
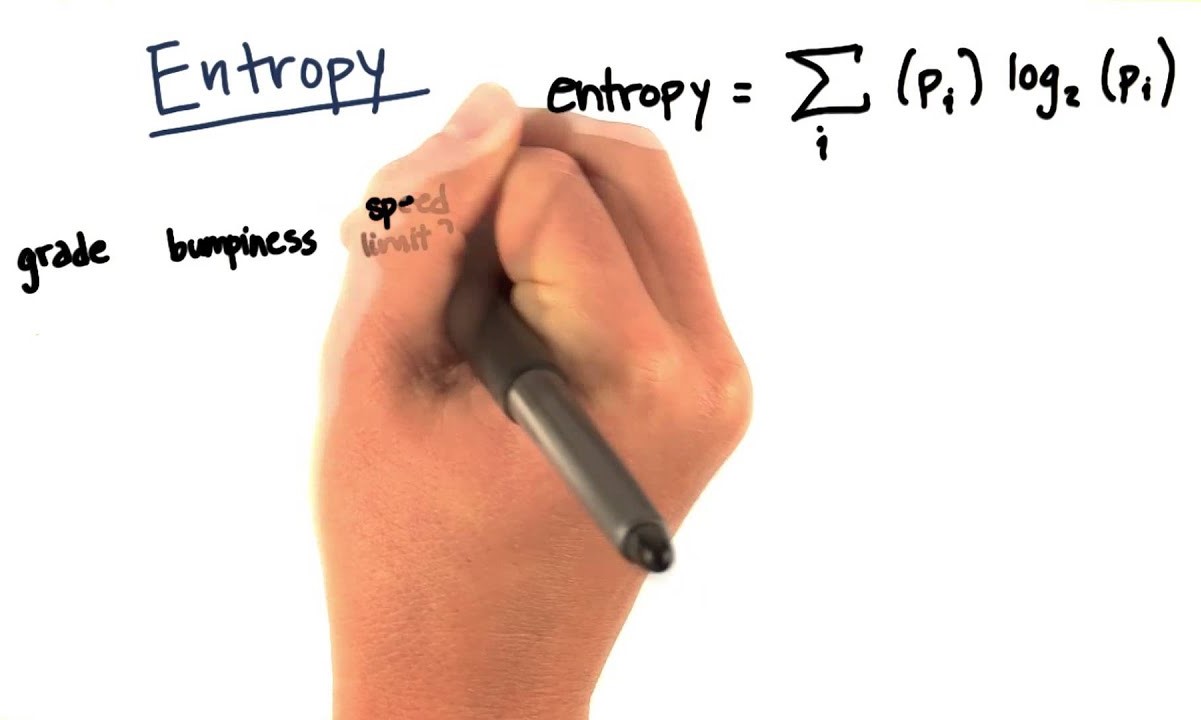
What Is Entropy?
Entropy is a fundamental concept in information theory and plays a crucial role in the field of machine learning. In simple terms, entropy measures the uncertainty or impurity of a random variable. It provides a way to quantify the amount of information contained in a set of data.
In the context of machine learning, entropy is often used to evaluate the purity of a group of instances or the randomness of a set of variables. It serves as a guiding principle for making decisions and selecting the most informative features to improve the accuracy of models.
Entropy is closely related to the concept of disorder or randomness. The higher the entropy, the greater the uncertainty or disorder in the data. Conversely, low entropy indicates a high level of certainty or order.
Imagine a binary classification problem where you have two classes: A and B. If all instances belong to class A, the entropy is zero because there is no uncertainty—every instance is perfectly classified. On the other hand, if the instances are evenly split between classes A and B, the entropy is at its maximum because there is equal uncertainty about which class each instance belongs to.
Entropy is often used in decision tree algorithms, where the goal is to split the data into homogeneous subsets at each node. By computing the entropy of different splits, the algorithm can determine the most informative attribute to divide the data and minimize uncertainty.
Entropy is a valuable metric for understanding and managing uncertainty in machine learning. It provides a quantitative measure of how much information is present in a dataset and guides the decision-making process to improve the accuracy and efficiency of models.
The Concept of Entropy in Machine Learning
Entropy is a key concept in machine learning that measures the impurity or uncertainty of a dataset. It is widely used in decision tree algorithms and feature selection techniques to improve the accuracy and efficiency of models.
In machine learning, entropy is often applied in classification problems where we want to determine the class membership of a given instance based on its features. The goal is to maximize the information gain and minimize the entropy to create accurate models.
To better understand the concept of entropy, let’s consider a binary classification problem with two classes, A and B. The entropy of the dataset is calculated by examining the distribution of instances across these classes. If all instances in the dataset belong to a single class, the entropy is 0, indicating perfect classification. However, if the instances are evenly split between classes A and B, the entropy is at its maximum, indicating maximum uncertainty.
The entropy of a dataset can be calculated using the following formula:
Entropy(S) = -p(A) * log(p(A)) - p(B) * log(p(B))
where p(A) and p(B) represent the probabilities of instances belonging to classes A and B, respectively.
Entropy is a useful measure for evaluating the quality of splits in decision tree algorithms. When building a decision tree, the algorithm aims to find the attribute that maximizes the information gain, which is the difference between the entropy of the parent node and the weighted sum of the entropies of its child nodes. By recursively splitting the data based on the attribute with the highest information gain, decision trees can effectively classify instances.
Entropy is also employed in feature selection techniques, where the goal is to identify the most informative attributes for a given task. Features with high entropy contribute more information to the decision-making process, making them valuable for modeling.
Information Theory and Entropy
Entropy, as applied in machine learning, is rooted in information theory, a branch of mathematics that deals with the quantification and transmission of information. Developed by Claude Shannon in the 1940s, information theory provides a framework for understanding how information is encoded, transmitted, and decoded.
In information theory, entropy measures the average amount of information or uncertainty contained in a set of messages or symbols. It quantifies the amount of randomness or disorder in the data. The higher the entropy, the more uncertainty or randomness exists.
To calculate the entropy of a set of symbols, we consider the probabilities of each symbol occurring. The entropy is then defined as the sum of the individual probabilities multiplied by their logarithms. This calculation captures the amount of “surprise” or new information each symbol provides.
In the context of machine learning, information theory and entropy help us determine the optimal way to represent and classify data. By measuring the entropy of a dataset, we can gauge the amount of information present and make decisions regarding feature selection, model building, and data processing.
The concept of entropy aligns with the intuition that a dataset with more uniformly distributed classes or symbols contains more uncertainty, requiring more information to accurately classify or predict. Conversely, a dataset with highly skewed or unambiguous distributions will have lower entropy, indicating less uncertainty.
Entropy is often used hand in hand with other information theory concepts such as mutual information, which measures the amount of information shared between two random variables. Mutual information helps identify the most informative features for classification or regression tasks, enabling us to select the most relevant attributes that contribute to reducing uncertainty and improving model performance.
By leveraging information theory and entropy, machine learning algorithms can make more informed decisions, optimize feature selection, enhance data representation, and ultimately improve the accuracy and efficiency of models. Understanding these concepts allows us to harness the power of information and uncertainty to tackle complex problems in the field of machine learning.
Calculating Entropy in Machine Learning
In machine learning, entropy is a crucial metric used to measure the uncertainty or randomness of a dataset. By calculating entropy, we gain insights into the amount of information or disorder present in the data, enabling us to make informed decisions for model building and data analysis.
The formula to compute entropy in machine learning depends on the number of classes or categories present in the dataset. For a binary classification problem with two classes, the entropy calculation is relatively straightforward.
To calculate the entropy of a dataset, we first determine the probability of each class occurring. Then, for each class, we compute the product of the probability and its logarithm base 2, summing up all these values:
Entropy(S) = -p(Class1) * log2(p(Class1)) - p(Class2) * log2(p(Class2))
Where S represents the dataset, and p(Class1) and p(Class2) denote the probabilities of class 1 and class 2 occurring in the dataset, respectively.
The resulting entropy value ranges between 0 and 1, with 0 indicating complete homogeneity or perfect classification and 1 representing maximum uncertainty or randomness.
When dealing with multiclass classification problems, the entropy calculation becomes more complex. Instead of computing the entropy for each class individually, we sum the products of each class’s probability and the logarithm of that probability across all classes present.
Entropy is often used in decision tree algorithms to determine the best feature to split the data and minimize uncertainty. By calculating the entropy for different attribute splits, we can assess the information gain of each split and select the one that reduces the overall entropy the most. This process helps create more accurate and efficient decision trees.
By calculating entropy, machine learning algorithms can gain insights into the uncertainty and randomness present in the data. This information is leveraged to make informed decisions, optimize feature selection, and improve the performance of models.
Entropy-Based Feature Selection
Feature selection is a crucial step in machine learning, aiming to identify the most informative attributes or features that contribute to accurate model predictions. Entropy-based feature selection is a popular approach that leverages the concept of entropy to determine the relevance and importance of different features in a dataset.
The idea behind entropy-based feature selection is to evaluate the information gain or reduction in entropy that each feature brings to the classification task. Features with high information gain are considered more valuable, as they contribute more to reducing uncertainty and improving the model’s predictive accuracy.
The process of entropy-based feature selection involves the following steps:
- Calculate the entropy of the target variable before any feature is considered.
- For each feature, calculate the information gain by dividing the dataset into subsets based on the values of that feature and measuring the reduction in entropy.
- Select the feature with the highest information gain as it provides the most significant reduction in entropy and contributes the most to the classification task.
- Repeat the process recursively for the remaining features until a predefined number of features is selected.
By using entropy-based feature selection, we can identify the most relevant features and eliminate redundant or irrelevant ones, reducing the dimensionality of the dataset. This process not only improves the efficiency and computational performance of models but also enhances their accuracy by focusing on the crucial information.
It is important to note that entropy-based feature selection assumes that the target variable is categorical or discrete. If the target variable is continuous, it may require discretization or alternative feature selection methods.
Entropy-based feature selection is widely used in various domains and applications, such as text classification, image recognition, and bioinformatics. It allows for more interpretable and efficient models while ensuring that only the most informative features are considered.
By applying entropy-based feature selection techniques, machine learning algorithms can effectively identify and utilize the most relevant attributes, enabling more accurate predictions and insights from the data.
Entropy-Based Decision Trees
Decision trees are popular machine learning models that make predictions by recursively splitting the data based on specific attributes. Entropy plays a crucial role in determining these attribute splits and building decision trees effectively.
An entropy-based decision tree algorithm aims to minimize uncertainty and maximize information gain at each step of the tree construction process. The algorithm computes the entropy of the dataset before and after each potential split and selects the attribute that results in the greatest reduction in entropy.
At each node of the decision tree, the algorithm calculates the entropy of the target variable, which represents the uncertainty of classifying the instances. Then, it examines the potential attributes and calculates the information gain of each attribute based on the reduction in entropy if that attribute is chosen as the splitting criterion.
The information gain is calculated by subtracting the weighted sum of the entropies of the resulting child nodes from the entropy of the parent node. If the information gain is higher, it indicates that using that attribute for the split will result in a more informative and accurate decision tree.
The decision tree algorithm continues recursively by splitting the data based on the attribute with the highest information gain, creating child nodes for each potential value of the attribute. This process continues until a stopping condition is met, such as reaching a certain depth or having no further improvement in information gain.
By using entropy-based decision trees, we can create intuitive and interpretable models. Decision trees partition the dataset into homogeneous subsets, where each leaf node represents a specific prediction or classification. This allows us to understand the logic behind each prediction and visualize the decision-making process.
Furthermore, entropy-based decision trees can handle both categorical and numerical attributes, making them flexible for various types of datasets. They can handle missing values and outliers and are robust to noise, making them suitable for real-world scenarios.
Overall, entropy-based decision trees provide a powerful and versatile approach for classification and regression problems. By minimizing uncertainty and maximizing information gain, these models can accurately classify instances, make insights from data, and enable efficient decision-making processes.
Limitations of Entropy in Machine Learning
While entropy is a useful metric for measuring uncertainty and guiding decision-making in machine learning, it is important to recognize its limitations and potential drawbacks. Understanding these limitations can help us make informed choices when applying entropy-based techniques in our models.
One limitation of entropy is its sensitivity to class imbalance. When dealing with imbalanced datasets, where one class significantly outweighs the others, entropy may not accurately reflect the true uncertainty or information content. In such cases, other metrics like Gini impurity or misclassification error rate may provide more reliable measures of impurity or disorder.
Entropy-based methods also tend to favor attributes with a large number of distinct values or high cardinality. This can lead to bias in feature selection towards attributes that may not necessarily be more informative. In situations where features with lower cardinality but higher predictive power exist, other feature selection methods like information gain ratio or chi-squared may produce better results.
Another limitation of entropy is that it only considers the local characteristics of a dataset. It measures the impurity or uncertainty at each individual split point, without considering the global relationships or interactions between features. This can result in suboptimal decisions that do not fully capture the underlying patterns in the data. Other algorithms, such as random forests or gradient boosting, may overcome this limitation by considering ensemble-based approaches.
Entropy-based techniques can also be more computationally expensive compared to simpler methods like mean or variance calculation. Computing the entropy for each potential split in a large dataset can become time-consuming and resource-intensive. In such cases, approximation techniques or sampling methods may be employed to reduce the computational burden.
Furthermore, entropy-based methods assume that features are independent of each other. However, in real-world scenarios, features often exhibit dependencies or correlations. Ignoring these dependencies can lead to suboptimal results. Correlation-based feature selection or techniques like principal component analysis may be more suitable in cases where feature interdependence is prominent.
Use Cases of Entropy in Machine Learning
Entropy is a versatile concept that finds applications in various areas of machine learning. Its ability to measure uncertainty and information content makes it a valuable tool in solving a wide range of problems. Let’s explore some of the key use cases of entropy in machine learning.
Feature Selection: Entropy-based feature selection is commonly used to identify the most informative attributes in a dataset. By calculating the information gain of each feature based on entropy reduction, we can select the features that contribute the most to classification or regression tasks. This helps improve model accuracy and efficiency by reducing dimensionality and focusing on the most relevant information.
Decision Trees: Entropy plays a central role in constructing decision trees. Decision tree algorithms leverage entropy to determine the best attribute to split the data at each node, effectively reducing uncertainty and improving classification accuracy. By using entropy-based splitting criteria, decision trees can create interpretable models that capture complex decision-making processes.
Ensemble Methods: Entropy is also used in ensemble methods, such as random forests and gradient boosting. In random forests, multiple decision trees are trained on different subsets of the data, and entropy is employed to determine the best attribute to split at each node. Gradient boosting, on the other hand, uses entropy as the loss function to minimize model errors. These ensemble methods leverage the power of entropy to create more robust and accurate models.
Clustering: Entropy can be applied in clustering algorithms to measure the uncertainty or homogeneity of clusters. By calculating the entropy of cluster assignments, we can evaluate the quality of a clustering solution. Clustering algorithms can use entropy as a criterion to find the optimal number of clusters or assess the stability of different cluster configurations.
Anomaly Detection: Entropy-based techniques have been successfully employed in anomaly detection tasks. By measuring the entropy of patterns or behaviors in a dataset, we can identify instances that deviate significantly from the norm. High entropy indicates unpredictability or unusual patterns, which can help detect anomalies or abnormal behaviors in various domains, such as fraud detection or network intrusion detection.
Text Classification: In text classification tasks, entropy is utilized to quantify the information present in different classes or topics. By calculating the entropy of word occurrences across documents, we can determine the most informative words or n-grams for classification. This helps improve the accuracy and efficiency of text classification models by focusing on the most discriminative features.
These are just a few examples of how entropy is applied in machine learning. Its versatility and ability to measure uncertainty make it a valuable tool in various domains, contributing to accurate predictions, efficient algorithms, and effective data analysis.