
What is the Isolation Property?
The isolation property refers to the ability of a database system to maintain data consistency and integrity despite concurrent transactions. In a multi-user environment, where multiple users access and modify the same data simultaneously, it is crucial to ensure that each transaction is isolated from others to prevent interference and maintain data accuracy.
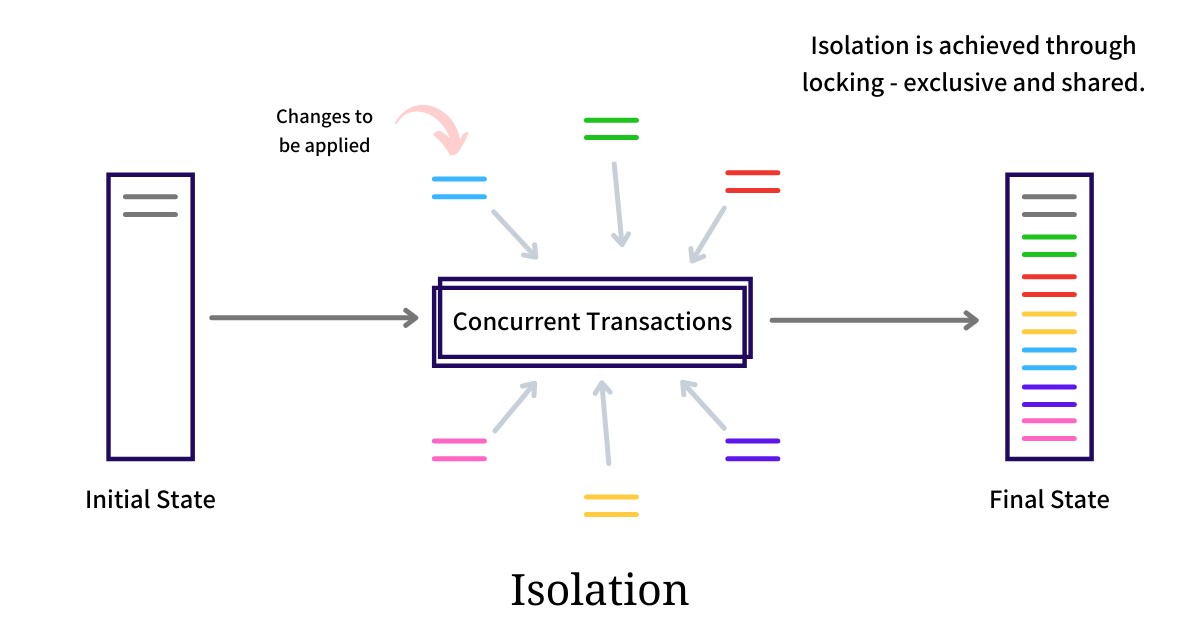
Isolation is one of the ACID (Atomicity, Consistency, Isolation, Durability) properties that are fundamental for reliable and secure database operations. It guarantees that each transaction is executed independently and in isolation from other transactions, as if it were the only transaction in the system.
The isolation property ensures that a transaction’s intermediate state remains invisible to other transactions until it is committed. This prevents dirty reads, non-repeatable reads, and phantom reads, which can lead to data inconsistencies and incorrect results.
Isolation is achieved through various mechanisms, such as locking, concurrent control protocols, and transaction isolation levels. These mechanisms define the degree of isolation and the level of concurrency permitted in a database system.
By enforcing the isolation property, a database system ensures that each transaction executes as if it were the only one running, even in a highly concurrent environment. This guarantees data integrity and consistency, enabling applications to process transactions reliably and accurately.
Why is the Isolation Property important?
The isolation property plays a vital role in ensuring the reliability, consistency, and integrity of data in a database system. Here are some reasons why the isolation property is important:
- Data Consistency: The isolation property prevents concurrent transactions from interfering with each other, thereby maintaining data consistency. It ensures that each transaction sees a consistent view of the database, without being affected by the changes made by other transactions.
- Concurrency Control: In a multi-user environment, where multiple transactions are executed simultaneously, concurrency control is crucial. The isolation property allows concurrent transactions to execute independently, preventing conflicts and ensuring that the final outcome is as if transactions were executed serially.
- Data Integrity: By maintaining isolation, the database system protects the integrity of the data. It prevents dirty reads, where a transaction reads uncommitted data, and non-repeatable reads, where a transaction reads different values of the same data item within a single transaction.
- Phantom Protection: The isolation property guards against phantom reads, which occur when a transaction repeats a query and obtains a different set of rows due to the insertion or deletion of rows by other concurrent transactions. Isolation prevents phantom reads, ensuring a predictable and consistent result.
- Correctness of Results: By ensuring proper isolation, the database system guarantees that the results of each transaction are correct and valid. This is crucial for applications that rely on accurate data, such as financial systems or e-commerce platforms.
Understanding Different Levels of Isolation
Database systems offer different levels or modes of isolation to provide developers and administrators with flexibility in balancing data consistency, concurrency, and performance. Let’s explore some common levels of isolation:
- Read Uncommitted: This is the lowest level of isolation where transactions can read data modified by other concurrent transactions, even if those changes are not yet committed. It allows dirty reads, non-repeatable reads, and phantom reads, which can lead to data inconsistencies.
- Read Committed: In this isolation level, a transaction can only read data that has been committed by other transactions. It avoids dirty reads by ensuring that changes made by other uncommitted transactions are not visible. However, non-repeatable reads and phantom reads can still occur.
- Repeatable Read: This level guarantees that within a transaction, the same query will always return the same set of rows. It prevents non-repeatable reads, where a query retrieves different results within the same transaction. However, phantom reads can still occur due to concurrent insertions or deletions.
- Serializable: This is the highest level of isolation that ensures strict transaction isolation. It guarantees that concurrent transactions will not cause any data inconsistencies. Serializable isolation prevents dirty reads, non-repeatable reads, and phantom reads by placing locks on the data, ensuring a serializable execution of transactions.
It’s important to note that as the isolation level increases, the degree of concurrency decreases, which can impact system performance. Choosing the appropriate isolation level depends on the specific requirements of the application, considering factors such as data consistency, concurrency requirements, and system resources.
Database systems also provide mechanisms for setting isolation levels explicitly or implicitly, allowing developers to control the concurrency and consistency guarantees offered by the system.
Read Uncommitted Isolation Level
The Read Uncommitted isolation level, also known as the “dirty read” level, is the lowest level of isolation offered by database systems. In this level, transactions can read data that has been modified by other concurrent transactions, even if those changes have not been committed yet.
This level of isolation allows for a high degree of concurrency but comes with the risk of reading inconsistent and uncommitted data. It means that a transaction may retrieve data that is subsequently rolled back or modified before being committed, resulting in dirty reads.
With the Read Uncommitted isolation level, there is also a possibility of non-repeatable reads. This occurs when a transaction reads the same data multiple times within the same transaction but gets different values each time due to concurrent updates by other transactions.
Additionally, phantom reads can occur in this isolation level. Phantom reads happen when a transaction repeats a query and obtains a different set of rows due to concurrent insertions or deletions by other transactions.
While Read Uncommitted provides high concurrency, it sacrifices data consistency and integrity. It is generally not recommended to use this isolation level in applications that require strict data integrity, as it can lead to erroneous and inconsistent results.
There may be some use cases where Read Uncommitted is acceptable, such as data analysis or reporting scenarios where real-time consistency is not critical. However, for most transactional systems, it is recommended to use higher isolation levels to ensure data integrity and prevent inconsistencies.
Read Committed Isolation Level
The Read Committed isolation level is a higher level of isolation compared to Read Uncommitted. In this level, a transaction can only read data that has been committed by other transactions. It ensures that changes made by uncommitted transactions are not visible to other transactions.
This level of isolation provides a balance between data consistency and concurrency. It avoids the problem of dirty reads associated with the Read Uncommitted level, ensuring that only committed data is accessible to transactions.
However, Read Committed still allows for the possibility of non-repeatable reads. Non-repeatable reads occur when a transaction reads the same data multiple times within the same transaction but gets different values each time due to the committed updates by other concurrent transactions.
Unlike Read Uncommitted, Read Committed provides a higher degree of data integrity and consistency. It ensures that only consistent and committed data is accessed by transactions, reducing the risk of obtaining incorrect or unreliable results.
Phantom reads can still occur in the Read Committed isolation level. This happens when a transaction repeats a query and obtains a different set of rows due to concurrent insertions or deletions by other transactions. However, phantom reads are less likely to occur compared to the lower isolation levels.
Read Committed is a commonly used isolation level in many database systems. It offers a good balance between data consistency and concurrency, making it suitable for most transactional applications. However, it is important to keep in mind that it still allows for non-repeatable reads and phantom reads, which might need to be considered when designing and developing applications.
Repeatable Read Isolation Level
The Repeatable Read isolation level provides a higher level of consistency compared to Read Committed. In this level, a transaction ensures that the data it reads remains unchanged, even if other transactions modify the same data concurrently.
With Repeatable Read, once a transaction reads a data item, it maintains the same value throughout its duration, regardless of any changes made by other transactions. This prevents non-repeatable reads, where a transaction reads different values of the same data item within a single transaction.
Unlike Read Committed, Repeatable Read also offers protection against phantom reads. Phantom reads can occur when a transaction repeats a query and obtains a different set of rows due to concurrent insertions or deletions. With Repeatable Read, the result of a query remains consistent throughout the transaction, preventing phantom reads.
This level of isolation achieves data consistency by using shared locking mechanisms. When a transaction reads a data item, it acquires a shared lock on it, preventing other transactions from modifying it until the current transaction completes. This ensures that the data remains consistent and doesn’t change during the transaction’s execution.
While Repeatable Read offers a higher level of consistency, it also reduces the degree of concurrency. Transactions that need to modify the same data item would be blocked by the shared locks held by the reading transactions. This can potentially impact system performance in high concurrent environments.
Repeatable Read is commonly used in applications where data consistency is crucial, such as financial systems or inventory management systems. It provides a higher level of data integrity and ensures that the results of queries and calculations remain consistent throughout the transaction.
It’s important to note that although Repeatable Read prevents non-repeatable reads and phantom reads, it does not guarantee that the data read will remain unchanged until the end of the transaction. To achieve strict data integrity and prevent any modifications, the Serializable isolation level should be considered.
Serializable Isolation Level
The Serializable isolation level is the highest level of isolation offered by database systems. It ensures the strictest form of data consistency and integrity by preventing all forms of concurrency-related anomalies, including dirty reads, non-repeatable reads, and phantom reads.
In the Serializable isolation level, transactions are executed as if they were running in isolation, in a sequential manner. Each transaction acquires exclusive locks on the data it accesses, preventing other transactions from modifying the same data until the current transaction completes.
This level of isolation guarantees that the result of a query remains consistent throughout the transaction. Once a transaction reads a data item, it ensures that the value remains unchanged, even if other transactions attempt to modify the same data concurrently.
By using strict locking mechanisms and ensuring exclusive access to the data, the Serializable isolation level eliminates all possibilities of data inconsistency. It provides the highest level of data integrity, making it suitable for applications that require precise and accurate data.
However, the Serializable isolation level comes at the cost of reduced concurrency. The use of exclusive locks can lead to increased contention and potential performance degradation, particularly in highly concurrent systems. Therefore, it is important to carefully consider the trade-off between data consistency and system performance.
Serializable isolation is commonly used in applications that involve critical transactions, such as financial systems, where data integrity and consistency are of utmost importance. By enforcing strict isolation guarantees, it ensures that the data remains in a consistent state and provides reliable results for complex and highly transactional operations.
It’s important to note that while the Serializable isolation level eliminates concurrency-related anomalies, it does not completely eliminate all potential issues, such as deadlocks. Careful consideration and analysis of the application’s requirements and transactional patterns are necessary to ensure the appropriate use of the Serializable isolation level.
Common Issues and Challenges with the Isolation Property
While the isolation property is crucial for data consistency and integrity, there are some common issues and challenges that can arise when managing it in a database system:
- Concurrency Control: Balancing data consistency and concurrency can be challenging. Stricter isolation levels, such as Serializable, can limit concurrency and impact system performance due to increased lock contention. Finding the right balance between isolation and performance is crucial for optimizing database operations.
- Deadlocks: Deadlocks occur when two or more transactions are waiting for each other to release resources, resulting in a circular dependency. Deadlocks can cause system slowdowns or even system crashes. Implementing deadlock detection and resolution mechanisms is necessary to mitigate the impact of deadlocks.
- Isolation Levels and Data Integrity: Selecting the appropriate isolation level is important to ensure data integrity in a database system. Higher isolation levels, such as Serializable, offer stronger guarantees of data consistency but can affect system performance. Determining the right isolation level based on the application’s requirements is essential for balancing consistency and performance.
- Concurrent Modifications: When multiple transactions attempt to modify the same data concurrently, conflicts can arise. Techniques such as locking, timestamps, or optimistic concurrency control need to be implemented to handle concurrent modifications and maintain the integrity of the data.
- Isolation Anomalies: Even with appropriate isolation levels, certain anomalies can still occur. These include dirty reads, non-repeatable reads, and phantom reads. Understanding and mitigating these anomalies through proper transaction design and isolation level selection are important to maintain consistent and reliable data.
- Performance Impact: Stricter isolation levels can have a performance impact due to increased locking and reduced concurrency. It is important to analyze the application’s requirements and workload to determine the optimal balance between data consistency and system performance.
Managing the isolation property in a database system requires careful consideration of these issues and challenges. By understanding and addressing them effectively, database administrators and developers can ensure data consistency, integrity, and optimal performance in their applications.
Benefits and Drawbacks of Different Isolation Levels
Different isolation levels in a database system offer varying benefits and drawbacks. Let’s explore some of the key advantages and disadvantages of each isolation level:
- Read Uncommitted: The major benefit of Read Uncommitted is high concurrency, allowing multiple transactions to read and modify data simultaneously. However, the drawback is the lack of data consistency, as it permits dirty reads, non-repeatable reads, and phantom reads. It is suitable for scenarios where real-time consistency is not critical, such as data analysis or reporting.
- Read Committed: Read Committed provides better data consistency compared to Read Uncommitted by preventing dirty reads. However, it still allows non-repeatable reads and phantom reads. It strikes a balance between data consistency and concurrency, making it suitable for most transactional applications.
- Repeatable Read: Repeatable Read offers higher data consistency by preventing non-repeatable reads within a transaction. It also reduces the possibility of phantom reads. However, it comes at the cost of reduced concurrency due to shared locking. It is suitable for applications requiring strong data consistency, such as financial systems or inventory management.
- Serializable: Serializable provides the strongest level of data consistency by preventing all anomalies, including dirty reads, non-repeatable reads, and phantom reads. However, it significantly reduces concurrency and can lead to increased lock contention, impacting system performance. It is suitable for critical transactional applications where data integrity is of utmost importance.
Choosing the appropriate isolation level depends on the specific requirements of the application. Here’s a summary of considerations for selecting an isolation level:
- Data Consistency: Consider the level of data consistency needed for the application. If strict consistency is paramount, higher isolation levels like Repeatable Read or Serializable may be more appropriate.
- Concurrency Requirements: Evaluate the concurrency needs of the application. If high concurrency is essential, lower isolation levels, like Read Uncommitted or Read Committed, can be selected to maximize concurrent access.
- System Performance: Assess the impact on system performance. Stricter isolation levels can have higher overhead due to increased locking and reduced concurrency. Consider the trade-off between data consistency and performance to choose the optimal isolation level.
- Application Domain: Consider the nature of the application and the sensitivity of the data. Critical applications, such as financial systems, may require higher levels of data consistency to ensure accurate and reliable results.
Understanding the benefits and drawbacks of different isolation levels is crucial for selecting the appropriate level that aligns with the application’s requirements while maintaining a balance between data consistency, concurrency, and performance.
Managing Isolation Levels in Database Systems
Managing isolation levels in a database system involves setting the appropriate level for each transaction and configuring the system to enforce the chosen level. Here are key considerations and strategies for effectively managing isolation levels:
- Understanding Application Requirements: Gain a thorough understanding of the application’s data consistency, concurrency, and performance requirements. Analyze the criticality of the data and the nature of transactions to determine the most suitable isolation level.
- Configuring Default Isolation Level: Set a default isolation level for the database system. This default level will be applied to all transactions that do not explicitly specify an isolation level. Carefully consider the trade-off between data consistency and concurrency when choosing the default level.
- Explicit Isolation Level Control: Provide developers with the ability to explicitly set the isolation level for individual transactions when needed. This allows fine-grained control over the level of consistency and concurrency required for specific operations, allowing customization based on transaction characteristics.
- Monitoring and Tuning: Regularly monitor the performance and behavior of the database system to assess the impact of different isolation levels. Use database profiling tools and performance monitoring to identify and address bottlenecks, lock contention, and other issues related to isolation levels.
- Optimistic Concurrency Control: Consider implementing optimistic concurrency control mechanisms, such as timestamps or row versioning. These mechanisms allow multiple transactions to operate concurrently without acquiring exclusive locks, improving system performance and reducing lock contention.
- Deadlock Detection and Resolution: Implement deadlock detection and resolution mechanisms to handle situations where transactions are waiting for each other’s resources. Use techniques such as timeouts, deadlock graphs, or resource preemption to identify and resolve deadlocks to maintain system availability and performance.
- Testing and Validation: Conduct thorough testing and validation of the chosen isolation levels in the context of the application. Design and execute test cases that simulate real-world scenarios to ensure that the desired level of data consistency, concurrency, and performance is achieved.
Continuous monitoring, performance tuning, and periodic reassessment of isolation levels are essential to adapt to changing application requirements and workload patterns. By effectively managing isolation levels, database administrators and developers can strike the right balance between data consistency, concurrency, and system performance.
Best Practices for Ensuring Data Consistency and Isolation
Ensuring data consistency and isolation in a database system is critical to maintaining the integrity of the data and achieving reliable results. Here are some best practices to follow:
- Choose the Right Isolation Level: Carefully analyze the application’s requirements and select the appropriate isolation level. Consider factors such as data consistency needs, concurrency requirements, and system performance to strike the right balance.
- Use Explicit Transactions: Wrap related database operations in explicit transactions to group them together. This ensures that the operations are executed atomically and provides better control over isolation and data consistency within the transaction.
- Apply Proper Locking Strategies: Use the correct locking mechanisms, such as row-level or table-level locks, to control concurrent access to data. Implement locking strategies that balance data consistency and concurrency, ensuring that transactions don’t interfere with each other while maintaining the integrity of the data.
- Implement Optimistic Concurrency Control: Consider using optimistic concurrency control mechanisms, such as timestamps or row versioning, in scenarios where high concurrency is required. These mechanisms allow multiple transactions to operate concurrently without acquiring exclusive locks, improving system performance and reducing lock contention.
- Handle Deadlocks: Implement deadlock detection and resolution mechanisms to identify and handle deadlock situations. Use techniques such as timeouts, deadlock graphs, or resource preemption to mitigate the impact of deadlocks and maintain system availability.
- Validate Input and Enforce Constraints: Ensure that input data is validated and enforce appropriate constraints to maintain data integrity. Implement proper data validation techniques, such as input sanitization and validation rules, to prevent data inconsistencies caused by erroneous or malicious input.
- Monitor Performance and Optimizations: Regularly monitor and analyze the performance of the database system. Use performance profiling tools and techniques to identify and address bottlenecks, lock contention, or other issues related to isolation and data consistency. Implement optimizations based on these findings to improve system performance.
- Test and Validate: Conduct thorough testing and validation of the database system’s behavior under different workload scenarios. Design and execute test cases that simulate real-world scenarios to ensure that the desired level of data consistency and isolation is achieved. Validate the accuracy and reliability of the data and make necessary adjustments if required.
By following these best practices, database administrators and developers can ensure data consistency, maintain isolation, and achieve reliable results in their database systems.