
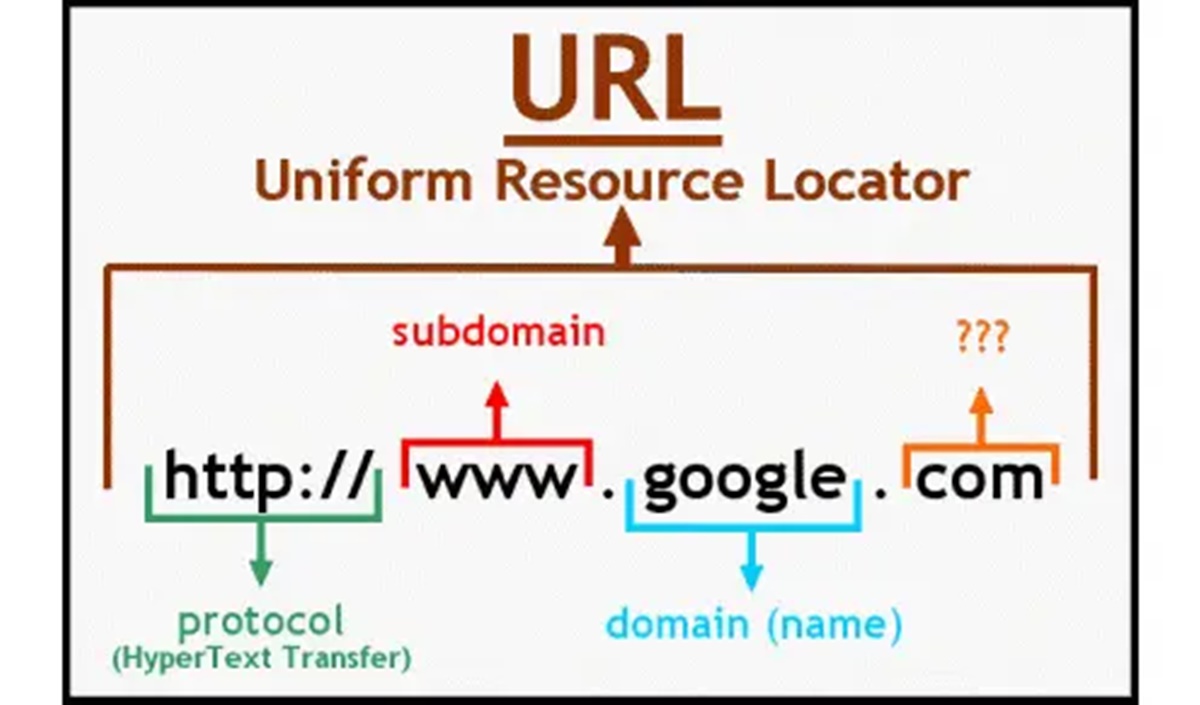
Anatomy of a URL
A URL (Uniform Resource Locator) is a string of characters that identifies the address of a resource on the internet. It is composed of various components that provide specific information about the location and type of resource being accessed. Understanding the different parts of a URL is essential for both web developers and everyday internet users.
Scheme: The scheme, or protocol, is the first part of a URL and indicates how the resource should be accessed. Common schemes include HTTP, HTTPS, FTP, and file. The scheme is followed by a colon and two forward slashes.
Host: The host specifies the domain name or IP address of the server where the resource is located. It can also include subdomains, which are additional parts of the domain that precede the main domain name. For example, in the URL https://www.example.com, “www” is the subdomain and “example.com” is the main domain.
Path: The path refers to the specific location or file on the server that the URL is pointing to. It typically represents a directory structure or a specific file name. For example, in the URL https://www.example.com/blog/article.html, “blog/article.html” is the path.
Query Parameters: Query parameters are used to pass additional information to the server. They are appended to the URL after a question mark and separated by ampersands. Each parameter consists of a key-value pair, with the key and value separated by an equal sign. For example, in the URL https://www.example.com/search?q=keyword&page=1, “q” and “page” are the query parameters.
Fragment Identifier: The fragment identifier is used to point to a specific section within a webpage. It is indicated by a hash symbol (#) followed by the fragment identifier. When the URL is accessed, the browser will scroll to the corresponding section on the page. For example, in the URL https://www.example.com#section3, the fragment identifier is “section3”.
Understanding the different components of a URL allows users to navigate the internet effectively and developers to create functional websites. By recognizing the purpose of each part, users can identify and access the desired resources on the web.
Scheme
The scheme, also known as the protocol, is the initial component of a URL that specifies how the resource should be accessed. It indicates the rules and conventions that browsers and servers must follow to establish a connection and retrieve the requested resource.
Common URL schemes include:
- HTTP (Hypertext Transfer Protocol): HTTP is the most widely used scheme on the internet. It is used for fetching resources, such as web pages, from web servers. HTTP URLs begin with “http://” followed by the domain name or IP address of the server.
- HTTPS (Hypertext Transfer Protocol Secure): HTTPS is a secure version of HTTP that encrypts the data being transmitted between a client and a server. It ensures the confidentiality and integrity of the information exchanged. HTTPS URLs start with “https://”.
- FTP (File Transfer Protocol): FTP is a protocol used for transferring files between a client and a server over a network. It is commonly used to upload and download files to and from a website’s server. FTP URLs begin with “ftp://”.
- File: The file scheme is used to access files on the local file system. It allows users to specify the file path relative to the device they are using. File URLs start with “file://”.
Schemes can also be used to access resources specific to certain applications or services. For example, “mailto:” is a scheme used to compose email messages, and “tel:” is a scheme used to initiate telephone calls.
The scheme component is vital as it determines how the browser will handle the URL and which protocol it will use for communication. It enables users to interact with websites and retrieve the content they need, whether it’s browsing web pages, transferring files, or engaging in other internet-based activities.
Host
The host component of a URL specifies the domain name or IP address of the server where the resource is located. It plays a crucial role in identifying the location of the desired resource on the internet.
A domain name is a human-readable address that represents an IP address, which is a series of numbers that uniquely identifies a device on a network. For example, in the URL “https://www.example.com”, “www.example.com” is the domain name.
The host can also include subdomains, which are additional parts of the domain that precede the main domain name. Subdomains are typically used to organize and differentiate different sections of a website. For example, in the URL “https://blog.example.com”, “blog” is the subdomain.
When a URL is entered into a browser, it uses the host component to establish a connection with the appropriate server. The browser sends a request to the server identified by the host component, asking for the resource specified in the rest of the URL.
Additionally, the host component can consist of an IP address instead of a domain name. An IP address is a unique identifier assigned to each device connected to a network. It enables direct communication with a specific device on the internet. For example, in the URL “https://192.168.0.1”, the host is represented by the IP address 192.168.0.1.
The host component is essential for locating and accessing web resources. It acts as a bridge between the user’s browser and the server that hosts the desired content. By identifying the correct host, users can establish connections, retrieve data, and interact with websites seamlessly.
Path
The path component of a URL specifies the specific location or file on the server that the URL is pointing to. It represents the directory structure or a specific file name within the website structure.
The path component follows the domain name or IP address in the URL and is separated by a forward slash (/). It can include multiple levels of directories, representing the hierarchical structure of the website’s file system.
For example, in the URL “https://www.example.com/blog/article.html”, the path is “/blog/article.html”. It indicates that the desired resource is located in the “blog” directory and the file name is “article.html”.
Paths can be relative or absolute. A relative path specifies the location of a resource relative to the current page or directory. It does not include the entire URL but only the necessary path information. For example, if you are on the page “https://www.example.com/blog/”, and you want to link to an image in the same directory, you can use the relative path “image.jpg”.
An absolute path, on the other hand, specifies the complete path from the root of the website. It starts with a forward slash (/) and includes all necessary directory names. For example, using the absolute path “/images/logo.png” would point directly to the “logo.png” file in the “images” directory, regardless of the current directory.
The path component provides a way to navigate through the website’s file structure and locate specific files or directories. It allows users to access different pages, resources, or assets hosted on the server and is an integral part of URL navigation.
Query Parameters
Query parameters are an integral part of a URL and are used to pass additional information to the server. They allow users to specify various parameters and values that modify the behavior or output of a web resource.
Query parameters are added to the end of a URL after a question mark (?) and are separated by ampersands (&) if multiple parameters are present. Each parameter consists of a key-value pair, with the key and value separated by an equal sign (=).
For example, in the URL “https://www.example.com/search?q=keyword&page=2”, the query parameters are “q=keyword” and “page=2”. Here, “q” is the key and “keyword” is the value, and “page” is the key with a value of “2”.
Query parameters serve different purposes depending on the website or application. They can be used for search queries, filtering options, pagination, language preferences, and much more. They provide a flexible way to customize and personalize the user experience.
When a user enters a search query into a search engine, such as “https://www.example.com/search?q=keyword”, the query parameter “q” is used to pass the search keyword to the server. The server then uses this information to retrieve relevant search results.
Query parameters are often dynamically generated by web applications and can change based on user inputs or application logic. They provide a way to interact with the server and retrieve specific information tailored to the user’s needs.
Developers can access query parameters using server-side programming languages or JavaScript on the client side. They can extract and process the parameter values to perform specific operations or generate dynamic content.
Overall, query parameters expand the functionality and interactivity of websites by allowing users to customize their experience and provide valuable input to the server.
Fragment Identifier
The fragment identifier is a component of a URL that is used to point to a specific section within a webpage. It is indicated by a hash symbol (#) followed by the fragment identifier itself.
The fragment identifier is primarily used by browsers to determine where to scroll the page when the URL is accessed. When a user clicks on a URL with a fragment identifier or manually enters a URL with a specific fragment identifier, the browser will automatically scroll to the corresponding section of the webpage.
For example, in the URL “https://www.example.com#section3”, the fragment identifier is “section3”. When the URL is accessed, the browser will scroll to the section of the webpage that has the corresponding “section3” id or name. This is particularly useful for long webpages or websites with multiple sections or subsections.
Web developers can assign unique identifiers or names to different sections of a webpage using HTML’s ID or NAME attributes. These identifiers can then be used as fragment identifiers in URLs to pinpoint specific sections.
Fragment identifiers are often used in conjunction with navigation menus or table of contents within a webpage. They allow users to quickly jump to a specific section without manually scrolling through the entire page.
In addition to scrolling within the same page, fragment identifiers can also be used to navigate between different pages or locations on a website. For example, clicking on an anchor link with a fragment identifier within a webpage can take the user to another page and scroll to the corresponding section.
It’s important to note that fragment identifiers are processed entirely on the client side and are not sent to the server. They are used solely for navigation and presentation purposes within the browser.
Fragment identifiers provide a convenient way to navigate within webpages and quickly access specific sections or content. They enhance the user experience and make it easier to locate and consume information on websites.
Common URL Schemes
URL schemes are an essential part of a URL as they determine how the resource should be accessed. Here are some of the commonly used URL schemes:
- HTTP (Hypertext Transfer Protocol): HTTP is the most prevalent URL scheme and is used for fetching web resources from servers. It allows users to access web pages, images, videos, and other content on the internet. URLs with the HTTP scheme begin with “http://”.
- HTTPS (Hypertext Transfer Protocol Secure): HTTPS is a secure version of HTTP that encrypts the data being transmitted between a client and a server. It provides enhanced security and privacy for transactions, online forms, and sensitive information. URLs with the HTTPS scheme start with “https://”.
- FTP (File Transfer Protocol): FTP is a protocol used for transferring files between a client and a server. It is particularly useful for managing website files, uploading or downloading large files, and accessing remote file repositories. URLs with the FTP scheme begin with “ftp://”.
- File: The file scheme is used to access files on the local file system. It is commonly used for opening local HTML or text files directly in a browser or accessing files stored on the device. File URLs begin with “file://”.
- Mailto: The mailto scheme allows users to create an email message by clicking on a link. When clicked, it opens the default email client with the recipient’s email address pre-filled. Mailto URLs begin with “mailto:”.
- Tel: The tel scheme is used for initiating phone calls by clicking on a link. When clicked, it prompts the device to make a call to the specified phone number. Tel URLs begin with “tel:”.
These are just a few examples of the common URL schemes used on the internet. Each scheme serves a different purpose and facilitates various types of communication and resource retrieval.
Understanding these URL schemes allows users to navigate the web, access resources, and interact with different online services effectively. It also enables developers to implement proper URL handling and ensure seamless user experiences across various platforms and devices.
Parts of a URL in Action
Understanding the different components of a URL and how they work together is essential for effectively navigating the web. Let’s take a closer look at how the various parts of a URL come into play:
Imagine you want to visit a news website to read an article titled “Top 10 Travel Destinations.”
The URL for the article might look like this:
https://www.example.com/articles/top-10-travel-destinations
– The scheme in this case is “https://,” indicating that you will be accessing the resource over a secure version of HTTP.
– The host is “www.example.com,” specifying the domain name of the server where the website is hosted.
– The path component is “/articles/top-10-travel-destinations,” revealing the location of the article within the website’s directory structure.
In this scenario, there are no query parameters or fragment identifier used. But let’s say you want to filter the article based on a specific category, such as “beach destinations.”
The modified URL might look like this:
https://www.example.com/articles/top-10-travel-destinations?category=beach
– The query parameter in this case is “category=beach,” allowing the server to understand that you are requesting to filter the article by the category “beach.” The question mark (?) indicates the beginning of the query parameters, while the equal sign (=) separates the key (“category”) from the value (“beach”). Multiple parameters can be added and separated by ampersands (&).
Now let’s say you want to jump directly to the section of the article that discusses a specific country, such as “Bali.”
The modified URL might look like this:
https://www.example.com/articles/top-10-travel-destinations?category=beach#bali
– The fragment identifier in this case is “bali,” denoting the specific section within the article. The hash symbol (#) is used to indicate the fragment identifier, which directs the browser to scroll to the corresponding section on the webpage.
By understanding the different parts of a URL and how they are used, you can navigate websites effectively, access specific resources, and customize your browsing experience.
URL Encoding
URL encoding, also known as percent encoding, is a technique used to represent special characters and non-ASCII characters in a URL. Since URLs can only contain a limited set of characters, any characters outside this range must be encoded to ensure they are transmitted correctly and interpreted properly by web servers and browsers.
URL encoding works by replacing non-alphanumeric characters with a “%” sign followed by two hexadecimal digits that represent the character’s ASCII code. For example, a space character (“%20”), an exclamation mark (“%21”), or a question mark (“%3F”) would be URL-encoded accordingly.
URL encoding is commonly used for parameters within a URL. In query strings, special characters such as spaces, ampersands, and equals signs need to be encoded so that the resulting URL is valid and the server can parse the parameters correctly.
For example, suppose you want to search for “blue shoes” using a search engine. The URL for the search might look like this:
https://www.example.com/search?q=blue%20shoes
In this example, the space between “blue” and “shoes” is replaced with “%20” to conform to URL encoding standards. When the browser sends this URL to the server, it will correctly interpret the search parameter as “blue shoes” and return relevant search results.
URL encoding is particularly important when dealing with non-ASCII characters, such as accented letters or characters from non-Latin scripts. These characters need to be encoded using UTF-8 or another encoding scheme to maintain the integrity of the URL and ensure proper interpretation by servers and browsers.
URL encoding is a crucial aspect of web development to handle special characters and maintain URL validity and consistency. It ensures that URLs are correctly transmitted, processed, and interpreted across different systems, browsers, and languages.
URL Shortening
URL shortening is a process in which a long URL is converted into a shorter and more manageable version. It is commonly used to create concise and shareable links, especially on platforms like social media, where character count is limited.
URL shortening services take a long URL as input and generate a shortened URL that redirects to the original destination. These services assign a unique identifier to the original URL and map it to the shortened version.
Shortened URLs are beneficial in many ways:
- Convenience: Shortened URLs are easier to read, type, and remember, making them more user-friendly. They can be quickly shared in emails, messages, and social media posts without taking up too much space or causing formatting issues.
- Tracking and Analytics: Most URL shortening services provide analytics features that allow users to track click-through rates, monitor traffic sources, and measure the effectiveness of marketing campaigns. This data helps businesses gain valuable insights into user behavior and optimize their online efforts.
- Customization: Some URL shortening services allow users to customize their shortened URLs with preferred keywords or branded slugs. This branding opportunity can enhance brand recognition and improve the click-through rates on shared links.
- Security: URL shortening services often include security features, such as link expiration or password protection, which can be useful when sharing sensitive or time-limited information.
However, it’s important to note that URL shortening also has potential downsides:
- Link Rot: Shortened URLs are susceptible to link rot, which occurs when the destination URL becomes inaccessible or outdated. If the URL shortening service shuts down or the link expires, the shortened URL may no longer redirect users to the intended destination.
- Lack of Transparency: Shortened URLs can hide the actual destination, making it difficult for users to determine where the link will lead them. This lack of transparency can potentially be exploited by malicious actors to distribute spam, malware, or phishing attacks.
URL shortening has become an integral part of online communication and marketing, providing a convenient way to share and track links. When using shortened URLs, it is essential to choose a reliable and reputable URL shortening service and ensure that the original destination is trustworthy and safe.
Common URL Problems and How to Fix Them
URLs play a crucial role in web browsing, but they can encounter various issues that may hinder a smooth user experience. Here are some common URL problems and how to address them:
1. Broken Links: Broken links occur when a URL leads to a webpage or resource that no longer exists or has been moved. To fix broken links, web administrators should regularly check for broken links using online tools or plugins and update or redirect the URLs to the correct destinations.
2. URL Redirection Loops: A redirection loop occurs when a URL points to another URL, which then redirects back to the original URL, creating an endless loop. This can result in an error message or browser timeout. To fix redirection loops, web administrators should review the redirection rules and ensure they are properly configured to avoid circular redirects.
3. Long and Unfriendly URLs: URLs that are excessively long or contain complex query strings can be difficult to read, share, or remember. To address this issue, developers can use URL rewriting techniques to create shorter, more user-friendly URLs. This involves mapping user-friendly URLs to their corresponding longer URLs, making them easier to navigate and share.
4. URL Case Sensitivity: URLs are case-sensitive, meaning uppercase and lowercase letters are treated differently. If a URL is improperly typed or linked with incorrect letter casing, users may encounter 404 errors or be directed to incorrect pages. To resolve this problem, developers should ensure that URLs are consistently typed and linked with the correct letter casing to avoid confusion and errors.
5. URL Encoding Issues: Special characters or non-ASCII characters in a URL may cause encoding issues and result in incorrect interpretation by servers and browsers. To fix URL encoding problems, developers should use proper URL encoding techniques, such as the percent-encoding method, to encode special characters correctly. This ensures that the URL is transmitted and processed accurately.
6. Unsecured URLs: URLs that use the unsecured HTTP protocol instead of HTTPS can pose security risks, potentially exposing user data to interception or tampering. To enhance security, it is important to implement SSL/TLS certificates and use HTTPS URLs to encrypt data transmission and protect user privacy.
Regularly monitoring and maintaining URLs is crucial for delivering a seamless browsing experience. By addressing common URL problems promptly, website owners can ensure that URLs are functional, user-friendly, and secure.
Summary
Understanding the different components of a URL is essential for effectively navigating the web and accessing resources. Here’s a summary of what we’ve covered:
A URL (Uniform Resource Locator) is a string of characters that identifies the address of a resource on the internet. It consists of various components that provide specific information about the location and type of resource being accessed.
The key components of a URL include:
- Scheme: The protocol or scheme indicates how the resource should be accessed, such as HTTP or HTTPS.
- Host: The host specifies the domain name or IP address of the server where the resource is located.
- Path: The path refers to the specific location or file on the server that the URL is pointing to.
- Query Parameters: Query parameters pass additional information to the server and modify the behavior or output of a resource.
- Fragment Identifier: The fragment identifier points to a specific section within a webpage.
URL encoding is used to represent special characters and non-ASCII characters in a URL, ensuring proper transmission and interpretation by servers and browsers.
URL shortening is a technique that creates shortened versions of long URLs, allowing for easier sharing and tracking of links. It is particularly useful when character count is limited, such as on social media platforms.
However, it’s important to be aware of common URL problems, such as broken links, redirection loops, long and unfriendly URLs, URL case sensitivity, URL encoding issues, and unsecured URLs. Regular monitoring and maintenance of URLs helps ensure a smooth browsing experience.
By understanding and effectively utilizing URLs, both users and web developers can navigate the web efficiently, access resources accurately, and enhance the overall browsing experience.