
Definition of a Sigmoid Function
A sigmoid function is a mathematical function that maps any real-valued number to a value between 0 and 1. It is shaped like an “S” curve, characterized by its gradual increase from 0 to 1, with a maximum value of 1 at its center. The term “sigmoid” is derived from the Greek word “σίγμα,” meaning “sigma,” which refers to the sigmoid symbol (σ) used in mathematics.
In machine learning, sigmoid functions are commonly used as activation functions in neural networks and as the basis of logistic regression models. The primary goal of a sigmoid function is to introduce non-linearity into the model, allowing for more complex relationships between input features and the output. This makes sigmoid functions particularly useful in classification tasks where the aim is to predict binary outcomes.
The most well-known sigmoid function is the logistic function, also known as the logistic sigmoid or standard sigmoid. It is defined by the equation:
f(x) = 1 / (1 + e^(-x))
where x is the input value and e is Euler’s number (approximately 2.71828). The logistic function maps any real-valued input to a value ranging between 0 and 1, making it suitable for representing probabilities. As x approaches positive infinity, the output of the logistic function approaches 1, while as x approaches negative infinity, the output approaches 0.
Another popular sigmoid function is the hyperbolic tangent function, often referred to as the tanh function. It can be expressed as:
f(x) = (e^x – e^(-x)) / (e^x + e^(-x))
Similar to the logistic function, the tanh function also maps input values to the range [-1, 1], with values close to -1 for large negative inputs and values close to 1 for large positive inputs.
Sigmoid functions play a crucial role in various machine learning algorithms, enabling the modeling of non-linear relationships and aiding in classification and prediction tasks. Understanding the concept and properties of sigmoid functions is essential for effectively utilizing them in the field of machine learning.
Why Use a Sigmoid Function in Machine Learning?
In machine learning, the choice of activation function is a critical aspect of building effective models. One of the primary reasons to use a sigmoid function is its ability to introduce non-linearity in the model. Let’s explore some key reasons why sigmoid functions are widely used in machine learning:
- Binary Classification: Sigmoid functions are particularly useful when dealing with binary classification problems, where the aim is to predict one of two possible outcomes. By mapping the input values to a range of 0 to 1, sigmoid functions can be interpreted as probabilities, making them well-suited for estimating the likelihood of a binary event occurring.
- Smooth and Differentiable: Sigmoid functions have a smooth and continuous shape, which makes them differentiable at all points. This property is critical for optimization algorithms used in training machine learning models, such as gradient descent. The smoothness of sigmoid functions allows for efficient computation of gradients, enabling the model to learn from data and update its parameters effectively.
- Interpretability: Sigmoid functions can provide interpretable outputs. Since they map inputs to a range of 0 to 1, the output can be interpreted as a probability or a confidence score. This makes it easier to interpret the model’s predictions and make informed decisions based on the estimated probabilities.
- Sigmoid Activation in Neural Networks: Sigmoid functions can be used as activation functions in neural networks. By introducing non-linearity, sigmoid activations allow neural networks to learn complex patterns and relationships in the data. However, it is worth noting that sigmoid activations have limitations, such as the vanishing gradient problem, which can affect training in deeper neural networks.
- Controlled Output Range: Sigmoid functions have a bounded output range of 0 to 1. This property can be advantageous in certain applications, where it is necessary to restrict the output values within a specific range. For example, when predicting probabilities or when dealing with data that has inherent constraints.
Overall, sigmoid functions offer several advantages in machine learning, particularly in binary classification tasks and neural network architectures. Their ability to introduce non-linearity, smoothness, interpretability, and controlled output range make them a popular choice among researchers and practitioners in the field of machine learning.
Properties of a Sigmoid Function
Sigmoid functions possess several important properties that make them suitable for various tasks in machine learning. Let’s explore some of the key properties of sigmoid functions:
- Mapping to a Limited Range: One of the primary properties of sigmoid functions is that they map their input values to a limited range, typically between 0 and 1. This property is crucial in tasks such as binary classification, where the output should represent probabilities or likelihoods.
- Smoothness: Sigmoid functions have a smooth and continuous curve. This smoothness allows for gradient-based optimization algorithms, like gradient descent, to efficiently update the model’s parameters during training. The absence of sudden jumps or discontinuities makes sigmoid functions amenable to iterative optimization processes.
- Monotonicity: Sigmoid functions are monotonically increasing or decreasing over their entire range. This means that as the input values increase, the output will also increase (or decrease) consistently. This property enables sigmoid functions to capture relationships between input features and output targets in a more predictable and interpretable manner.
- Non-Linearity: Sigmoid functions introduce non-linearity into machine learning models. This non-linear behavior is vital for capturing complex patterns and relationships in the data that would otherwise not be possible with linear functions. The non-linear nature of sigmoid functions allows models to learn diverse decision boundaries and represent complex decision-making processes.
- Easy Differentiability: Sigmoid functions are differentiable at all points, making them suitable for optimization algorithms that rely on computing gradients. The ability to compute derivatives efficiently is crucial for training machine learning models using techniques such as gradient descent.
- Centered Around Zero: Some sigmoid functions, such as the hyperbolic tangent (tanh), are centered around zero. This property allows for better handling of positive and negative values, making them useful in tasks where symmetric behavior is desired or when dealing with data with mean-zero normalization.
Understanding the properties of sigmoid functions is key to leveraging their strengths in various machine learning applications. From their limited range mapping and smoothness to their non-linearity and differentiability, these properties enable sigmoid functions to capture complex relationships in the data and make accurate predictions.
Types of Sigmoid Functions
Sigmoid functions come in various forms, each with its own characteristics and applications. Let’s explore some of the commonly used types of sigmoid functions:
- Logistic Sigmoid: The logistic sigmoid function, often referred to simply as the sigmoid function, is one of the most widely used types. It is defined by the equation f(x) = 1 / (1 + e^(-x)). The logistic sigmoid maps the input values to a range between 0 and 1, and its rapid increase around zero makes it suitable for representing probabilities. It is commonly used in logistic regression and as an activation function in neural networks.
- Hyperbolic Tangent (tanh): The hyperbolic tangent function, commonly denoted as tanh, is another type of sigmoid function. It is defined by the equation f(x) = (e^x – e^(-x)) / (e^x + e^(-x)). The tanh function maps the input values to a range between -1 and 1, and it is symmetric around the origin. The tanh function is often used as an activation function in neural networks, offering advantages in certain scenarios where values centered around zero are desired.
- Arc tangent (atan): The arc tangent function, also known as atan, is another sigmoid function used in machine learning. It is defined by the inverse of the tangent function, and it maps input values to a range between -π/2 and π/2. The atan function is often used in applications where the output needs to be limited within a specific range, or when dealing with angles or orientation estimation.
- Hard Sigmoid: The hard sigmoid function is a simplified approximation of the logistic sigmoid. It is defined by a piecewise linear function that introduces a threshold and a slope. The hard sigmoid provides a compromise between computational efficiency and maintaining some non-linear behavior. It is commonly used in applications where fast computations are crucial, such as low-power embedded systems.
These are just a few examples of the types of sigmoid functions commonly used in machine learning. Each type offers unique properties and characteristics that make them suitable for different scenarios. The choice of which sigmoid function to use depends on the specific requirements of the problem at hand and the desired behavior of the model.
Logistic Regression and Sigmoid Function
Logistic regression is a popular machine learning algorithm used for binary classification tasks. It revolves around the use of a sigmoid function, typically the logistic sigmoid, in order to model the relationship between the input features and the target variable. Let’s delve into how logistic regression and the sigmoid function work together:
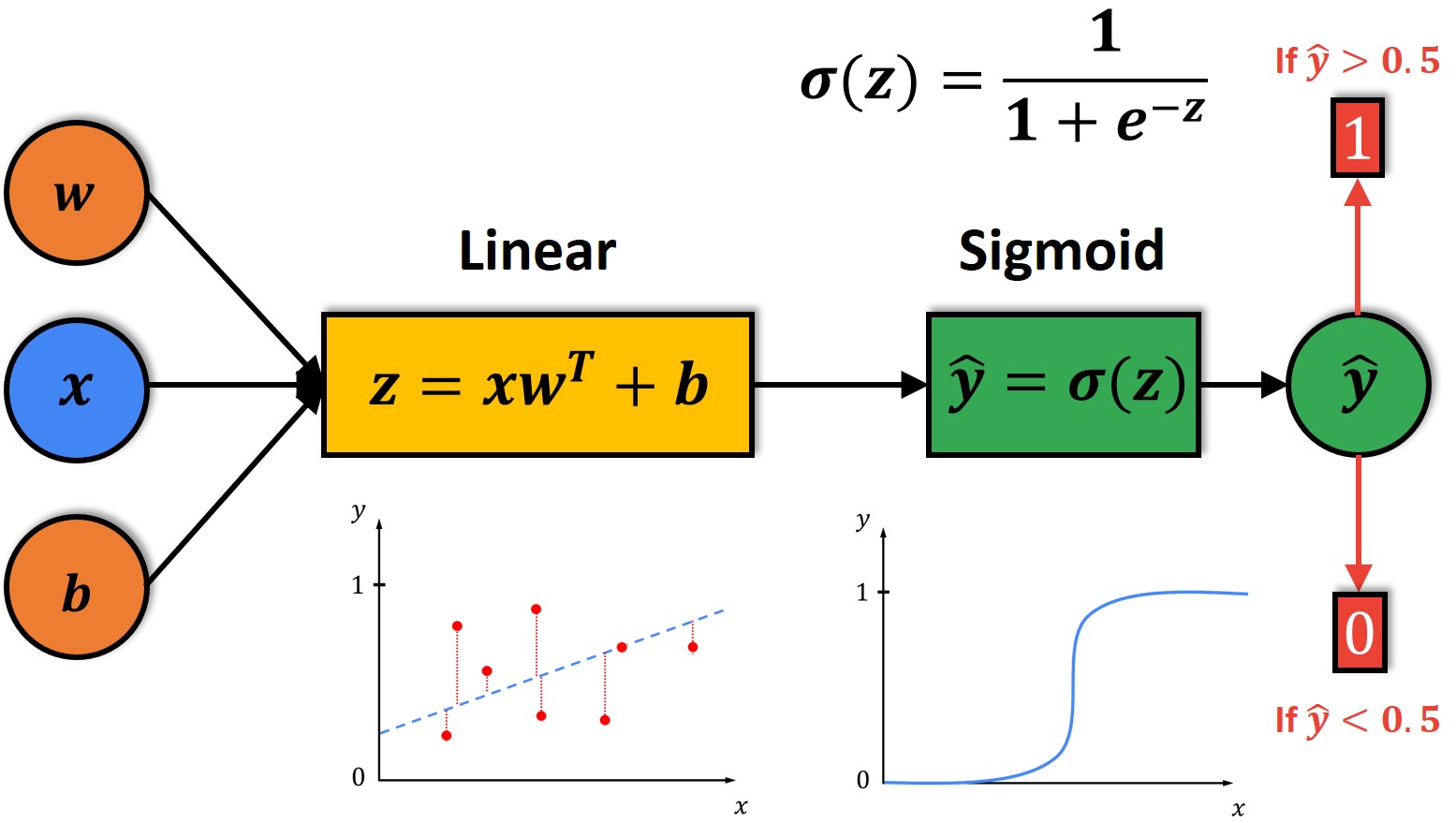
In logistic regression, the goal is to estimate the probability that an instance belongs to a particular class. The logistic sigmoid function, with its range limited between 0 and 1, is highly suitable for this task. The logistic sigmoid takes the form of f(x) = 1 / (1 + e^(-x)), where x represents the linear combination of the input features and corresponding model coefficients.
The logistic function converts the linear combination of input features into a probability estimate between 0 and 1. It maps the input values to a range that represents the likelihood of the instance belonging to the positive class. For example, a probability of 0.8 implies an 80% chance of belonging to the positive class.
To train the logistic regression model, an optimization algorithm is employed to find the optimal coefficients that minimize the difference between the predicted probabilities and the actual class labels in the training data. This optimization is typically achieved by maximizing the likelihood or minimizing the difference between the predicted probabilities and the true labels using methods such as maximum likelihood estimation or gradient descent.
Once the model is trained, it can be used to predict the probability of an instance belonging to the positive class. By applying a threshold (commonly 0.5) to the predicted probabilities, we can classify the instance as either positive or negative.
The sigmoid function in logistic regression has several advantages. Its ability to map input values to a probability range makes it interpretable. It enables the estimation of the likelihood of an instance belonging to a particular class, allowing for informed decision-making. Additionally, the differentiable and smooth nature of the sigmoid function facilitates efficient optimization during the training process.
Overall, logistic regression and the sigmoid function work hand-in-hand to provide a powerful algorithm for binary classification tasks. The sigmoid function plays a crucial role in transforming the linear combination of input features into meaningful probability estimates, enabling logistic regression models to make accurate predictions.
Sigmoid Function in Neural Networks
The sigmoid function plays a crucial role as an activation function in neural networks. These artificial neural networks are designed to simulate the functioning of the human brain and are composed of interconnected nodes, or neurons, that process and transmit information. The activation function, such as the sigmoid function, determines the output of each neuron, thereby influencing the network’s overall behavior. Here’s how the sigmoid function is used in neural networks:
In neural networks, the sigmoid function is applied to the weighted sum of inputs into a neuron. This sum, often referred to as the activation, is then transformed through the sigmoid activation function to produce the output of the neuron. The sigmoid function allows the neural network to introduce non-linearity, which enables the network to better generalize and learn complex patterns in the data.
The primary advantage of using a sigmoid activation function, such as the logistic sigmoid, is its smooth and continuous nature. This smoothness ensures that small changes in the input result in proportional changes in the output, facilitating stable and consistent learning. Moreover, the sigmoid function’s output is bounded between 0 and 1, which creates a clear distinction between the two possible states of a neuron: activated or not activated.
However, it is important to note that sigmoid activation functions also have limitations, especially when used in deeper neural networks. One of the main issues is the vanishing gradient problem, where the gradients computed during the backpropagation phase of training become increasingly small as they propagate backward through multiple layers. This can hinder the network’s ability to learn effectively and slow down the training process.
Despite the limitations, sigmoid activation functions are still employed in specific cases and architectures, especially when outputs need to be interpreted as probabilities or when dealing with simpler datasets. Alternative activation functions, such as the Rectified Linear Unit (ReLU), have gained popularity in recent years due to their ability to mitigate the vanishing gradient problem and enable faster training in deeper neural networks.
Overall, the sigmoid function serves as a crucial component in the activation of neurons within neural networks. It introduces non-linearity, allows for stable learning, and facilitates the representation of complex patterns in the data. While it has its limitations, the sigmoid function continues to be well-suited for various neural network architectures and applications.
Sigmoid Function in Activation Functions
The sigmoid function is widely used as an activation function in neural networks and other machine learning models. Activation functions determine the output of a neuron or a node in a neural network, influencing the network’s ability to learn and make predictions. The sigmoid function has several properties that make it a popular choice for activation functions:
One of the primary advantages of using the sigmoid function as an activation function is its ability to introduce non-linearity into the model. Non-linearity is crucial in capturing complex relationships and patterns in the data that cannot be represented by simple linear functions. By applying the sigmoid function to the weighted sum of inputs, the output of the neuron becomes non-linear, allowing the neural network to model more intricate relationships.
The sigmoid function also has a bounded output range between 0 and 1. This property is advantageous in certain scenarios, particularly in classification tasks where the output needs to be interpreted as a probability or a binary decision. The sigmoid function maps the input values to a probability-like range, making it suitable for estimating the likelihood of an event occurring or assigning binary class labels.
Furthermore, sigmoid functions are differentiable at all points, making them compatible with optimization algorithms that rely on computing gradients, such as backpropagation. The smooth and continuous nature of the sigmoid function allows for efficient gradient-based optimization during the training process, ensuring that small changes in the model’s parameters result in proportional changes in the output.
It is worth noting that sigmoid functions, particularly the logistic sigmoid, have limitations. One major drawback is the vanishing gradient problem, where the gradients become extremely small, leading to slower convergence and difficulty in training deep neural networks. This limitation has prompted the adoption of alternative activation functions, such as the Rectified Linear Unit (ReLU), which alleviate the vanishing gradient problem and offer faster training.
Despite the emergence of newer activation functions, sigmoid functions continue to be employed in various network architectures and machine learning models. Their non-linear behavior, bounded output range, and differentiability make them suitable for specific applications. Additionally, the interpretability of the sigmoid function’s output as probabilities or binary decisions remains valuable in certain contexts. A thorough understanding of activation functions, including sigmoid functions, is essential for choosing an appropriate function that aligns with the specific requirements of the model and the desired behavior of the neural network.
Limitations of Sigmoid Functions
While sigmoid functions offer numerous benefits, it is important to be aware of their limitations and potential drawbacks in certain scenarios. Here are several key limitations of sigmoid functions:
- Vanishing Gradient Problem: Sigmoid functions, particularly the logistic sigmoid, are prone to the vanishing gradient problem. As the values of the sigmoid function approach the extremities (close to 0 or 1), the gradient becomes significantly small. This can hinder the learning process, especially in deep neural networks, where gradients need to propagate through multiple layers. The vanishing gradient problem can lead to slow convergence and limited learning capacity.
- Output Saturation: Sigmoid functions tend to saturate as the input values move towards the extremes. This means that for extremely large or small inputs, the output of the sigmoid function becomes close to 1 or 0, respectively. In these saturated regions, the gradients become very small, resulting in slow or stagnant learning. This saturation phenomenon can limit the expressive power of the model, particularly when handling data with extreme values.
- Lack of Zero-Centered Output: Sigmoid functions, such as the logistic sigmoid, are not centered around zero. This can cause biases in certain scenarios, as neurons in subsequent layers of the neural network may receive inputs that are predominantly positive or negative. Biased inputs can affect the learning process and make it challenging to find optimal weight updates during training.
- Non-Sparsity of Activation: Sigmoid functions do not encourage sparsity in neural network activations. This means that multiple neurons can be activated simultaneously, leading to a high-dimensional representation of the input. In situations where sparse activations are desired, other activation functions like the Rectified Linear Unit (ReLU) may be more suitable.
- Computational and Memory Intensity: The computation of the sigmoid function involves exponentiation, which can be computationally expensive and memory-intensive. The additional computational overhead may impact the efficiency of training and inference, particularly in large-scale neural networks or resource-constrained environments.
Given these limitations, it is important to consider alternative activation functions when appropriate. Activation functions such as the ReLU or its variants address some of the challenges posed by sigmoid functions. The choice of activation function depends on the specific characteristics of the problem at hand and the properties desired in the model’s behavior. Understanding the limitations of sigmoid functions enables machine learning practitioners to make informed decisions and select the most suitable activation function for their particular use case.
Alternatives to Sigmoid Functions
While sigmoid functions have been widely used in the past, alternative activation functions have emerged that address some of the limitations associated with sigmoid functions. These alternatives offer improved performance, faster convergence, and enhanced expressiveness in neural networks. Let’s explore a few popular alternatives to sigmoid functions:
- Rectified Linear Unit (ReLU): The Rectified Linear Unit, commonly known as ReLU, is one of the most popular activation functions in deep learning. ReLU gives an output of zero for negative input values and passes the positive input values directly, often resulting in faster convergence during training. ReLU is computationally efficient, avoids the vanishing gradient problem, and encourages sparse activation by suppressing neurons that are not activated, leading to more efficient and expressive models.
- Leaky ReLU: Leaky ReLU is a variant of ReLU that addresses the issue of dead neurons where the gradient becomes zero for negative input values. Leaky ReLU introduces a small slope for negative inputs, ensuring that the gradient can flow even for negative values. This helps prevent dead neurons and can further improve the performance of the network.
- Parametric ReLU (PReLU): PReLU is an extension of Leaky ReLU that allows the slope of the activation to be learned during training. Instead of using a fixed slope, PReLU introduces a parameter that is updated through backpropagation. This adaptability enables the network to learn the optimal slope for different input ranges, yielding better performance and increased flexibility.
- Exponential Linear Unit (ELU): ELU is another alternative to sigmoid functions that is designed to capture both negative and positive values smoothly. ELU resembles the ReLU function for positive inputs but introduces a slightly negative, differentiable output for negative inputs. ELU helps mitigate the vanishing gradient problem and provides a balanced activation function capable of handling both positive and negative inputs effectively.
- Maxout Activation: Maxout is a more general activation function that does not rely on a specific mathematical formula. It partitions the input into groups and takes the maximum value within each group as the output. The Maxout activation function enables the network to learn complex decision boundaries and can be advantageous in certain scenarios.
These are just a few examples of the alternatives to sigmoid functions. Each activation function has its advantages and is suited for distinct use cases. Choosing the right activation function depends on the specific problem, dataset characteristics, and desired properties of the model. Neural network practitioners often experiment with a variety of activation functions to find the best match for their particular scenario, balancing performance, computational efficiency, and the ability to capture non-linear relationships in the data.