
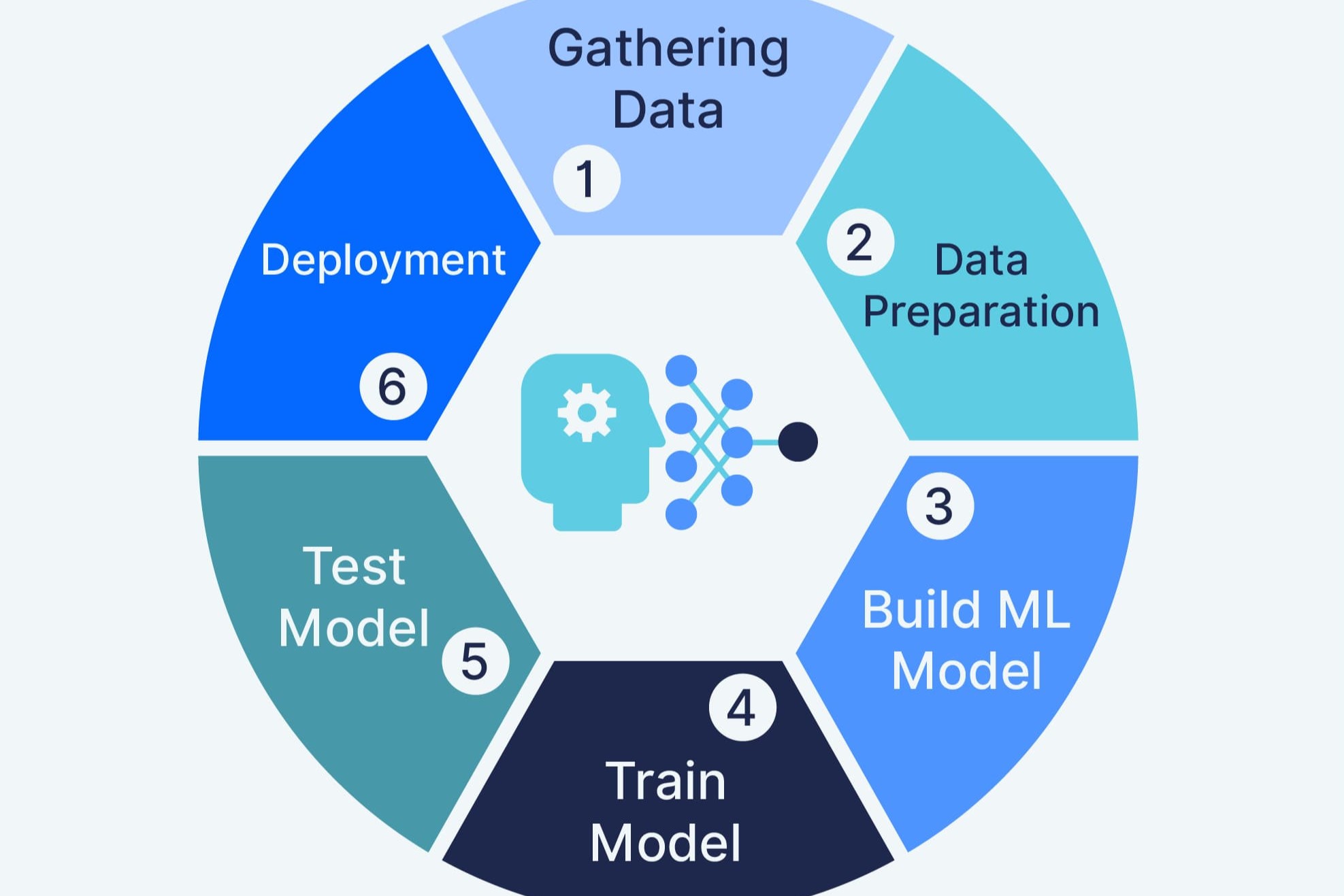
Step 1: Problem Identification
At the beginning of the machine learning cycle, it is crucial to clearly identify and define the problem you are trying to solve. This step is vital because it lays the foundation for the entire process and determines the direction you will take. Understanding the problem enables you to formulate the right questions and objectives.
During problem identification, take the time to analyze and gather information about the problem domain. This involves consulting domain experts, reviewing available literature, and studying existing solutions. By gaining deep insights into the problem, you can identify the specific areas that can benefit from machine learning.
Once you have a clear understanding of the problem, it’s important to define clear and measurable goals. This helps in evaluating the success of your machine learning solution and keeps your project on track. Your goals should be realistic and aligned with the problem at hand.
In this step, it is also crucial to identify the relevant stakeholders and understand their requirements. Different stakeholders may have different perspectives and expectations, so ensuring alignment and collaboration is essential. By involving all the stakeholders from the start, you can gather valuable insights and ensure that your machine learning solution addresses their needs.
During problem identification, it is also a good practice to consider the limitations and constraints of the problem. This includes factors such as available resources, data quality, and time constraints. By understanding these limitations, you can plan accordingly and make informed decisions throughout the machine learning cycle.
Remember, problem identification is the initial stage of the machine learning cycle, and investing sufficient time and effort into this step is crucial for the success of your project. By thoroughly understanding the problem, setting clear goals, and involving stakeholders, you lay a strong foundation for the subsequent steps of data collection, preprocessing, model selection, model training, and model evaluation.
Step 2: Data Collection
Data collection is a fundamental step in the machine learning cycle. It involves gathering relevant data that will be used to train and test your machine learning models. High-quality, comprehensive, and representative data is essential for the success of your machine learning project.
When collecting data, it is important to define the specific variables and features you need to capture. The data gathered should be directly related to the problem you are trying to solve. This may require a combination of structured data (formatted, organized data) and unstructured data (such as text, images, or audio).
There are various sources for collecting data, depending on the problem domain. These sources may include databases, APIs, web scraping, sensor devices, or even user-generated content. It is crucial to ensure that the data you collect is legal, ethical, and respects the privacy and security of individuals.
Another important consideration during data collection is the size and diversity of the dataset. A larger dataset is generally preferred as it helps in training robust and accurate models. Additionally, diversity in the data helps to capture a wide range of patterns and variations present in the real world.
During the data collection phase, it is essential to pay attention to data quality. This includes checking for completeness, accuracy, and consistency of the data. Outliers, missing values, or noisy data can adversely affect the performance of your machine learning models. Therefore, data cleaning and preprocessing techniques should be applied to ensure the data is of high quality.
Furthermore, it is important to consider the appropriate data storage and organization methods. Properly organizing and labeling the data simplifies its accessibility and reduces the time spent searching for specific samples or features. This can be achieved by using a structured database or file system architecture.
Remember, data collection sets the stage for the subsequent steps of data preprocessing, model selection, training, and evaluation. Collecting the right data with good quality and diversity is crucial for building accurate and effective machine learning models.
Step 3: Data Preprocessing
Data preprocessing is a crucial step in the machine learning cycle that involves preparing the collected data for analysis and model training. Raw data often contains noise, inconsistencies, and missing values, which can negatively impact the performance of machine learning algorithms. Data preprocessing aims to clean, transform, and preprocess the data to make it suitable for further analysis and modeling.
One common preprocessing technique is data cleaning, which involves handling missing values, outliers, and noisy data. Missing values can be filled through techniques like imputation or ignored depending on the impact they may have on the analysis. Outliers can be detected and treated using statistical methods, such as removing them or replacing them with more appropriate values. Noise can be reduced using smoothing or denoising techniques, depending on the nature of the data.
Another important aspect of data preprocessing is data normalization or scaling. Different features in the dataset may have different scales or units, which can affect the performance of machine learning models. Normalization techniques, such as Min-Max scaling or Standard scaling, are applied to bring the features to a similar scale, ensuring fair comparisons and preventing dominance of certain features over others.
Feature selection or dimensionality reduction is also a key step in data preprocessing. High-dimensional data may contain redundant or irrelevant features, which can lead to overfitting or decreased model performance. Techniques like Principal Component Analysis (PCA) or feature selection algorithms help in identifying the most relevant features that contribute the most to the target variable, reducing the dimensionality of the dataset.
Data preprocessing also involves handling categorical variables. Categorical variables need to be encoded in a way that machine learning algorithms can process them. This can be achieved through techniques like one-hot encoding, label encoding, or ordinal encoding, depending on the nature of the categorical variable.
In addition, data preprocessing may involve dealing with imbalanced datasets, where the number of samples in different classes is unequal. Techniques like oversampling or undersampling can be applied to balance the class distribution and prevent bias towards the majority class.
Overall, data preprocessing plays a significant role in improving the quality and usability of the data for machine learning. By cleaning the data, normalizing features, reducing dimensionality, and handling categorical variables, data preprocessing ensures that the data is ready for the subsequent steps of model selection, training, and evaluation.
Step 4: Model Selection
Model selection is a critical step in the machine learning cycle where you choose the appropriate algorithm or model that best addresses your problem and dataset. The goal is to select a model that can effectively learn from the data and make accurate predictions or classifications.
There are several factors to consider when selecting a model. The nature of your problem, such as regression, classification, or clustering, will determine the type of algorithm to use. Additionally, the size of your dataset, the number of features, and the availability of computational resources may also influence your model selection.
It’s essential to assess various models and compare their performance using evaluation metrics. This can be done through techniques like cross-validation, where the dataset is split into multiple train-test sets to estimate the model’s performance. By evaluating models using metrics like accuracy, precision, recall, or mean squared error, you can identify the best-performing model for your specific problem.
Consider the assumptions and limitations of each model and ensure they align with the characteristics of your dataset. Some algorithms may make assumptions about the linearity of the data, while others may be more suitable for handling non-linear relationships. Understanding these assumptions will help you choose the model that best fits your data.
It’s also worth exploring ensemble methods that combine multiple models to improve performance. Ensemble techniques, such as bagging, boosting, or stacking, can be used to create a strong predictive model by combining the predictions of multiple models.
Furthermore, consider the interpretability and complexity of the model. Depending on the domain or application, you may prefer a model that is easier to interpret and explain, even if it sacrifices a slight amount of performance. On the other hand, complex models may provide higher accuracy but can be harder to interpret.
Keep in mind that model selection is an iterative process. It is common to try different models, tune hyperparameters, and evaluate their performance until you find the best model for your specific problem.
By carefully selecting the appropriate model for your problem, you can optimize the performance of your machine learning system and ensure accurate predictions or classifications on new, unseen data.
Step 5: Model Training
Once you have selected the appropriate model, the next step in the machine learning cycle is model training. This involves feeding the selected algorithm with the preprocessed data to learn the underlying patterns and relationships.
During the training phase, the model adjusts its internal parameters or weights to minimize the difference between its predicted outputs and the actual target values in the training data. This process is often referred to as optimization or parameter estimation.
The training process typically involves splitting the preprocessed data into two subsets: the training set and the validation set. The training set is used to update the model’s weights, while the validation set helps in monitoring the performance of the model during the training process and detecting overfitting.
Overfitting occurs when the model performs well on the training data but fails to generalize well to new, unseen data. To prevent overfitting, regularization techniques, such as L1 or L2 regularization, can be applied to penalize complex models and encourage simplicity.
Model training also involves tuning hyperparameters, which are predefined parameters that affect the model’s learning process. Examples of hyperparameters include learning rate, regularization strength, or the number of hidden units in a neural network. Hyperparameter tuning is typically performed using techniques like grid search, random search, or more sophisticated methods like Bayesian optimization.
Furthermore, for certain types of models like neural networks, training may involve multiple passes over the dataset, known as epochs. Each epoch consists of several iterations or batches, where the model updates its weights based on a subset of the training data.
It is important to monitor the training process to ensure the model is converging and improving its performance. This can be done by tracking performance metrics on both the training set and the validation set. If the model’s performance plateaus or deteriorates, adjustments to the model architecture, hyperparameters, or the dataset may be necessary.
Once the model has been trained and optimized on the training data, it is ready for the next step: evaluation using unseen test data. Model training lays the foundation for producing accurate predictions or classifications based on new, unseen data.
Step 6: Model Evaluation
The final step in the machine learning cycle is model evaluation, where the performance of the trained model is assessed using unseen test data. Model evaluation is crucial to understand how well the model generalizes and performs on real-world, unseen examples.
During evaluation, the model’s predictions are compared to the true values in the test dataset. Various evaluation metrics are used depending on the problem type. For classification problems, metrics such as accuracy, precision, recall, and F1-score can be used. For regression problems, metrics like mean squared error (MSE), mean absolute error (MAE), or R-squared are commonly used.
It is important to note that model evaluation should be performed on data that the model has not seen during training or hyperparameter tuning. This ensures an unbiased evaluation of the model’s performance and its ability to generalize to new, unseen data.
In addition to overall metrics, it is valuable to analyze the model’s performance across different classes or segments, especially in cases where the dataset is imbalanced or classes have varying importance. This allows for a more detailed understanding of the model’s strengths and weaknesses.
Model evaluation also involves examining the model’s behavior through visualizations or interpretable techniques. This can help identify any biases or areas where the model may be making incorrect predictions. Techniques like confusion matrices, precision-recall curves, or ROC curves can provide deeper insights into the model’s performance.
If the model’s performance is not satisfactory, further iterations of model training, feature engineering, or hyperparameter tuning may be required. It is important to consider the practical implications and trade-offs of improving the model’s performance, such as computation time, interpretability, or business requirements.
Lastly, it’s crucial to document and communicate the results of the model evaluation, along with any insights or limitations. This ensures transparency, reproducibility, and facilitates informed decision-making for future enhancements or deployment of the model.
By conducting rigorous model evaluation, you can assess the effectiveness and reliability of your machine learning model, ensuring its suitability for real-world applications.
