
What is Database Normalization?
Database normalization is the process of organizing and structuring a database to eliminate redundancy and anomalies. It involves breaking down a database into smaller, more manageable tables while ensuring data integrity and reducing data redundancy. The goal of database normalization is to reduce data duplication and improve the overall efficiency and performance of the database.
When designing a database, it is common for data to become duplicated across multiple tables. This duplication can lead to inconsistencies, update anomalies, and wasted storage space. Database normalization solves these issues by organizing data into separate logical tables and applying specific rules to ensure data consistency and minimize redundancy.
The normalization process follows a set of normal forms, each with its own guidelines and rules. The higher the normal form, the more normalized the database is. The most commonly used normal forms are First Normal Form (1NF), Second Normal Form (2NF), and Third Normal Form (3NF).
In First Normal Form (1NF), the database is designed so that each table has a primary key and there are no repeating groups of data. This eliminates data redundancy and ensures atomicity.
In Second Normal Form (2NF), the database is in 1NF, and all non-key attributes are functionally dependent on the entire primary key. This eliminates partial dependencies and further reduces redundancy.
In Third Normal Form (3NF), the database is in 2NF, and all non-key attributes are functionally dependent on the primary key. This ensures that there are no transitive dependencies and further improves data integrity.
By implementing these normal forms, the database is optimized for storage efficiency, improves data integrity, and minimizes update anomalies. It also allows for better scalability and maintainability of the database system.
Database normalization is a fundamental concept in database design and plays a significant role in ensuring data consistency and integrity. It helps to eliminate data redundancy, update anomalies, and improve overall database performance. The process of normalization follows specific guidelines and rules, ensuring that data is organized efficiently and accurately within the database structure.
Benefits of Database Normalization
Database normalization offers several benefits that improve the efficiency, integrity, and maintainability of the database system. Let’s explore some of the key advantages:
- Elimination of Data Redundancy: By breaking down a database into smaller, more focused tables, normalization helps eliminate data duplication. This reduces storage space requirements and ensures that updates to the database only need to be made in one place, improving data consistency.
- Improved Data Integrity: Normalization ensures that each piece of data is stored in only one place, reducing the risk of inconsistencies and inaccuracies. This helps maintain data integrity and makes it easier to enforce data validation rules and constraints.
- Efficient Storage Utilization: As redundancy is minimized, the amount of storage space required is reduced. This leads to more efficient utilization of the database storage and can result in cost savings, especially for large databases.
- Enhanced Data Consistency: With normalization, updates to the database are streamlined, and inconsistencies are minimized. This ensures that changes to data are propagated correctly and consistently throughout the system.
- Improved Query Performance: Normalized databases are typically designed with smaller tables that are focused on specific data relationships. This allows for more efficient querying and indexing, leading to faster retrieval of relevant information.
- Easier Database Maintenance: A well-normalized database is easier to maintain and modify. The logical separation of data into smaller tables reduces the complexity of making changes to the database structure and minimizes the impact of those changes on the overall system.
Overall, database normalization helps optimize data storage, improve data integrity, enhance query performance, and simplify database maintenance. By adhering to the principles of normalization, organizations can create robust and efficient databases that serve as a solid foundation for their data management needs.
Types of Database Normalization
Database normalization follows a set of rules and guidelines known as normal forms. Each normal form builds upon the previous one to eliminate data redundancy and ensure data integrity. Let’s discuss the common types of database normalization:
- First Normal Form (1NF): In 1NF, data is organized into tables with each column containing atomic values. There should be no repeating groups of data, and each row should have a unique identifier or primary key. This eliminates data redundancy and ensures data integrity at the most basic level.
- Second Normal Form (2NF): 2NF builds upon 1NF by ensuring that all non-key attributes are functionally dependent on the entire primary key. In other words, there should be no partial dependencies. This is achieved by splitting the table into separate tables when necessary and establishing relationships between them. 2NF further reduces redundancy and enhances data integrity.
- Third Normal Form (3NF): 3NF builds upon 2NF by eliminating transitive dependencies in the data. Transitive dependencies occur when a non-key attribute depends on another non-key attribute instead of directly depending on the primary key. By removing these dependencies and creating separate tables for related data, 3NF ensures that the database is well-structured and maintains data integrity.
- Fourth Normal Form (4NF): 4NF addresses multi-valued dependencies in the data. It eliminates situations where a single attribute depends on multiple independent multi-valued attributes. By decomposing the table and creating separate tables for each multi-valued attribute, 4NF further reduces redundancy and enhances data integrity and storage efficiency.
- Fifth Normal Form (5NF): 5NF, also known as Project-Join Normal Form (PJNF), deals with join dependencies. Join dependencies occur when the data can be derived from the combination of two or more tables. By decomposing the table and creating separate tables for the dependent attributes, 5NF ensures that the database is properly normalized and avoids data redundancy.
- Additional Normal Forms: Boyce-Codd Normal Form (BCNF): BCNF is an alternative and more strict form of 3NF. It removes all non-trivial functional dependencies in a relationship and is specifically designed to address certain types of anomalies that can occur in 3NF databases.
By understanding and implementing these types of normalization, database designers can create well-structured databases that minimize redundancy, improve data integrity, and enhance overall database performance.
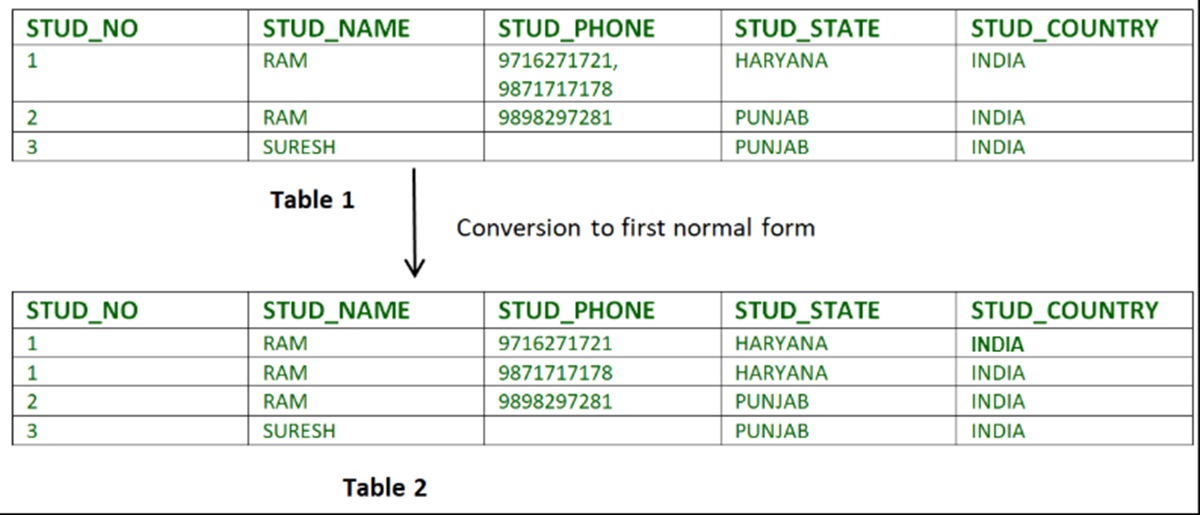
First Normal Form (1NF)
First Normal Form (1NF) is the initial step in the process of database normalization. It focuses on eliminating data redundancy and ensuring data integrity by organizing data into separate tables with unique identifiers. Let’s explore the key characteristics and requirements of 1NF:
- Atomic Values: In 1NF, each column in a table contains atomic values, meaning that it cannot be further divided. This ensures that data is stored in its most fundamental and indivisible form. For example, if we have a “Name” field, it should not contain multiple names in a single cell; instead, each name should be in its separate row.
- Unique Identifiers: Every table in 1NF must have a unique identifier or primary key. The primary key is a column or a combination of columns that uniquely identifies each row in the table. This uniqueness ensures that each row can be accessed and referenced accurately and efficiently.
- No Repeating Groups: 1NF requires that there should be no repeating groups of data within a table. Each column in a table should represent a single attribute, and data should not be duplicated or repeated across multiple columns or rows. If there are repeating groups of data, they should be split into separate tables.
- No Order Dependency: The order in which the data is stored should not have any significance. In 1NF, the values in a table should be unordered and independent of each other, focusing solely on the data itself rather than its arrangement.
- Data Integrity: 1NF emphasizes maintaining data integrity by ensuring that values are accurate, complete, and consistent. It prevents anomalies such as update, insertion, and deletion anomalies by organizing the data in a well-structured and normalized manner.
To achieve First Normal Form, it is essential to identify repeating groups and separate them into distinct tables with proper relationships. By adhering to the principles of 1NF, databases can eliminate redundancy, ensure data integrity, and provide a solid foundation for subsequent stages of normalization.
Second Normal Form (2NF)
Second Normal Form (2NF) is a form of database normalization that builds upon the First Normal Form (1NF) by eliminating partial dependencies. The purpose of 2NF is to further reduce data redundancy and ensure data integrity. Let’s delve into the key characteristics and requirements of 2NF:
- Primary Key: Similar to 1NF, each table in 2NF must have a unique identifier or primary key. The primary key uniquely identifies each row in the table.
- Functional Dependencies: In 2NF, all non-key attributes (columns) in a table must be functionally dependent on the entire primary key, not just a part of it. This means that every non-key attribute should be determined solely by the full set of primary key attributes.
- No Partial Dependencies: 2NF eliminates partial dependencies by ensuring that non-key attributes are not dependent on only a part of the primary key. Partial dependencies occur when a non-key attribute depends on only a subset of the primary key attributes, resulting in data redundancy and potential update anomalies.
- Proper Table Decomposition: To achieve 2NF, if there are partial dependencies present in a table, it is necessary to decompose the table into multiple tables. Each table should be focused on a specific subject and have its own distinct primary key.
By following the guidelines of 2NF, databases can avoid data redundancy and maintain better data integrity. The elimination of partial dependencies helps ensure that data updates are not dependent on specific subsets of the primary key, reducing the risk of inconsistencies and anomalies.
It’s important to note that achieving 2NF requires a thorough understanding of the data and its relationships in the database. Analyzing the functional dependencies and properly decomposing tables can help create a well-structured and normalized database, leading to improved performance and maintainability.
Third Normal Form (3NF)
Third Normal Form (3NF) is a key concept in database normalization that extends the principles of First Normal Form (1NF) and Second Normal Form (2NF). 3NF focuses on eliminating transitive dependencies and further reducing data redundancy. Let’s explore the key characteristics and requirements of 3NF:
- Primary Key and Functional Dependencies: As in 1NF and 2NF, each table in 3NF must have a unique identifier or primary key. Additionally, all non-key attributes (columns) in a table should be functionally dependent on the primary key. The primary key determines the values of the non-key attributes in a unique manner.
- No Transitive Dependencies: Transitive dependencies occur when a non-key attribute depends on another non-key attribute rather than directly depending on the primary key. In 3NF, transitive dependencies are eliminated by decomposing the table into multiple tables.
- Proper Table Decomposition: To achieve 3NF, if there are transitive dependencies present in a table, it is necessary to decompose the table into multiple tables. Each table should contain only those attributes that are functionally dependent on the primary key. This ensures that each table represents a single entity or concept.
- Data Integrity: 3NF promotes data integrity by reducing data redundancy and ensuring that each piece of data is stored in only one place. This minimizes the risk of inconsistent or conflicting information.
- Optimized Query Performance: By normalizing a database to 3NF, the data is organized efficiently, which can lead to improved query performance. Querying related data can be done through joins on the appropriate tables.
By adhering to the principles of 3NF, databases can eliminate data redundancy, reduce the chances of update anomalies, and improve overall data integrity. The appropriate decomposition of tables allows for better organization and a logical representation of the data.
It’s important to note that achieving 3NF requires a thorough understanding of the data and its relationships in the database. Properly identifying transitive dependencies and decomposing tables can help create a well-structured, normalized database that is easier to maintain and manage.
Fourth Normal Form (4NF)
Fourth Normal Form (4NF) is a level of database normalization that builds upon the principles of Third Normal Form (3NF). 4NF is designed to address multi-valued dependencies, further reducing data redundancy and improving data integrity. Let’s delve into the key characteristics and requirements of 4NF:
- Primary Key and Functional Dependencies: As with previous normal forms, each table in 4NF must have a unique identifier or primary key. Additionally, all non-key attributes (columns) should be functionally dependent on the primary key, ensuring that the primary key determines the values of the non-key attributes.
- No Multi-Valued Dependencies: Multi-valued dependencies occur when a non-key attribute depends on multiple independent multi-valued attributes. In 4NF, multi-valued dependencies are eliminated by decomposing the table into multiple tables, each containing a single-valued attribute.
- Proper Table Decomposition: To achieve 4NF, if there are multi-valued dependencies present in a table, it is necessary to decompose the table into multiple tables. Each table should contain only those attributes that are functionally dependent on the primary key and do not have multi-valued dependencies.
- Data Integrity: 4NF helps maintain data integrity by minimizing data redundancy and ensuring that each attribute is stored in only one place. This reduces the chances of inconsistent or conflicting information.
- Storage Efficiency: By eliminating multi-valued dependencies and properly decomposing tables, 4NF optimizes storage efficiency by avoiding duplications of data. This can lead to significant space savings, especially for large databases.
By applying the principles of 4NF, databases can achieve a higher level of normalization and minimize data redundancy. The decomposition of tables into smaller, more focused ones helps enhance data integrity, improve query performance, and optimize storage space.
It’s crucial to note that achieving 4NF requires a deep understanding of the data and its relationships in the database. Identifying multi-valued dependencies and decomposition of tables based on appropriate dependencies can result in a well-structured and normalized database, ensuring better efficiency and maintainability.
Fifth Normal Form (5NF)
Fifth Normal Form (5NF), also known as Project-Join Normal Form (PJNF), is the highest level of database normalization. 5NF builds upon the principles of the previous normal forms and focuses on eliminating join dependencies. It further reduces data redundancy and improves data integrity. Let’s explore the key characteristics and requirements of 5NF:
- Primary Key and Functional Dependencies: As with previous normal forms, each table in 5NF must have a unique identifier or primary key. All non-key attributes (columns) should be functionally dependent on the primary key, ensuring data integrity and proper dependency relationships.
- No Join Dependencies: Join dependencies occur when a relationship can be derived by joining two or more tables. In 5NF, join dependencies are eliminated by decomposing the table into multiple tables and establishing proper relationships through keys. Each table should contain only those attributes that are functionally dependent on the primary key, avoiding the need for unnecessary joins.
- Proper Table Decomposition: To achieve 5NF, if there are join dependencies present in a table, it is necessary to decompose the table into multiple tables with explicit relationships. Each table should contain attributes that are directly related to the primary key and do not rely on joins to obtain the values of other attributes.
- Data Integrity: 5NF helps maintain data integrity by reducing data redundancy and ensuring that each attribute is stored in only one place. It minimizes the risk of inconsistencies and conflicts arising from redundant data representations.
- Optimized Query Performance: By eliminating join dependencies and arranging the data into appropriate tables, 5NF enhances query performance. As the data is efficiently organized, complex join operations can be minimized, resulting in faster and more efficient querying of related data.
By applying the principles of 5NF, databases can achieve the highest level of normalization and minimize data redundancy. The careful decomposition of tables and establishment of explicit relationships help improve data integrity, optimize query performance, and ensure efficient storage utilization.
It’s important to note that achieving 5NF requires a deep understanding of the data and its relationships in the database. Identifying join dependencies and decomposing tables based on appropriate dependencies can result in a well-structured and normalized database, providing maximum efficiency and maintainability.
Additional Normal Forms: Boyce-Codd Normal Form (BCNF)
Boyce-Codd Normal Form (BCNF) is an additional level of database normalization that builds upon the principles of Third Normal Form (3NF). BCNF addresses certain types of anomalies that can still persist in a 3NF database. Let’s explore the key characteristics and requirements of BCNF:
- Primary Key and Functional Dependencies: As with other normal forms, each table in BCNF must have a unique identifier or primary key. All non-key attributes (columns) should be functionally dependent on the primary key.
- No Non-Trivial Functional Dependencies: BCNF addresses non-trivial functional dependencies, where a non-key attribute is functionally dependent on another non-key attribute. In BCNF, all non-trivial functional dependencies must involve the primary key exclusively.
- Proper Table Decomposition: To achieve BCNF, if there are non-trivial functional dependencies present in a table, it is necessary to decompose the table into multiple tables. Each table should only contain attributes that are functionally dependent on the primary key, satisfying the requirement of BCNF.
- Data Integrity: BCNF helps maintain data integrity by eliminating certain types of anomalies that can occur in 3NF databases. By reducing data redundancy and ensuring that each attribute is stored in only one place, BCNF minimizes the risk of inconsistencies and conflicts arising from redundant data representations.
- Reduced Update Anomalies: By decomposing tables based on proper functional dependencies, BCNF reduces update anomalies. An update anomaly occurs when a modification to one attribute unintentionally affects other attributes, leading to inconsistent or incorrect data.
BCNF provides an additional level of normalization that ensures even stricter data organization and integrity. By addressing non-trivial functional dependencies and reducing data redundancy to the maximum extent, BCNF helps create a highly normalized and efficient database structure.
It’s important to note that achieving BCNF requires careful analysis of the data and its dependencies. Identifying non-trivial functional dependencies and appropriately decomposing tables can result in a well-structured, normalized database that minimizes anomalies and ensures data integrity.
Denormalization
Denormalization is the process of intentionally introducing redundancy into a database design to improve performance and simplify complex queries. While normalization aims to eliminate redundancy and ensure data integrity, denormalization involves strategically reintroducing redundancy for specific reasons. Let’s explore the key aspects of denormalization:
- Performance Optimization: Denormalization is often employed to enhance the performance of a database. By duplicating data and eliminating the need for complex joins, denormalization can speed up query processing time. With denormalized tables, queries can be simplified, and the need for multiple table lookups and joins is reduced.
- Aggregation and Reporting: Denormalization is commonly used for data aggregation and reporting purposes. By precalculating and storing aggregated values, such as sums or averages, denormalized tables can significantly improve the efficiency of generating reports and performing analytical queries.
- Reduced Joins: In highly transactional systems or situations where response time is critical, denormalization can help minimize the number of joins required to retrieve data. By bringing together related data in a denormalized table, the need for complex joins across multiple tables can be eliminated, resulting in faster and more efficient queries.
- Balancing Normalization and Denormalization: When deciding to denormalize a database, a careful balance must be struck between the benefits of performance optimization and the potential drawbacks of introducing redundancy. It’s important to consider factors such as data consistency, update anomalies, and maintainability, as denormalization can make updates and modifications more complex.
- Cautious Use in Transactional Systems: While denormalization can be beneficial for reporting and analytical purposes, it is often less suitable for highly transactional systems. In these cases, maintaining a fully normalized database ensures better data integrity and easier management of updates.
Denormalization is a deliberate decision made during database design to improve performance by reintroducing redundancy. While it can bring efficiency gains in certain situations, careful consideration should be given to the trade-offs and potential pitfalls of introducing denormalized tables. Striking the right balance between normalization and denormalization is crucial for maintaining data integrity and achieving optimal performance.
How to Normalize a Database
Normalizing a database involves a systematic process of organizing data into tables and applying normalization rules. By following the steps outlined below, you can effectively normalize a database:
- Analyze the Data: Begin by thoroughly understanding the data and its relationships. Identify the entities, attributes, and their dependencies to determine the overall structure of the database.
- Apply First Normal Form (1NF): Ensure that each table conforms to 1NF. Split any columns with multiple values into separate columns or tables to eliminate data redundancy and achieve atomicity in the data.
- Implement Second Normal Form (2NF): Identify and address any partial dependencies in the tables. Decompose the tables by moving the attributes that do not depend on the entire primary key to separate tables, establishing relationships between them.
- Enforce Third Normal Form (3NF): Identify and eliminate any transitive dependencies in the tables. Decompose the tables further if necessary to remove any attributes that depend on other non-key attributes instead of directly relying on the primary key.
- Consider Additional Normal Forms: Evaluate whether the database can benefit from higher normal forms, such as Fourth Normal Form (4NF) or Fifth Normal Form (5NF). Apply further decomposition if there are multi-valued or join dependencies that need to be resolved.
- Establish Relationships: Define appropriate relationships between the tables using primary key-foreign key associations. Ensure referential integrity by establishing constraints and enforcing rules for updates and deletes.
- Review and Refine: Review the normalized database design to ensure that it meets the requirements and constraints of the system. Refine the structure and relationships as needed to optimize performance and maintainability.
It’s important to note that the process of normalization should be guided by the specific requirements and characteristics of the data being modeled. It may involve iteration and adjustments as the understanding of the data and its relationships deepens.
By following these steps and adhering to the principles of normalization, you can create a well-structured and efficient database design that minimizes redundancy, ensures data integrity, and facilitates effective data management.
Common Mistakes to Avoid in Database Normalization
While database normalization is an essential process for ensuring data integrity and efficiency, it’s important to be aware of common mistakes that can hinder the effectiveness and performance of the normalized database. By avoiding these pitfalls, you can optimize the normalization process. Let’s explore some of the common mistakes to avoid:
- Over-Normalization: Normalizing a database too aggressively can lead to unnecessary complexity. It’s important to find the right balance between normalization and performance. Not all data needs to be decomposed into separate tables; only attributes with functional dependencies should be separated.
- Ignoring Functional Dependencies: Neglecting to identify and understand the true functional dependencies within the database can result in inadequate normalization. It’s crucial to thoroughly analyze the data and determine the relationships and dependencies between attributes to ensure proper normalization.
- Missing or Incorrect Key Selection: The selection of primary keys is crucial in normalization. Choosing the wrong keys or failing to establish primary key-foreign key relationships can lead to data inconsistencies and inefficient queries. Careful consideration should be given to determining appropriate keys for each table.
- Failure to Establish Relationships: Relationships between tables are a fundamental aspect of database normalization. Neglecting to establish proper relationships through primary key-foreign key associations can result in data redundancy, update anomalies, and performance issues.
- Failure to Address Denormalization: While normalization is important for data integrity, there may be cases where denormalization is necessary for performance optimization. Failing to consider or appropriately apply denormalization techniques can result in complex and inefficient queries.
- Inadequate Indexing: Proper indexing is critical for efficient query processing. Neglecting to create appropriate indexes on key columns can lead to slow query performance and decreased database efficiency. Indexes should be carefully selected based on the anticipated query patterns.
- Insufficient Testing and Optimization: Failing to thoroughly test and optimize the normalized database design can lead to suboptimal performance. It’s important to test the database with representative data and query workloads and make iterative adjustments to achieve the desired performance outcomes.
By avoiding these common mistakes and following best practices throughout the normalization process, you can create a well-structured and efficient database design that improves data integrity, query performance, and overall system efficiency.