotation tools that offer automation or assistance features can significantly improve the efficiency and accuracy of the annotation process. This can include automated object detection or suggestions, semi-automatic annotation mechanisms, or AI-driven assistance to speed up the labeling process.
Data Security and Privacy: Considering the sensitivity of the data being annotated, it is crucial to choose annotation tools that prioritize data security and privacy. Look for tools that offer secure data storage, robust user access controls, and compliance with data privacy regulations.
Integration and Compatibility: The annotation tools should integrate seamlessly with other components of the machine learning workflow. This includes compatibility with the chosen training frameworks, data management systems, or data labeling platforms to ensure a smooth and efficient workflow from annotation to model training.
Cost and Scalability: Assess the cost structure and scalability of the annotation tools. Consider factors such as pricing plans, licensing models, technical support, and the tool’s ability to handle large-scale annotation projects efficiently.
Choosing the right annotation tools is essential for ensuring a smooth and efficient annotation workflow. Evaluating tools based on their annotation capabilities, user-friendliness, customization options, collaboration features, automation capabilities, data security, and scalability will help select the most suitable tool to meet the specific requirements of the machine learning project.
Creating an Annotation Plan
An annotation plan provides a roadmap for the image labeling process, ensuring that the annotation task is well-organized and successfully executed. It outlines the key steps, resources, and strategies required to achieve accurate and high-quality image annotations. Here are some essential elements to consider when creating an annotation plan:
Define Annotation Objectives: Start by clearly defining the objectives of the annotation task. This involves understanding the specific goals, requirements, and desired outcomes of the machine learning project. Clearly defining the objectives will help guide the annotation process and ensure that annotations align with the project’s objectives.
Determine Annotation Categories: Identify the different categories of annotations that will be assigned to the images. This could include object labels, attribute labels, or scene labels, depending on the project’s requirements. Categorizing annotations helps streamline the labeling process and ensures consistency throughout the dataset.
Allocate Resources: Determine the resources required for the annotation process, including the number of annotators, their expertise, and the availability of labeling tools. Allocating resources appropriately ensures that the annotation task can be completed within the project’s timeline and budget constraints.
Create Annotation Guidelines: Develop clear and comprehensive annotation guidelines that provide instructions and examples for annotators to follow. These guidelines should cover object definitions, labeling conventions, handling ambiguity, and any specific requirements particular to the project. Well-defined guidelines aid in maintaining consistency and accuracy in the annotation process.
Strategize Quality Assurance: Implement quality assurance mechanisms to ensure the accuracy and reliability of the annotations. This can involve conducting regular checks on annotations, providing feedback and training to annotators, and implementing review processes to address any discrepancies or errors. Quality assurance measures contribute to the production of high-quality annotated datasets.
Create a Timeline: Develop a timeline that outlines the start and end dates of the annotation project, as well as key milestones and deliverables. The timeline helps maintain project progress, ensures efficient resource utilization, and sets realistic expectations for completion.
Manage Annotation Workflow: Establish an efficient annotation workflow that accounts for the distribution of images among annotators, the review and feedback process, and any collaboration required between annotators or teams. Managing the workflow effectively helps streamline the annotation process and maintain consistency across the dataset.
Consider Scalability: If the annotation project involves a large dataset or has the potential to scale in the future, consider scalability. This may include exploring options for automation, leveraging semi-automatic annotation techniques, or utilizing cloud-based annotation platforms to handle increased annotation demands efficiently.
Document and Iterate: Document the entire annotation process, including any modifications, challenges faced, and lessons learned along the way. This documentation serves as a valuable resource for future projects and enables continuous improvement in the annotation process.
Creating a comprehensive annotation plan sets the foundation for a successful image labeling project. By clearly defining objectives, allocating resources, creating guidelines, implementing quality assurance, managing the workflow, and considering scalability, you can ensure that the annotation process is well-structured and yields accurate and reliable annotations.
Best Practices for Image Labeling
Image labeling is a critical step in machine learning projects, and following best practices ensures the production of high-quality annotations. Consistency, accuracy, and attention to detail are key to achieving reliable results. Here are some best practices to consider when labeling images:
Understanding the Guidelines: Thoroughly read and understand the annotation guidelines before starting the labeling process. Familiarize yourself with the annotation types, definitions, and any specific instructions provided. This ensures consistent and accurate annotations.
Attention to Detail: Pay close attention to the details of the image and align your annotations precisely with the objects or regions being labeled. Ensure that the annotations accurately represent the shape, size, and location of the objects in the image.
Consistent Labeling Style: Follow a consistent labeling style throughout the annotation task. Use the same annotation shape, color, and thickness for similar objects. Consistency in labeling style helps maintain uniformity and facilitates model training and evaluation.
Avoid Overlapping Annotations: Avoid placing annotations that overlap or exceed the boundaries of other objects in the image. Overlapping annotations can cause confusion and hinder accurate object detection and classification by machine learning algorithms.
Handle Ambiguity with Care: If there is ambiguity or uncertainty in labeling an object or region, consult the annotation guidelines or seek clarification from project managers. It is crucial to handle ambiguity consistently and accurately to ensure reliable annotations.
Collaboration and Communication: If multiple annotators are involved, maintain open communication. Collaborate with other annotators to address questions or challenges and ensure consistency in labeling approaches. Sharing knowledge and insights can improve overall annotation quality.
Quality Assurance: Regularly review and validate your annotations against the annotation guidelines. Conduct self-assessments to identify and rectify any mistakes or inconsistencies in your labeling. Quality assurance measures help maintain the accuracy and reliability of annotations.
Double-check Difficult Cases: For complex or challenging cases, take extra care to ensure accurate annotations. Refer to the guidelines, consult with domain experts if needed, or seek consensus with other annotators to make informed decisions on labeling such cases.
Continuously Learn and Improve: Stay updated with new annotation techniques, tools, and best practices. Actively seek feedback from project managers, senior annotators, or domain experts to continuously improve your annotation skills and enhance the overall quality of the annotations.
Documentation and Versioning: Maintain clear documentation of your annotations, including any revisions or modifications made during the labeling process. Version control ensures traceability and helps address any discrepancies or questions that may arise in the future.
Following these best practices contributes to the production of accurate and reliable annotations. Consistency, attention to detail, collaboration, and continuous improvement are key factors in creating high-quality labeled datasets that enable successful machine learning model training and deployment.
Ensuring Consistency in Labeling
Consistency in labeling is crucial for machine learning projects as it ensures that annotated data is reliable, coherent, and can be effectively utilized for training models. Consistency allows models to learn patterns accurately and make reliable predictions. Here are some key strategies for ensuring consistency in labeling:
Clear Annotation Guidelines: Provide clear and comprehensive annotation guidelines that define the labeling process, labeling conventions, and annotation standards. Guidelines should include examples, specific instructions, and clarification on any ambiguous areas to ensure consistent understanding and interpretation.
Training and Calibration: Conduct proper training and calibration sessions with annotators to ensure they understand and adhere to the annotation guidelines. Training sessions help in familiarizing annotators with the labeling process and overseeing consistent labeling practices.
Reference Dataset: Create a reference dataset that serves as an exemplar for consistent labeling. This reference dataset, which contains accurately labeled images, can be used as a benchmark to compare and align the annotations produced by different annotators. It serves as a visual reference for maintaining consistency in labeling.
Regular Communication: Maintain open lines of communication among annotators. Encourage discussions, share insights, and address any uncertainties or questions that may arise during the labeling process. Regular communication promotes knowledge sharing, offers guidance, and improves overall consistency.
Consistency Checks: Conduct regular checks to ensure consistency across annotations. Compare annotations of the same objects or scenes across different annotators or at different stages of the labeling process. Identify and address any inconsistencies promptly to maintain a high level of reliability in the dataset.
Review and Feedback: Establish a feedback loop to review annotations and provide constructive feedback to annotators. This enables annotators to learn from their mistakes and improve their labeling consistency over time. Timely feedback helps correct any deviations and ensures adherence to the prescribed annotation guidelines.
Quality Assurance Measures: Implement quality assurance measures to maintain consistency and accuracy in labeling. This can involve regular reviews of annotated data, conducting inter-annotator agreement assessments, and resolving any discrepancies or disagreements between annotations.
Use Tools and Automation: Utilize annotation tools and automation techniques to promote consistency and efficiency. These tools often have features that enforce consistency, such as labeling templates or pre-defined annotation categories, ensuring annotators follow standardized labeling practices.
Iterative Improvement: Continuously strive for improvement in labeling consistency. Analyze the feedback received, identify areas for improvement, and refine the annotation guidelines and processes accordingly. Encourage and involve annotators in the improvement process to foster a culture of continuous learning and growth.
Ensuring consistency in labeling is essential for creating reliable datasets that drive successful machine learning outcomes. By providing clear guidelines, conducting proper training, facilitating regular communication, implementing consistency checks, and embracing quality assurance measures, you can maintain a high level of consistency in labeling, enabling accurate model training and reliable predictions.
Handling Ambiguity and Edge Cases
During the image labeling process, annotators often encounter ambiguity and edge cases that require careful consideration. These situations can pose challenges when determining the appropriate labels for objects or regions within images. Here are some strategies to effectively handle ambiguity and address edge cases:
Consult Annotation Guidelines: Rely on the annotation guidelines as the primary resource for addressing ambiguity and edge cases. The guidelines should provide instructions and examples that guide annotators on how to handle challenging scenarios and make informed labeling decisions.
Seek Clarification: If the annotation guidelines do not provide clear instructions or if there is uncertainty regarding the appropriate label for a specific object or region, seek clarification from project managers, domain experts, or other experienced annotators. Collectively addressing ambiguity can lead to consistent and accurate annotations.
Collaborative Discussions: Engage in collaborative discussions with other annotators or relevant stakeholders to resolve ambiguous cases. Sharing different perspectives and collectively making decisions can lead to more robust and informed annotations in complex situations.
Define Boundary Criteria: In situations where the boundaries of objects or regions are unclear, establish clear criteria for determining the boundaries. This can involve considering visual cues, using contextual information, or applying predefined rules to establish consistent and well-defined object boundaries.
Refer to Reference Data: Utilize a reference dataset, if available, to compare and align annotations for ambiguous cases. Use the reference data as a benchmark and reference point to ensure consistency and to make informed decisions when labeling ambiguous objects.
Consensus Building: Encourage annotators to collaborate and reach a consensus when facing ambiguous or challenging cases. Holding regular collaborative sessions or involving multiple annotators in the decision-making process can lead to more consistent and reliable annotations.
Document Ambiguous Cases: Keep a record of ambiguous cases encountered during the annotation process. Documenting these cases and the resolutions can serve as a helpful reference for future projects and provide insights for improving the annotation guidelines and processes.
Iterative Improvement: Continuously learn and improve by reviewing previously labeled ambiguous cases and seeking opportunities to refine annotation guidelines. Analyzing and addressing past challenges helps enhance future labeling consistency and accuracy.
Domain Expertise: For complex or domain-specific edge cases, consult domain experts who possess specialized knowledge. Their expertise can provide valuable insights and guidance for resolving ambiguity and accurately labeling objects or regions within images.
Handling ambiguity and edge cases demands attention to detail, collaboration, and a diligent adherence to annotation guidelines. By seeking clarification, engaging in collaborative discussions, defining boundary criteria, referring to reference data, building consensus, documenting cases, and leveraging domain expertise, annotators can effectively navigate ambiguity and ensure consistent, accurate, and reliable image annotations.
Quality Assurance in Image Annotation
Quality assurance is a crucial aspect of the image annotation process as it ensures the accuracy, reliability, and consistency of the annotated data. By implementing effective quality assurance measures, annotation errors and inconsistencies can be identified and corrected, resulting in high-quality labeled datasets. Here are some key strategies for maintaining quality assurance in image annotation:
Define Quality Metrics: Clearly define the quality metrics and criteria that will be used to evaluate the annotations. These metrics can include accuracy, completeness, consistency, and adherence to annotation guidelines. By establishing specific quality standards upfront, annotators can strive to meet these benchmarks.
Random Sampling: Conduct random sampling of annotated data to assess the quality and identify potential issues. Select a representative subset of the dataset and review the annotations to ensure they meet the desired quality standards. If any issues are identified, corrective measures can be implemented to improve overall quality.
Inter-annotator Agreement: Foster inter-annotator agreement by involving multiple annotators in the labeling process. Compare and assess the agreement between the annotations provided by different annotators for the same set of images. This helps identify and resolve discrepancies, ensuring consistent and reliable annotations.
Blind Testing: Implement blind testing by withholding a subset of annotated images from the annotators. Evaluate the quality of these blind test images separately to assess the accuracy and consistency of the annotations. Blind testing can help identify any systematic errors and improve the overall reliability of the dataset.
Regular Feedback and Review: Provide regular feedback and review sessions with annotators to address any issues or challenges identified in their annotations. Offer constructive criticism, provide guidance, and track improvement over time to ensure continual enhancement of annotation quality.
Continuous Training: Conduct regular training sessions to refresh annotators’ knowledge of the annotation guidelines and reinforce best practices. This helps maintain a high level of consistency in annotation practices, improves accuracy, and ensures adherence to quality standards.
Establish Communication Channels: Establish open communication channels between annotators, project managers, and domain experts. Encourage annotators to ask questions, seek clarifications, and share insights. This promotes collaboration, resolves issues promptly, and strengthens the overall quality assurance process.
Version Control: Implement version control to track changes to the annotations and ensure traceability. Maintain a record of any revisions or modifications made during the quality assurance process to maintain a transparent and auditable history of the dataset.
Iterative Improvement: Continuously learn from the quality assurance process and identify areas for improvement. Analyze the feedback received, identify and address patterns of errors or inconsistencies, and refine annotation guidelines, training materials, or processes to enhance annotation quality.
Implementing effective quality assurance measures is essential for producing accurate and reliable annotations. By defining quality metrics, conducting random sampling, ensuring inter-annotator agreement, implementing blind testing, providing regular feedback and review, offering continuous training, establishing communication channels, practicing version control, and striving for iterative improvement, the overall quality of the annotated dataset can be maintained and enhanced.
Dealing with Large-Scale Image Annotation Projects
Large-scale image annotation projects can pose unique challenges due to the sheer volume of images and the need for efficient and accurate annotation processes. Handling these projects effectively requires careful planning, resource allocation, and the implementation of streamlined workflows. Here are some strategies for dealing with large-scale image annotation projects:
Infrastructure and Resources: Assess and allocate the necessary infrastructure and resources to handle the scale of the project. This includes having a robust and scalable annotation platform, sufficient computing resources, and a team of skilled annotators to ensure timely completion of the annotations.
Task Segmentation: Break down the annotation task into manageable segments or batches. Dividing the project into smaller tasks allows for better distribution of work among annotators and facilitates parallel annotation, making it easier to track progress and maintain consistency across the dataset.
Efficient Annotation Tools: Choose annotation tools that are capable of handling large-scale projects. Look for features like batch processing, automation, and collaboration capabilities to streamline the annotation process, enhance productivity, and ensure consistent results.
Prioritization Strategy: Develop a prioritization strategy to efficiently allocate resources and annotate images based on importance, complexity, or urgency. This ensures that critical or challenging images receive prompt attention while maintaining a steady progression through the project.
Data Management: Implement an efficient data management system to track, organize, and store the annotated data. Plan for sufficient storage capacity and backup solutions to secure the labeled images and associated metadata, enabling easy access and retrieval when needed.
Quality Control Measures: Establish robust quality control measures to ensure the accuracy and reliability of annotations in large-scale projects. This may involve regular reviews, inter-annotator agreement assessments, and random sampling to identify and rectify any issues or inconsistencies that arise during the annotation process.
Collaborative Workflow: Foster collaboration and communication among annotators, project managers, and domain experts. Implement clear communication channels and encourage knowledge sharing to address questions, resolve ambiguities, and ensure consistency across the team.
Automation and AI Assistance: Explore automation techniques and leverage AI assistance to expedite the annotation process. Automated pre-processing, object detection algorithms, or semi-automatic annotation tools can significantly reduce the time and effort required for large-scale projects while maintaining high-quality results.
Monitoring and Reporting: Implement monitoring mechanisms to track annotation progress and identify potential bottlenecks or issues. Generate regular reports on the project’s status, including completion rates, accuracy metrics, and any challenges encountered. This enables effective project management and timely intervention if needed.
Continuous Optimization: Continuously optimize the annotation process based on insights gained throughout the project. Identify areas for improvement, refine annotation guidelines, provide additional training resources, or adopt new annotation techniques to enhance efficiency, accuracy, and scalability.
Successfully managing large-scale image annotation projects requires careful planning, efficient workflows, robust infrastructure, skilled annotators, automation, and effective quality control measures. By implementing these strategies, projects can handle the challenges inherent in large-scale annotation, ensuring accurate and reliable annotations within the set timelines and resource constraints.
Ethical Considerations in Image Labeling
Image labeling in machine learning projects comes with ethical responsibilities that need to be carefully considered and addressed. As machine learning algorithms rely on annotated data to learn and make decisions, it is important to be mindful of potential ethical implications. Here are some key ethical considerations in image labeling:
Data Privacy and Consent: Respect individuals’ privacy rights by ensuring that the images used in the annotation process are collected and utilized responsibly. Obtain appropriate consent from data subjects if personal or sensitive information is involved, adhering to applicable data protection regulations.
Non-biased Labeling: Employ non-biased labeling practices to avoid perpetuating or amplifying biases present in the labeled datasets. Provide fair and accurate annotations that do not discriminate against individuals or communities based on characteristics such as race, gender, age, or socioeconomic status.
Avoiding Harmful Content: Exercise caution and diligence to prevent the annotation of content that might be harmful, offensive, illegal, or unethical. Establish clear guidelines and monitoring processes to prevent the dissemination or perpetuation of inappropriate or harmful material.
Data Security: Safeguard the annotated data throughout the annotation process. Implement secure data storage and access controls to protect against unauthorized use, loss, or misuse of the labeled images and associated metadata, maintaining data integrity and confidentiality.
Transparency and Explainability: Promote transparency in the annotation process by documenting and disclosing the methodology, techniques, and criteria used. Strive to ensure that the labeling process is understandable, explainable, and accountable, helping to build trust and foster responsible use of the labeled datasets.
Fair Compensation: Provide fair compensation and working conditions to annotators. Acknowledge their contribution to the project and ensure appropriate remuneration and benefits, aligned with industry standards and local labor regulations.
Informed Consent for Workers: Obtain informed consent from annotators regarding their participation in the annotation process. Clearly communicate the nature of the work, potential risks, and any requirements or obligations. Ensure that annotators have a comprehensive understanding of their roles and responsibilities.
Collaboration and Ethical Review: Foster collaboration and engagement across stakeholders, including annotators, project managers, ethicists, and domain experts. Conduct ethical reviews of the labeling process, discussing potential ethical concerns, considering alternative approaches, and identifying strategies to mitigate any ethical challenges that may arise.
Continual Education and Awareness: Remain updated on evolving ethical guidelines, principles, and standards related to image labeling in machine learning. Provide ongoing education and awareness training to annotators and project team members to ensure a shared understanding of ethical considerations and responsible practices.
Public Accountability: Foster public accountability by making efforts to engage in open dialogue, share information about the annotation process, and respond to accountability inquiries. Building trust and demonstrating accountability are critical steps towards responsible image labeling.
By integrating and addressing these ethical considerations throughout the image labeling process, machine learning projects can strive for responsible and ethical use of annotated data, contributing to the development and deployment of unbiased, fair, and equitable machine learning models.
Future Trends in Image Annotation for Machine Learning
The field of image annotation for machine learning is continuously evolving, driven by advancements in technology and emerging research. Several trends are shaping the future of image annotation, enhancing efficiency, accuracy, and the ability to tackle new challenges. Here are some noteworthy trends to watch:
Automation and AI-Assisted Annotation: Automation techniques and AI assistance will play a significant role in image annotation. Automated pre-processing, object detection algorithms, and AI-driven suggestions can expedite the annotation process, reduce manual effort, and improve efficiency while maintaining high-quality annotations.
Active Learning: Active learning methods will become more prevalent in image annotation. By dynamically selecting the most informative samples to annotate, active learning reduces labeling efforts while maximizing the model’s learning capabilities. This iterative process focuses annotation efforts on challenging and uncertain instances, improving overall annotation quality and model performance.
Weakly Supervised Learning: Weakly supervised learning aims to obtain annotations with less human effort. Techniques like weak supervision, where annotations are provided at a higher level of granularity (e.g., image-level labels), will gain popularity. These approaches leverage existing knowledge and large-scale datasets to train models effectively.
Semantic Segmentation and Instance Segmentation: As the demand for finer-grained annotations increases, semantic segmentation and instance segmentation will become more prevalent. These techniques allow for pixel-level or object-level annotations, providing detailed spatial information and enabling more precise modeling of object boundaries and attributes.
Multi-modal Annotation: The annotation of multi-modal data, such as images accompanied by text, audio, or other sensory information, will become more important. Integrating multiple modalities provides richer annotations, enabling models to learn from diverse sources and enhance their understanding of complex scenes and contexts.
Continual Learning: Continual learning addresses the challenge of evolving real-world scenarios by updating models incrementally with new annotations over time. This approach allows models to adapt and accommodate novel classes, handle concept drift, and avoid catastrophic forgetting, eliminating the need for retraining from scratch.
Explainable AI in Annotation: As AI models become increasingly complex, interpretability and explainability in the annotation process will gain importance. Methods that generate not only annotations but also explanations for the decisions made by the model will improve transparency and trust, particularly in critical applications like healthcare or autonomous driving.
Domain-Specific Annotation Tools: We can anticipate the rise of domain-specific annotation tools tailored to specific industries or applications. These tools will provide specialized features and annotation guidelines customized for precise labeling requirements in fields like medical imaging, robotics, remote sensing, or social media analysis.
Ethical Annotation Frameworks: The ethical considerations in image annotation will continue to evolve. Frameworks emphasizing fairness, transparency, accountability, and privacy will be developed to ensure responsible annotation practices and mitigate potential biases or ethical challenges that may arise in large-scale annotation projects.
These trends are shaping the future of image annotation for machine learning, transforming the field and improving the capabilities of AI models. By harnessing automation, leveraging active and weakly supervised learning, exploring advanced annotation techniques, and incorporating ethical frameworks, image annotation will continue to push the boundaries of what AI can achieve in various domains and applications.