
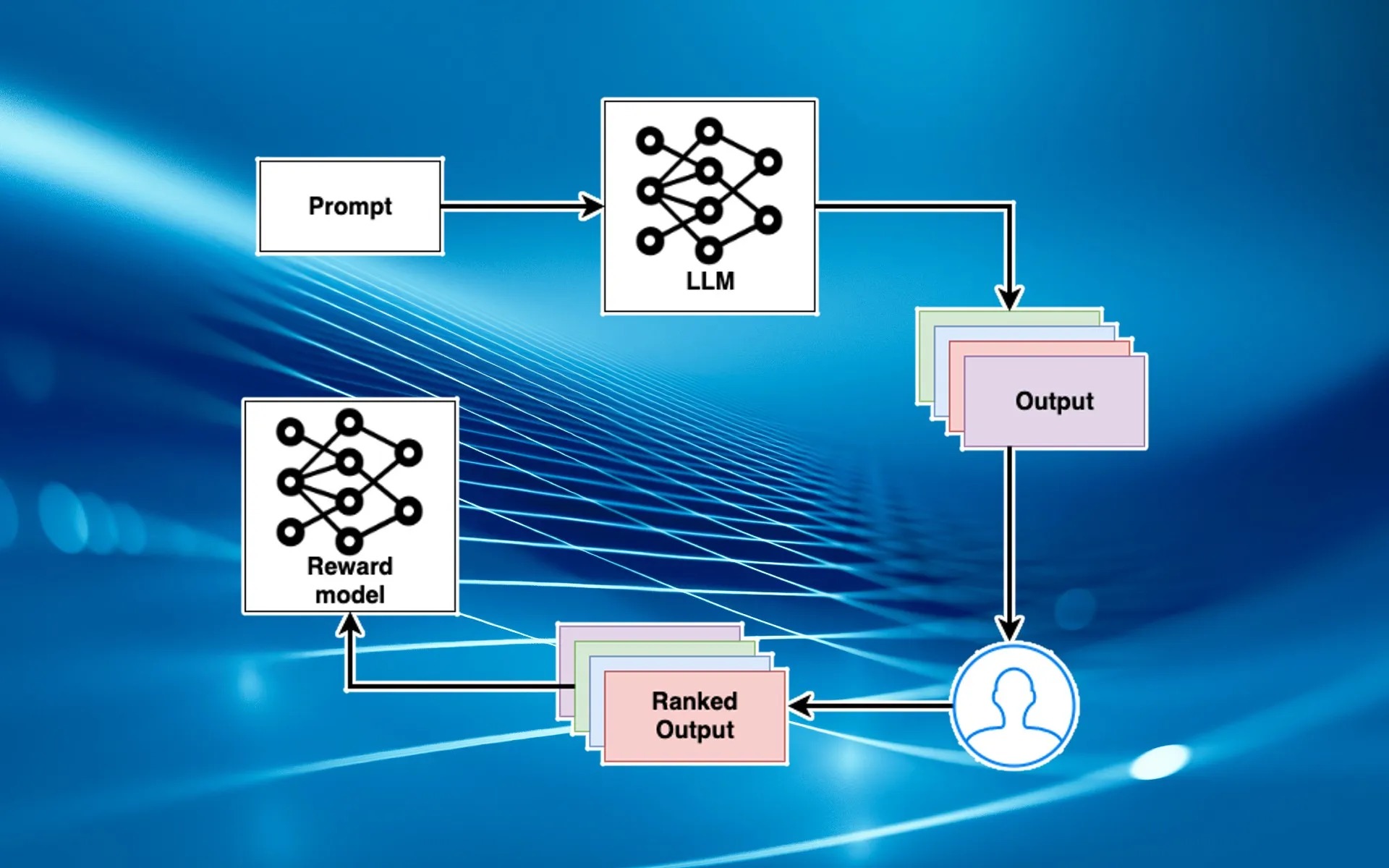
What is LLM?
LLM, which stands for Latent Language Model, is a powerful concept in the field of machine learning that aims to enhance natural language understanding and generation. It is a subfield of artificial intelligence that focuses on analyzing and predicting patterns in text data, enabling machines to comprehend human language more effectively.
At its core, LLM involves creating mathematical models capable of inferring meaning from language, even when faced with ambiguity and context-dependent nuances. These models leverage a vast amount of textual data to learn patterns, relationships, and semantics, in order to generate accurate and coherent responses. LLM algorithms allow machines to understand and respond to human queries with human-like comprehension, opening the door to countless applications in various industries.
LLM has its roots in the field of statistical natural language processing (NLP). While traditional NLP systems required explicit rules and extensive manual feature engineering, LLM algorithms employ deep learning techniques to automatically learn these patterns from large-scale text corpora. This data-driven approach enables LLM models to generalize and adapt to different languages, domains, and contexts, making them highly versatile.
One of the key components of LLM is the use of neural networks, specifically recurrent neural networks (RNNs). RNNs are designed to handle sequential data, making them ideal for modeling language, which inherently exhibits sequential dependencies. By utilizing this architecture, LLM models can capture the dependencies between words, phrases, and sentences, enabling them to generate contextually relevant responses.
LLM has revolutionized several aspects of natural language processing, including machine translation, sentiment analysis, text summarization, chatbots, and voice assistants. These applications benefit from the ability of LLM models to comprehend and generate human-like language, leading to more accurate and natural interactions between machines and humans.
Moreover, LLM has played a crucial role in advancing the field of natural language understanding. By learning from vast amounts of text data, LLM models can not only identify patterns and semantics but also make intelligent predictions. This capability has paved the way for advancements in question answering systems, information retrieval, and even automated content generation.
Overall, LLM is a cutting-edge approach in machine learning that has transformed the way machines understand and generate human language. Its ability to analyze, learn, and generate text has vast implications for various industries, leading to improved user experiences and revolutionizing the way we interact with technology.
History of LLM in Machine Learning
The concept of LLM in machine learning has a rich history, with significant milestones that have shaped its development and application over the years. The evolution of LLM can be traced back to the emergence of neural networks and the advancements in natural language processing (NLP) techniques.
In the early 2000s, the field of NLP witnessed a paradigm shift with the introduction of recurrent neural networks (RNNs). RNNs, with their ability to capture sequential dependencies, marked a breakthrough in modeling language and paved the way for LLM. These neural network architectures provided the foundation for understanding the contextual relationships between words, enabling machines to generate more cohesive and accurate responses.
As researchers delved deeper into LLM, the concept of word embeddings came into play. Word embeddings are dense vector representations of words that capture semantic relationships. This development revolutionized the way machines understand and generate text data. By leveraging word embeddings, LLM models were able to associate words with their contextual meanings, leading to more nuanced and context-aware language comprehension.
Another major milestone in the history of LLM was the introduction of attention mechanisms. Attention mechanisms allowed the model to focus on specific parts of the input sequence, enhancing its ability to generate coherent and contextually relevant responses. This innovation further improved the performance of LLM models, making them more accurate and efficient.
In recent years, with the advent of large-scale datasets and computing power, the field of LLM has witnessed significant advancements. The introduction of transformer-based models, such as OpenAI’s GPT (Generative Pre-trained Transformer), further elevated the capabilities of LLM. These models, trained on massive amounts of text data, showed remarkable success in generating human-like responses and improving language understanding.
Furthermore, the application of LLM has extended beyond text-based tasks. LLM models have been successfully applied to speech recognition and voice assistants, enhancing the user experience in various applications. These advancements have paved the way for more natural and interactive interactions between machines and humans.
Looking ahead, the history of LLM in machine learning is still being written. Ongoing research and technological advancements continue to push the boundaries of LLM, aiming to achieve even greater accuracy, efficiency, and scalability. The future holds promising developments, including better language generation, improved context understanding, and ethical considerations to address biases and fairness in generated outputs.
How Does LLM Work?
Latent Language Model (LLM) is an innovative approach in machine learning that leverages neural networks and deep learning techniques to enhance natural language understanding and generation. LLM models are designed to learn patterns, relationships, and semantics from large-scale text data, enabling them to comprehend and generate human-like language.
At its core, LLM works by utilizing the power of recurrent neural networks (RNNs) to model sequential dependencies in language. RNNs are ideal for processing language data because they can capture the contextual relationships between words, phrases, and sentences. This allows LLM models to generate coherent and contextually relevant responses when faced with different inputs.
In the training phase, LLM models are exposed to vast amounts of text data, which can include books, articles, social media posts, and other sources of textual information. The models learn from this data by analyzing the patterns and relationships between words and phrases. By doing so, the models build an internal representation of language that enables them to understand and generate text with fluency.
One of the key components of LLM is the concept of word embeddings. Word embeddings are dense vector representations of words that capture their semantic meanings. LLM models use these embeddings to associate words with their contextual information, allowing for more nuanced understanding and generation of language. This enables the models to generate more accurate and contextually relevant responses.
LLM models also make use of attention mechanisms, which allow the model to focus on specific parts of the input sequence. Attention mechanisms enhance the model’s ability to generate responses by attending to relevant context and information. This mechanism contributes to the contextual coherence and relevance of the generated text.
During the inference phase, when a user inputs a query or a prompt, the LLM model processes the input and generates a response based on its learned understanding of language patterns and semantics. The generated response is typically a probabilistic distribution over a set of possible words or phrases, with the most likely response being selected as the output.
It’s important to note that LLM models are not explicitly programmed with rules or predefined responses. Instead, they learn from data, allowing them to generalize and adapt to different contexts and languages. This data-driven approach makes LLM models highly versatile and capable of handling a wide range of natural language processing tasks.
Overall, LLM works by training neural network models to learn from vast amounts of text data, capture the contextual relationships between words, and generate responses that are coherent and contextually relevant. The continuous advancements in LLM research and technology are further improving its capabilities, expanding its applications, and enabling more human-like interactions between machines and humans.
Pros and Cons of LLM
Latent Language Model (LLM) in machine learning offers several advantages and disadvantages that are important to consider when implementing this technology. Understanding the pros and cons of LLM can help guide decision-making and harness its potential effectively.
Pros of LLM:
- Improved Language Understanding: LLM models excel at understanding human language, enabling more accurate and contextually relevant responses. This enhanced language comprehension can greatly benefit various natural language processing tasks.
- Natural Language Generation: LLM models have the ability to generate human-like text, making them valuable for tasks such as automated content generation, chatbots, and voice assistants. This leads to more engaging and interactive user experiences.
- Versatility: LLM models can be trained on vast amounts of text data, making them adaptable to different languages, domains, and contexts. This versatility allows LLM to be applied to various applications and industries.
- Automated Learning: LLM models learn patterns and relationships from data, eliminating the need for explicit rule-based programming. This automated learning process enables the models to generalize and adapt to new data more effectively.
- Enhanced User Experiences: By improving language understanding and generating natural responses, LLM models contribute to more seamless and engaging interactions between machines and humans, resulting in enhanced user experiences.
Cons of LLM:
- Data Dependency: LLM models rely heavily on large-scale text data for training. Insufficient or biased data can lead to inaccuracies and biases in the generated responses, highlighting the importance of quality and diverse training data.
- Computational Resources: Training and running LLM models can require significant computational resources, especially for large-scale models. This can pose challenges in terms of infrastructure and scalability.
- Ethical Concerns: LLM models can inadvertently reproduce biases and unethical content present in the training data. It is crucial to address ethical considerations and ensure fairness, transparency, and accountability in LLM systems to mitigate potential risks.
- Contextual Limitations: While LLM models excel at understanding language within a specific context, they may struggle with understanding nuances and context outside of their training data. This limitation can lead to challenges in dealing with ambiguous or unfamiliar language patterns.
- Human-Like Imperfections: LLM models, despite their impressive capabilities, may still exhibit limitations and imperfections in generating human-like responses. These imperfections can include grammatical errors, incorrect or nonsensical outputs, or misinterpretation of context.
Considering these pros and cons, it is important to carefully evaluate the specific use case, data availability, computational resources, and ethical considerations when implementing LLM in machine learning applications. By leveraging its strengths while mitigating its limitations, LLM can be a powerful tool for enhancing natural language understanding and generation.
Applications of LLM in Machine Learning
Latent Language Model (LLM) in machine learning has a wide range of applications across various industries. The ability of LLM models to understand and generate human-like language has opened doors to innovative solutions and improved user experiences. Here are some notable applications of LLM:
1. Chatbots and Virtual Assistants:
LLM models are extensively used in creating chatbot and virtual assistant systems. These systems leverage the language comprehension and generation capabilities of LLM to provide natural and helpful conversational experiences. Chatbots and virtual assistants powered by LLM can assist users with tasks, answer queries, and guide them through various interactions.
2. Machine Translation:
LLM plays a significant role in machine translation systems. By understanding the semantics and nuances of different languages, LLM models can accurately translate text from one language to another. This application has revolutionized the way language barriers are overcome, enabling global communication and facilitating cross-cultural exchanges.
3. Sentiment Analysis:
LLM models are employed in sentiment analysis, which involves analyzing and understanding the emotions and opinions expressed in text data. By comprehending the context and semantics of language, LLM models can accurately detect and classify sentiments, helping businesses gain insights into customer feedback, product reviews, and social media interactions.
4. Automated Content Generation:
LLM models have been used to automate content generation in various domains. From news articles and product descriptions to creative writing and personalized emails, LLM-powered systems are capable of generating coherent and contextually relevant text. This application not only saves time and effort but also demonstrates the potential for AI to assist in creative endeavors.
5. Question Answering Systems:
LLM has proven valuable in developing question answering systems that can understand and respond to user queries. By drawing upon their language comprehension capabilities, LLM models can provide accurate and relevant answers to a wide range of questions, improving information retrieval and knowledge sharing.
6. Natural Language Understanding:
LLM models contribute to advancing natural language understanding. By learning from vast amounts of text data, LLM models can discern patterns, contexts, and semantic relationships between words and phrases. This understanding enables them to improve information retrieval, language classification, and other language-based tasks.
7. Voice Assistants and Voice Interfaces:
LLM models are used to power voice assistants and voice interfaces, such as smart speakers and voice-controlled devices. These systems rely on LLM to comprehend spoken language, generate appropriate responses, and execute commands. LLM-driven voice interfaces enhance convenience and accessibility in interacting with technology.
These are just a few examples of the wide-ranging applications of LLM in machine learning. As LLM continues to advance, it is likely to find new applications and improve existing ones, further transforming the way machines understand and generate human language.
Challenges in Implementing LLM
While Latent Language Model (LLM) in machine learning offers promising advancements in natural language understanding and generation, there are several challenges that need to be addressed when implementing LLM technology. These challenges can impact the performance, scalability, and ethical considerations of LLM systems. Here are some of the key challenges:
1. Data Availability and Quality:
LLM models heavily rely on large-scale text data for training. Acquiring relevant and diverse data can be a challenge, especially for specialized domains or less-resourced languages. Ensuring the quality and bias-free nature of the training data is also essential to avoid reinforcing biases or producing erroneous outputs.
2. Computational Resources:
The computational resources required to train and run LLM models can be substantial. As the size and complexity of LLM models increase, they may require powerful hardware and infrastructure to achieve optimal performance. Ensuring availability and scalability of computational resources can be a practical challenge for organizations.
3. Ethical Considerations:
LLM models have the potential to inadvertently reproduce biases and unethical content present in the training data. It is crucial to address ethical considerations and ensure fairness, transparency, and accountability in LLM systems. This involves ongoing monitoring, auditing, and mitigation strategies to detect and address biases, promote inclusivity, and mitigate potential risks associated with inappropriate content generation.
4. Contextual Understanding:
LLM models excel at understanding language within a specific context, but they may struggle with understanding nuances and context outside of their training data. Handling ambiguous language, slang, sarcasm, or specific domain-related vocabulary can pose challenges in accurately interpreting user queries and generating appropriate responses.
5. Explainability and Interpretability:
LLM models, especially deep neural network architectures, can be complex and challenging to interpret. The lack of explainability in LLM models makes it difficult to understand the underlying decision-making process. Interpretability and explainability techniques need to be developed and integrated into LLM systems to increase transparency and build trust with users.
6. Control over Output:
LLM models generate text autonomously based on the patterns and relationships learned from the training data. However, ensuring control and alignment with user preferences and organizational guidelines can be a challenge. Balancing the creativity and accuracy of LLM-generated outputs with the desired level of control requires careful consideration and fine-tuning of the model’s parameters.
Addressing these challenges is crucial for the successful implementation of LLM technology. Researchers, developers, and organizations need to collaborate to overcome these hurdles and build robust LLM systems that are not only accurate and efficient but also ethically sound and aligned with the needs and requirements of users.
Ethical Considerations of LLM in Machine Learning
The development and implementation of Latent Language Model (LLM) in machine learning raise important ethical considerations that need to be carefully addressed. While LLM models offer significant advancements in natural language understanding and generation, they can also introduce potential ethical challenges. It is essential to recognize and mitigate these concerns to ensure fairness, transparency, and accountability in LLM systems. Here are some key ethical considerations:
1. Bias and Fairness:
LLM models learn from large-scale text data, which can inadvertently contain biases present in society. If not carefully monitored and addressed, LLM models may perpetuate biases in their generated outputs. Bias detection and mitigation strategies should be implemented to promote fairness and avoid discriminatory or harmful outputs.
2. Privacy and Data Protection:
LLM models rely on access to vast amounts of text data for training. Ensuring data privacy and protection is crucial to maintain user trust and comply with privacy regulations. Organizations must implement robust data governance practices, obtain proper consents, and protect sensitive information when collecting and using data for LLM training.
3. Accountability and Transparency:
LLM models, particularly deep neural network architectures, can be opaque and difficult to interpret. The lack of explainability raises concerns about the accountability of LLM-generated outputs. It is imperative to develop interpretable models, methods, and tools that allow users to understand the decision-making process of LLM models, increasing transparency and enabling accountability.
4. Unintended Consequences:
LLM models have the potential to generate text that may have unintended consequences or harmful effects. The generation of misleading or inaccurate information, hate speech, or offensive content can negatively impact individuals, communities, and society as a whole. Stricter monitoring, risk assessment, and content filtering systems should be implemented to mitigate such risks.
5. User Consent and Control:
Ensuring user consent and control over LLM-generated outputs is crucial. Users should have the ability to opt-out, provide explicit instructions, or invoke constraints on the generated content. Offering transparency in how user-generated data is used and empowering users with greater control can help address concerns related to autonomy and user agency.
6. Algorithmic Bias and Evaluation:
Evaluating and addressing algorithmic biases in LLM models is imperative. Bias detection methods, diverse and representative training datasets, and continuous monitoring are essential to minimize biases and ensure fair and equitable outputs. Regular audits and assessments of LLM systems should be conducted to identify and rectify any biases that may emerge over time.
Addressing these ethical considerations requires collaborative efforts between researchers, developers, policymakers, and stakeholders. Ethical guidelines and standards, along with regulatory frameworks, can help establish a responsible and ethical use of LLM models. By prioritizing fairness, transparency, and accountability, LLM in machine learning can be wielded as a tool that respects societal values and promotes positive impacts on individuals and society as a whole.
Future of LLM in Machine Learning
The future of Latent Language Model (LLM) in machine learning looks promising, with several exciting developments on the horizon. As LLM continues to evolve, it is expected to play a significant role in advancing natural language understanding and generation. Here are some key areas that hold promise for the future of LLM:
1. Improved Language Generation:
LLM models are likely to witness further advancements in generating more coherent, contextually aware, and human-like language. Fine-tuning the training process and incorporating more nuanced linguistic features can lead to more natural and engaging text generation, enabling LLM models to produce outputs that are increasingly difficult to distinguish from human-generated content.
2. Enhanced Context Understanding:
Efforts are underway to enhance the contextual understanding of LLM models. Future research may focus on incorporating external knowledge sources, such as structured data or knowledge graphs, to enhance context awareness. This can enable LLM models to generate responses that have a deeper understanding of the subject matter and more accurately capture specific nuances or domain expertise.
3. Explainable and Interpretable LLM:
The interpretability and explainability of LLM models can be further improved. Developing techniques and methods to provide transparency and insight into the decision-making process of LLM models is essential. This will not only increase users’ understanding and trust in the generated outputs but also help identify and rectify biases or erroneous behaviors.
4. Ethical Implementation:
The ethical considerations surrounding LLM will continue to be a crucial focus. Efforts are needed to address biases, ensure fairness, and promote accountability in the development and deployment of LLM models. Collaboration between academia, industry, policymakers, and ethicists will drive the establishment of guidelines, standards, and regulations to guide the ethical implementation of LLM in machine learning.
5. Domain-Specific LLM:
LLM models tailored for specific domains or industries are likely to emerge. These domain-specific LLM models can be trained on more niche and focused datasets, allowing for more accurate and contextually relevant language generation in specific areas such as legal, medical, or technical fields. This specialization can lead to more efficient and accurate LLM models for domain-specific applications.
6. Advances in Multilingual Understanding:
Further advancements in multilingual understanding are expected in the field of LLM. LLM models will continue to improve their ability to comprehend and generate language in different languages and cultural contexts. This will open doors to more inclusive and diverse applications, facilitating effective communication and collaboration across linguistic boundaries.
The future of LLM in machine learning is bright, with continuous advancements that will make language understanding and generation more sophisticated, ethical, and impactful. These advancements will make LLM models more versatile, capable, and trustworthy, further enhancing the potential for machines to effectively communicate and interact with humans in a manner that closely resembles natural language.