
History of Perceptrons
Perceptrons are fundamental units in the field of artificial neural networks, which are models inspired by the structure and functioning of the human brain. Developed in the late 1950s and early 1960s by Frank Rosenblatt, perceptrons marked significant progress in the field of machine learning.
Rosenblatt’s work was greatly influenced by the artificial neuron concept proposed by Warren McCulloch and Walter Pitts in the 1940s. The perceptron was designed as a simplified model of how a biological neuron functions. It aimed to replicate the process of data processing and decision-making in the human brain.
The initial perceptron model consisted of a single layer of input units connected to a single output unit. Each input unit was associated with a weight that represented the strength of its influence on the final output. The perceptron’s objective was to learn the optimal combination of weights that would yield accurate predictions.
Rosenblatt’s perceptron was groundbreaking at the time because it introduced the concept of learning from examples. By adjusting the weights based on the correctness of its predictions, the perceptron could gradually improve its performance over time.
However, perceptrons faced criticism in the late 1960s due to their inability to solve certain complex problems. Researchers discovered that perceptrons could only learn linearly separable patterns, limiting their applicability to more intricate tasks. This led to a period known as the “AI winter,” where research and interest in artificial intelligence receded.
Fortunately, the limitations of perceptrons were overcome with the development of more advanced neural network models, such as multi-layer perceptrons (MLPs) and backpropagation algorithms in the 1980s. These advancements allowed neural networks to learn non-linear patterns and paved the way for the resurgence of artificial intelligence.
Today, perceptrons continue to play a crucial role in machine learning and artificial intelligence. They serve as building blocks for more sophisticated neural network architectures, such as convolutional neural networks (CNNs) and recurrent neural networks (RNNs).
Definition and Function of Perceptrons
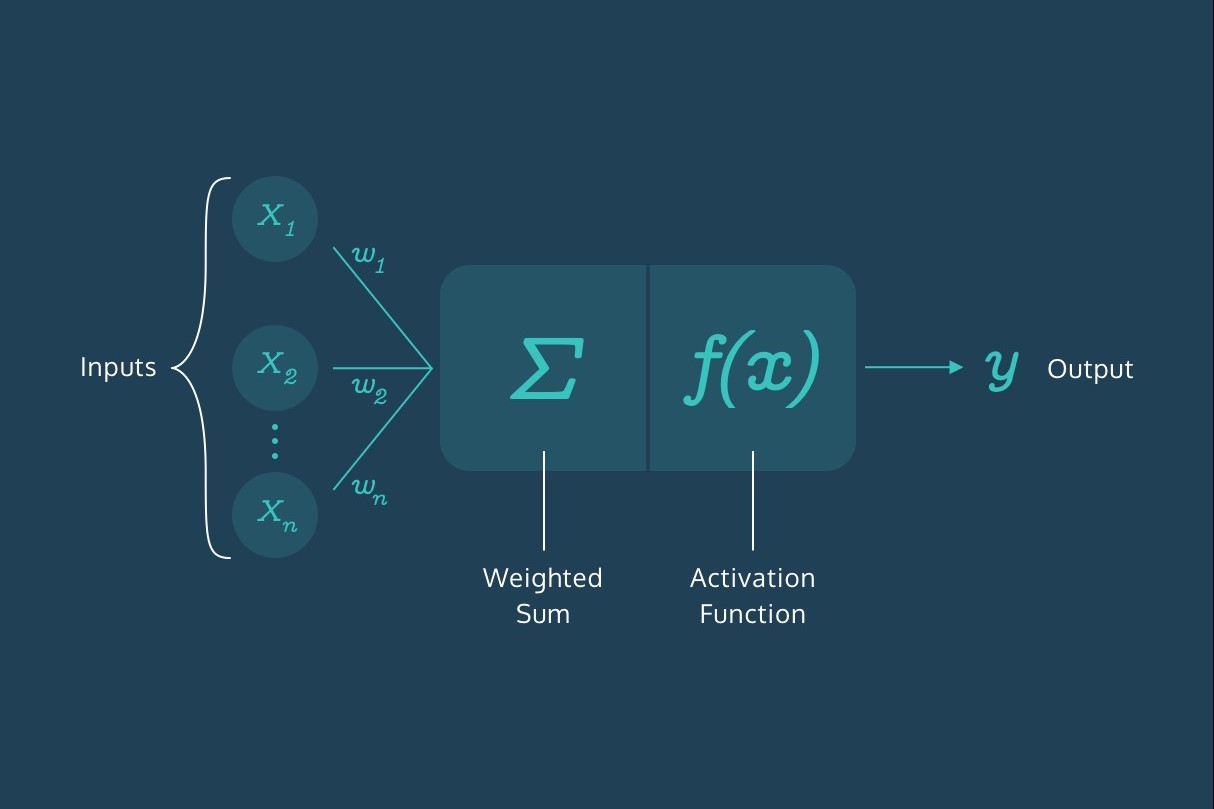
Perceptrons are basic units of computation in machine learning that model the functioning of a biological neuron. They are binary classifiers that take multiple input signals and produce a single output signal. A perceptron’s primary function is to make decisions based on the weighted sum of its inputs, combined with an activation function.
The inputs to a perceptron can be any real-valued numbers, each associated with a weight that determines its significance in the decision-making process. These weights signify the strength of the connection between the inputs and the perceptron’s output. Additionally, a perceptron may have a bias term that allows for flexibility in decision-making.
The activation function of a perceptron is the final piece that determines its output. It takes the weighted sum of the inputs and applies a threshold or activation rule to produce the final output. Depending on the activation function used, a perceptron can exhibit different behaviors, such as a step function for binary decisions or a sigmoid function for probabilistic outputs.
Perceptrons work by comparing the weighted sum of inputs to a threshold value. If the sum exceeds the threshold, the perceptron fires or activates, resulting in a positive output. Otherwise, if the sum is below the threshold, the perceptron remains dormant, resulting in a negative output.
To learn from data and improve performance, perceptrons employ a training algorithm known as the perceptron learning rule. This rule adjusts the weights of the inputs based on the observed errors in the output. By iteratively updating the weights, perceptrons can efficiently classify inputs and adapt to new patterns.
It is important to note that a single perceptron can only classify linearly separable patterns, meaning it can distinguish inputs that lie on opposite sides of a hyperplane. However, this limitation can be overcome by combining multiple perceptrons, forming complex neural network architectures that can solve more intricate problems.
Structure and Components of Perceptrons
A perceptron consists of several key components that enable it to process input signals and produce an output. Understanding these components is essential to comprehend the inner workings of perceptrons.
The input layer is the initial component of a perceptron. It is responsible for receiving the input signals and transmitting them to the subsequent layers. Each input signal is associated with a weight, which represents the importance or influence of that specific input on the final output.
Weights play a crucial role in perceptrons, as they determine the significance of each input signal in the decision-making process. The values of the weights can be adjusted during the learning phase to optimize the perceptron’s performance.
The weighted sum aggregation function is applied to the inputs and their corresponding weights. This function calculates the sum of the products of each input signal and its associated weight. The result of this aggregation is referred to as the activation, also known as the net input.
The activation is then passed through an activation function, which determines the output of the perceptron. Common activation functions include step functions, sigmoid functions, and rectified linear unit (ReLU) functions. The choice of activation function depends on the specific problem being solved and the desired behavior of the perceptron.
The output layer is the final component of a perceptron that produces the output based on the activation. The output can be binary, i.e., a binary decision, or probabilistic, i.e., representing the probability of a certain class or outcome.
In addition to the input layer, hidden layers can be present in perceptron architectures. Hidden layers are intermediate layers between the input and output layers. They increase the complexity and representational power of the perceptron, enabling it to learn and process more intricate patterns.
Each perceptron in a hidden layer receives inputs from the previous layer and passes its output forward to the next layer. The connection between perceptrons in adjacent layers is determined by weights, just like in the input layer. These weights allow the perceptron to account for different levels of importance and influence among the inputs.
By combining multiple perceptrons and layers, complex neural networks can be constructed, capable of solving a wide range of problems by leveraging the power of parallel computing and non-linear transformations.
Perceptron Learning Rule
The perceptron learning rule is a fundamental algorithm that allows perceptrons to learn from training data and improve their performance over time. It adjusts the weights of the input signals based on the observed errors in the output.
The learning process starts with initializing the weights and biases of the perceptron to small random values. Then, for each training example, the perceptron computes the weighted sum of the inputs and applies the activation function to generate the predicted output.
If the predicted output matches the desired output, no adjustment to the weights is necessary, as the perceptron has made the correct decision. However, if there is a mismatch, the weights need to be updated to reduce the error.
The weights are updated using a simple rule called the delta rule or the Widrow-Hoff learning rule. The update is proportional to the difference between the predicted output and the desired output, multiplied by the input value. The updated weight is then added to the current weight, affecting future predictions.
The learning rate is a crucial parameter that influences the magnitude of weight updates. A higher learning rate leads to more significant weight adjustments, enabling the perceptron to learn faster but risking overshooting and instability. Conversely, a lower learning rate ensures more gradual learning but may require more training iterations to reach optimal performance.
The learning process continues iteratively, with the perceptron processing each training example and adjusting the weights accordingly. This process is repeated until the perceptron achieves acceptable accuracy on the training data or reaches a predefined stopping criterion.
It is worth noting that perceptrons using the basic learning rule can only learn linearly separable patterns. This limitation restricts their applicability to problems that have linear decision boundaries. However, by combining multiple perceptrons and incorporating hidden layers, more complex neural network architectures can be constructed that can learn and solve non-linearly separable problems.
While the perceptron learning rule laid the foundation for neural network training, more advanced optimization algorithms, such as gradient descent and backpropagation, have been developed to train complex neural networks with multiple layers. These algorithms overcome the limitations of basic perceptrons and enable the efficient learning of non-linear patterns.
Limitations of Perceptrons
Perceptrons, despite their significance in the field of machine learning, have certain limitations that restrict their applicability to certain types of problems. Understanding these limitations is crucial to effectively utilize perceptrons in practical applications.
One notable limitation of perceptrons is their inability to solve problems that are not linearly separable. If the input data points cannot be separated by a straight line or hyperplane, perceptrons fail to learn and classify them accurately. This limitation became apparent in the famous XOR problem, where a single perceptron fails to correctly classify inputs that are not linearly separable.
Perceptrons also struggle with handling continuous or real-valued inputs directly. Since perceptrons make deterministic binary decisions, they require discrete inputs. Converting continuous inputs into discrete form can lead to information loss and affect the performance of perceptrons.
Another limitation is related to the architecture of perceptrons. Single-layer perceptrons have limited representational power due to their linear decision boundaries. They cannot capture complex, non-linear relationships between inputs and outputs. However, this limitation can be overcome by using multi-layer perceptrons (MLPs) with hidden layers, allowing for the creation of more flexible and expressive architectures.
Furthermore, perceptrons are sensitive to the initial weights and can get stuck in suboptimal solutions or local minima. Depending on the initial configuration, they may fail to converge to the global optimal solution or take a considerable amount of time to do so.
Finally, perceptrons require labeled training data to learn and make accurate predictions. They are not inherently capable of unsupervised learning or discovering patterns in the absence of explicit labels or guidance. This limitation makes perceptrons less suitable for tasks like clustering or anomaly detection.
Despite these limitations, it is essential to note that perceptrons served as a foundation for the development of more advanced neural network architectures, such as convolutional neural networks (CNNs) and recurrent neural networks (RNNs). These architectures address many of the limitations of basic perceptrons and have revolutionized fields like computer vision, natural language processing, and speech recognition.
Perceptrons versus Artificial Neural Networks
Perceptrons and artificial neural networks (ANNs) are closely related but differ in terms of their structure, capabilities, and applications. Understanding the distinctions between these two concepts is crucial in the field of machine learning and neural networks.
Perceptrons are the building blocks of artificial neural networks. They are the simplest form of neural networks with a single layer of input units connected to a single output unit. Perceptrons make binary decisions based on weighted sums of inputs and an activation function.
In contrast, artificial neural networks consist of multiple interconnected layers of perceptrons or more advanced neuron units. These networks are capable of more complex computations and can learn non-linear patterns. Artificial neural networks employ various architectures, such as multi-layer perceptrons (MLPs), convolutional neural networks (CNNs), and recurrent neural networks (RNNs), depending on the requirements of the problem.
Perceptrons are limited to solving linearly separable problems, while artificial neural networks can handle non-linearly separable problems by combining multiple perceptrons and introducing hidden layers. The inclusion of hidden layers enables artificial neural networks to learn and model complex relationships between inputs and outputs.
Artificial neural networks employ more advanced learning algorithms, such as backpropagation, to train and optimize their weights and biases. Backpropagation, unlike the perceptron learning rule, calculates error gradients throughout the network, allowing for more efficient and accurate weight updates.
Another distinction lies in the types of inputs. Perceptrons generally handle discrete or binary inputs, as they produce binary outputs. On the other hand, artificial neural networks can handle both discrete and continuous inputs, providing more flexibility and versatility in applications.
Artificial neural networks have gained significant popularity and success in various domains, such as computer vision, natural language processing, speech recognition, and deep learning. Perceptrons, although limited in their direct applications, laid the foundation for the development and advancement of artificial neural networks.
Applications of Perceptrons
Perceptrons have found a range of applications in various fields due to their ability to perform binary classification tasks. While their simplicity and limitations restrict their direct use in complex problems, they have proven to be valuable in certain domains.
One of the primary applications of perceptrons is in pattern recognition tasks. They can be trained to recognize and classify simple patterns based on their input features. This makes them useful in tasks such as handwriting recognition, optical character recognition (OCR), and face detection.
Another area where perceptrons have been employed is in the medical field. They have been utilized to diagnose diseases based on input parameters, such as symptoms or medical test results. Perceptrons can assist in early detection of conditions like diabetes, cancer, and heart disease.
In the field of finance and economics, perceptrons have been used for credit scoring models to assess the creditworthiness of individuals or businesses. They analyze multiple variables, such as income, credit history, and loan amount, to determine the likelihood of default or credit risk.
Perceptrons have also found application in the realm of signal and image processing. They can be trained to identify specific signals, such as in speech recognition for detecting phonemes or in audio and video compression for data encoding and decoding.
Classification tasks in the field of natural language processing (NLP) have benefitted from the use of perceptrons. They can be trained to recognize sentiment in texts, detect spam emails, or identify the topic of a given document.
Perceptrons have been utilized in robotics and control systems as well. They can play a role in robotic navigation, where they are trained to make decisions based on sensor inputs and maneuver robots through complex environments.
Although perceptrons themselves may not be the sole solution for more complex problems, they have served as the stepping stone for the development of more sophisticated artificial neural network architectures. These advanced networks, built upon the principles of perceptrons, have proven to be powerful in solving complex tasks like image recognition, natural language understanding, and deep learning applications.
Examples and Demonstrations of Perceptrons
To understand the practical application of perceptrons, let’s explore some examples and demonstrations of how perceptrons can be used in various domains.
1. Logical Gates: Perceptrons can be used to simulate logical gates, such as AND, OR, and NOT gates. By appropriately training the perceptron’s weights and biases, it can accurately mimic the behavior of these basic logical operations.
2. Spam Email Filtering: Perceptrons have been employed in the development of spam email filters. By analyzing the content and attributes of incoming emails, perceptrons can classify them as either spam or legitimate messages, thereby reducing the clutter in users’ inboxes.
3. Cancer Diagnosis: In the medical field, perceptrons have been utilized to assist in cancer diagnosis. By considering various patient parameters, such as age, test results, and medical history, perceptrons can predict the likelihood of an individual having cancer, facilitating early detection and treatment.
4. Handwritten Digit Recognition: Perceptrons have been applied in optical character recognition (OCR) systems for handwriting digit recognition. By training the perceptron on a dataset of handwritten digits, it can accurately classify and recognize the digits from input images or scanned documents.
5. Stock Market Prediction: In finance, perceptrons have been used to predict stock prices based on various inputs, such as historical price trends, trading volumes, and market indicators. By training the perceptron on past market data, it can provide insights into potential stock movements.
6. Voice Command Recognition: Perceptrons have found applications in voice command recognition systems, such as virtual assistants. By training perceptrons on a dataset of voice recordings, they can accurately recognize and respond to spoken commands, enabling hands-free interactions.
7. Customer Churn Prediction: In the field of customer analytics, perceptrons can be used to predict customer churn, i.e., the likelihood of a customer discontinuing a service or product. By analyzing various customer attributes and behaviors, perceptrons can help businesses identify customers at risk of churning and take proactive measures to retain them.
These examples demonstrate the versatility of perceptrons and their ability to tackle a wide range of problems. While perceptrons may handle relatively simple tasks, they serve as the foundation for more complex neural network architectures, allowing for the development of advanced machine learning models and intelligent systems.