
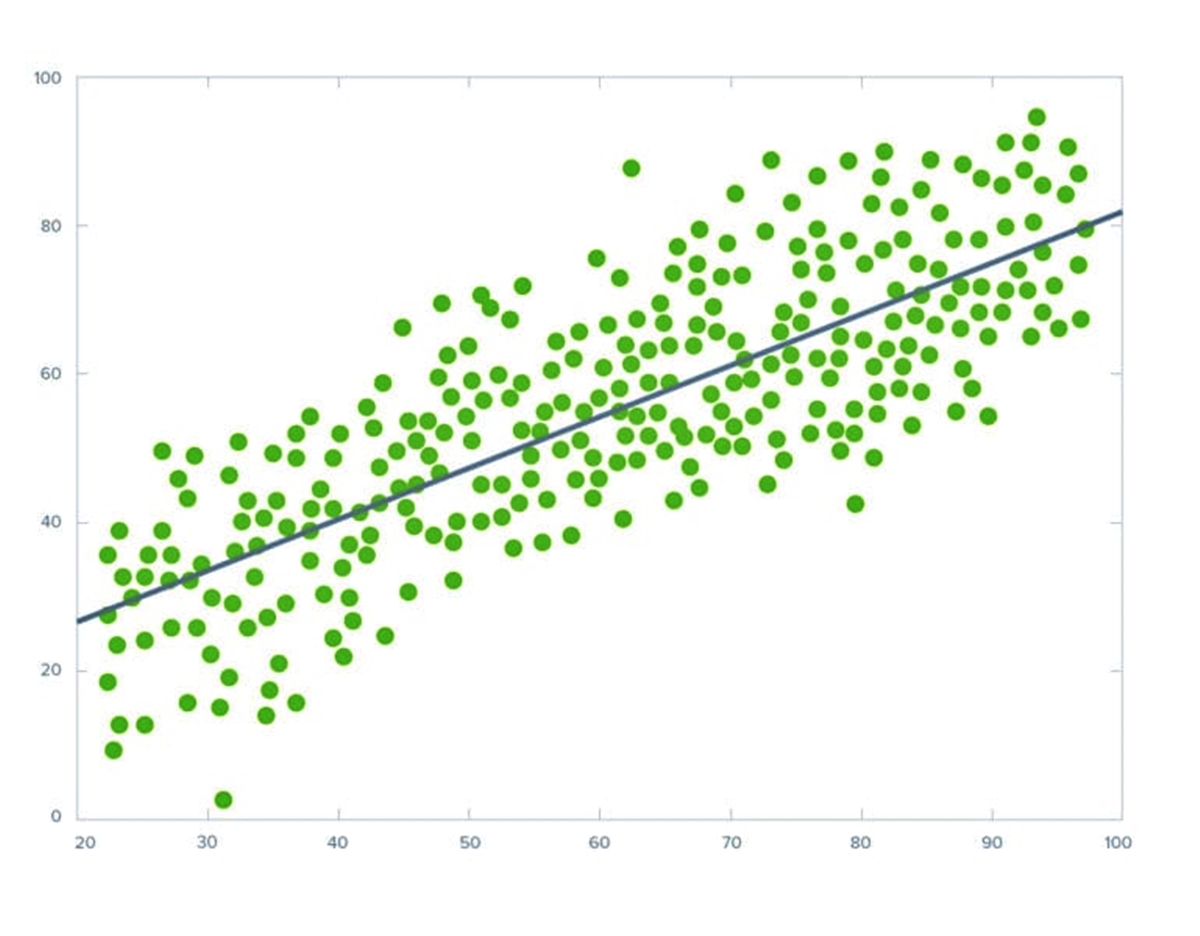
What is Regression?
Regression is a statistical analysis technique used in data mining to predict the relationships between variables. It involves modeling the dependent variable as a function of one or more independent variables. Regression allows us to make predictions and understand the impact of changes in the independent variables on the dependent variable.
In simpler terms, regression helps us understand how one variable influences another and to predict how a change in the independent variable(s) will affect the dependent variable. It provides a quantitative understanding of the relationships between variables, allowing us to gain insights, make informed decisions, and develop predictive models.
Regression models establish a mathematical equation that represents the relationship between variables. This equation is derived by analyzing the data and fitting a regression line or curve through the data points. The most common form of regression is linear regression, which assumes a linear relationship between the variables.
Regression can also handle nonlinear relationships by using nonlinear regression models, polynomial regression, or other advanced techniques that capture the complexity of the data. Moreover, regression can be applied to both numeric and categorical data, making it a versatile tool in data mining.
Regression analysis plays a crucial role in various fields, including finance, economics, healthcare, social sciences, marketing, and many others. It helps in predicting stock prices, estimating market demand, understanding customer behavior, analyzing medical data, and solving various real-world problems.
Overall, regression is a powerful statistical analysis technique that allows us to uncover important relationships and patterns within data. By understanding these relationships, we can make informed decisions, make accurate predictions, and gain valuable insights into the factors that influence the dependent variable.
Why is Regression Important in Data Mining?
Regression is a fundamental tool in data mining with several important applications. Here are some key reasons why regression is crucial in data mining:
- Prediction: Regression enables us to make accurate predictions based on historical data. By understanding the relationships between variables, we can develop regression models that can be used to forecast future outcomes or estimate unknown values. For example, regression analysis can be used to predict customer churn, sales volume, or housing prices.
- Variable Importance: Regression helps identify the key variables that have the most significant impact on the dependent variable. By analyzing the coefficients in the regression equation, we can determine which variables are more influential in driving the outcomes. This information is valuable for decision-making and resource allocation.
- Trend Analysis: Regression allows us to analyze trends and patterns in the data. By fitting a regression line to the data points, we can determine if there is a positive or negative relationship between the variables. This insight helps in understanding how variables change together and can be used in forecasting and strategic planning.
- Validation and Model Assessment: Regression analysis provides a framework for evaluating the accuracy and performance of predictive models. By comparing the predicted values to the actual values, we can assess the model’s effectiveness and determine if it meets the desired criteria. This validation process helps in refining the model and making necessary adjustments.
- Causal Analysis: Regression models can be used to test hypotheses and determine causal relationships between variables. By controlling for other factors, regression helps in isolating and understanding the effects of specific variables on the dependent variable. This information aids in decision-making and policy formulation.
Regression analysis is not only important for making predictions and understanding relationships but also for extracting valuable insights from data. It provides a systematic framework for analyzing and exploring the complex relationships between variables, which can lead to actionable recommendations and data-driven decision-making.
Types of Regression Models
Regression analysis offers a range of models to capture different types of relationships between variables. Here are some common types of regression models:
- Simple Linear Regression: This is the basic form of regression that models the relationship between two variables, one dependent and one independent. It assumes a linear relationship, where a straight line is fitted to the data points.
- Multiple Linear Regression: In this model, multiple independent variables are considered to predict the dependent variable. It allows for more complex relationships, where the dependent variable is influenced by multiple factors simultaneously.
- Polynomial Regression: Polynomial regression accommodates curvilinear relationships by including polynomial terms of the independent variables. It can capture U-shaped, inverted U-shaped, or other non-linear patterns that cannot be captured by linear regression.
- Logistic Regression: Logistic regression is used when the dependent variable is categorical or binary. It models the probability of an event occurring based on the independent variables. It is widely used in classification problems, such as predicting whether a customer will churn or not.
- Nonlinear Regression: Nonlinear regression is employed when the relationship between the dependent and independent variables is not linear and cannot be adequately captured by a straight line or a polynomial curve. It uses more complex and flexible functions to fit the data.
- Stepwise Regression: Stepwise regression is a technique used to select the most relevant independent variables to include in the regression model. It automatically adds or removes variables based on statistical measures like p-values or adjusted R-squared, optimizing the model’s performance.
Each type of regression model has its own assumptions and is applicable in different scenarios based on the data and research objectives. The choice of the regression model depends on factors such as the nature of the data, the underlying relationship between variables, and the goals of the analysis.
It is worth noting that these are just a few examples of regression models, and there are other variations and advanced techniques available. Data analysts and statisticians often employ more specialized models based on the unique characteristics of their data.
Simple Linear Regression
Simple linear regression is a basic form of regression analysis that explores the relationship between two continuous variables: a dependent variable (Y) and an independent variable (X). It assumes a linear relationship, where a straight line is fitted to the data points to approximate the trend. This model can be represented by the equation: Y = b0 + b1X.
The goal of simple linear regression is to determine the best-fit line that minimizes the overall distance between the observed data points and the predicted values on the line. The coefficients b0 (intercept) and b1 (slope) are estimated from the data using statistical techniques like the least squares method.
The intercept (b0) represents the expected value of the dependent variable (Y) when the independent variable (X) is zero. It is the point where the regression line intersects the Y-axis. The slope (b1) represents the change in the dependent variable for a one-unit increase in the independent variable.
By analyzing the coefficients, we can determine the direction and strength of the relationship between the variables. A positive slope indicates a positive relationship, where as X increases, Y also tends to increase. Conversely, a negative slope indicates an inverse relationship, where as X increases, Y tends to decrease. The magnitude of the slope determines the steepness of the line.
Simple linear regression can be used for various purposes, such as predicting an outcome (Y) based on a given value of X or estimating the effect of a change in X on Y. It provides insights into the relationship between the variables and helps in understanding the linear trend.
Evaluating the quality of the simple linear regression model involves analyzing statistical measures such as the coefficient of determination (R-squared) and the standard error of the estimate. R-squared measures the proportion of the variability in the dependent variable that is explained by the independent variable. A higher R-squared indicates a better fit. The standard error of the estimate quantifies the average distance between the observed Y values and the predicted Y values.
It’s important to note that simple linear regression has certain assumptions, including linearity, independence of observations, constant variance (homoscedasticity), and normality of residuals. Violations of these assumptions may affect the validity and accuracy of the regression model.
Overall, simple linear regression provides a straightforward and useful approach to analyzing the relationship between two continuous variables. It serves as a foundation for more advanced regression techniques and helps in making predictions and understanding the impact of the independent variable on the dependent variable.
Multiple Linear Regression
Multiple linear regression is an extension of simple linear regression that allows for the modeling of the relationship between a dependent variable (Y) and multiple independent variables (X1, X2, X3, …, Xn). It assumes a linear relationship, but considers the combined effects of multiple predictors on the dependent variable. The multiple linear regression model can be represented by the equation: Y = b0 + b1X1 + b2X2 + b3X3 + … + bnXn.
The goal of multiple linear regression is to estimate the coefficients (b0, b1, b2, …, bn) that provide the best-fit line or hyperplane through the data points. Each coefficient represents the change in the dependent variable for a one-unit increase in the corresponding independent variable, holding other variables constant.
Multiple linear regression enables us to analyze the relative influence and contribution of each independent variable on the dependent variable. By examining the coefficients, we can determine the direction and magnitude of the relationships. A positive coefficient indicates a positive relationship, where an increase in the independent variable is associated with an increase in the dependent variable. Conversely, a negative coefficient indicates an inverse relationship.
Additionally, multiple linear regression allows for the identification of potential interactions between the independent variables. It helps in understanding how the relationship between the dependent variable and one predictor may change based on the values of other predictors.
Evaluating the quality and usefulness of the multiple linear regression model involves analyzing statistical measures such as the coefficient of determination (R-squared), adjusted R-squared, and the analysis of variance (ANOVA). R-squared measures the proportion of the variability in the dependent variable that is explained by the independent variables. Adjusted R-squared takes into account the number of predictors and adjusts R-squared accordingly. ANOVA tests the overall significance of the model by comparing the variation between the predicted values and the actual values.
It is important to note that multiple linear regression assumes certain assumptions similar to simple linear regression, including linearity, independence of observations, constant variance (homoscedasticity), and normality of residuals. Violations of these assumptions may impact the accuracy and validity of the regression model.
Multiple linear regression is widely used in various fields, including economics, social sciences, business, and healthcare. It provides a powerful tool for analyzing complex relationships and making predictions based on multiple predictors. By understanding the effects of multiple variables on the dependent variable, decision-makers can gain insights and make more informed choices.
Polynomial Regression
Polynomial regression is a type of regression analysis that allows for the modeling of nonlinear relationships between the dependent variable (Y) and the independent variable (X). It extends the concept of simple and multiple linear regression by including higher-order polynomial terms of the independent variable. The polynomial regression model can be represented by the equation: Y = b0 + b1X + b2X^2 + b3X^3 + … + bnx^n.
Polynomial regression is useful when the relationship between the variables cannot be adequately captured by a straight line or a simple curve. It can capture U-shaped, inverted U-shaped, or other curvilinear patterns in the data. The addition of higher-order terms provides flexibility in fitting a curve to the data points, allowing for a better representation of the underlying relationship.
The degree of the polynomial determines the complexity of the curve. A quadratic equation (degree 2) includes a squared term, allowing for a parabolic shape. A cubic equation (degree 3) includes a cubed term, capturing more curvature. Higher-degree polynomials can capture even more intricate shapes, but it’s important to strike a balance between flexibility and overfitting the data.
Evaluating the quality of the polynomial regression model involves analyzing statistical measures like R-squared, adjusted R-squared, and the residual plot. R-squared measures the proportion of the variability in the dependent variable that is explained by the polynomial model. Adjusted R-squared adjusts for the number of predictors. The residual plot helps in assessing if the residuals are randomly distributed around zero, indicating a good fit.
It’s important to note that polynomial regression has its limitations. As the degree of the polynomial increases, the model may become too complex and may fit the noise in the data rather than the true underlying relationship. Overfitting can occur, leading to poor generalization to new data. Therefore, careful consideration is necessary in selecting the appropriate degree of the polynomial.
Polynomial regression finds applications in various fields such as physics, engineering, finance, and social sciences. It enables the analysis of nonlinear relationships and provides insights into the behavior of variables across a wide range of domains. By applying polynomial regression, researchers and analysts can more accurately model and understand complicated data patterns.
Logistic Regression
Logistic regression is a type of regression analysis commonly used when the dependent variable is categorical or binary. It aims to determine the probability and classify an event or outcome based on one or more independent variables. Unlike linear regression which predicts continuous values, logistic regression predicts the likelihood of an event occurring or not occurring.
The logistic regression model calculates the probability of the event happening as a function of the independent variables. It uses a logistic function, also known as the sigmoid function, to transform the linear combination of the independent variables into a probability ranging from 0 to 1. The logistic regression equation can be represented as: P(Y=1) = 1 / (1 + e^-(b0 + b1X1 + b2X2 + … + bnxn)).
The coefficients (b0, b1, b2, …, bn) in the logistic regression equation are estimated through maximum likelihood estimation. These coefficients represent the impact of each independent variable on the log-odds of the event occurring. By applying a threshold (typically 0.5), predictions can be made – values above the threshold indicating the event is likely to occur, and values below the threshold indicating it is not.
Logistic regression is particularly useful in binary classification problems where the dependent variable has two categories. It can predict outcomes such as whether a customer will churn or not, whether a patient will be diagnosed with a disease or not, or whether an email is spam or not. It is widely used in various fields including healthcare, marketing, finance, and social sciences.
Evaluating the performance of a logistic regression model involves examining statistical measures such as accuracy, precision, recall, and the receiver operating characteristic (ROC) curve. Accuracy measures the proportion of correct predictions made by the model. Precision measures how well the model predicts positive cases correctly. Recall measures the model’s ability to identify all positive cases. The ROC curve provides a visualization of the model’s trade-off between true positive rate and false positive rate.
Logistic regression assumes several assumptions, including linearity, independence of observations, absence of multicollinearity, and absence of influential outliers. Violations of these assumptions can impact the reliability and validity of the logistic regression model.
Overall, logistic regression provides a powerful tool for analyzing and predicting categorical outcomes. By understanding the relationship between independent variables and the probability of an event occurring, logistic regression enables informed decision-making and classification tasks.
Nonlinear Regression
Nonlinear regression is a versatile regression analysis technique that allows for the modeling of complex relationships between the dependent variable (Y) and the independent variables (X). Unlike linear regression, which assumes a linear relationship, nonlinear regression accommodates curves, exponential functions, logarithmic functions, and other nonlinear patterns.
In nonlinear regression, the relationship between the variables is modeled by a nonlinear equation or function. The specific form of the equation depends on the underlying relationship and the nature of the data. Nonlinear regression models are estimated using statistical techniques such as the method of least squares, maximum likelihood estimation, or other optimization algorithms.
The flexibility of nonlinear regression enables the capture of intricate relationships that cannot be accurately represented by linear models. It is particularly useful when analyzing real-world phenomena that exhibit nonlinear behavior, such as population growth, disease progression, or chemical reactions.
Evaluating the quality of a nonlinear regression model involves assessing statistical measures such as R-squared, adjusted R-squared, and residual analysis similar to linear regression. R-squared represents the proportion of the variability in the dependent variable explained by the model, while adjusted R-squared adjusts for the number of predictors. Residual analysis helps determine if the model adequately captures the patterns and variability in the data.
Nonlinear regression models can be more challenging to estimate and interpret compared to linear regression models. They often require more advanced statistical techniques and computational algorithms. Additionally, selecting the appropriate nonlinear equation and optimizing the model can be complex, requiring careful consideration and domain expertise.
Nonetheless, nonlinear regression provides a powerful tool for analyzing relationships and making predictions in various fields of study. It helps researchers and analysts gain insights into the complex dynamics of the variables under investigation and develop models that better represent real-world phenomena.
It is important to note that, like other regression techniques, nonlinear regression relies on certain assumptions, including independence of observations, homoscedasticity, and normality of residuals. Violations of these assumptions may affect the validity and accuracy of the nonlinear regression model.
Overall, nonlinear regression is a valuable method for modeling and understanding complex relationships between variables. By allowing for more flexible and realistic representations of the data, it opens up opportunities for deeper analysis and more accurate predictions.
Stepwise Regression
Stepwise regression is a technique used to select the most relevant independent variables to include in a regression model. It helps in automatically determining the optimal subset of predictors that contribute the most to explaining the variation in the dependent variable.
Stepwise regression operates in an iterative manner, starting with an initial model that includes either all or none of the independent variables. It then goes through a sequence of steps, either forward or backward, to add or remove variables based on statistical criteria such as p-values, adjusted R-squared, or Akaike Information Criterion (AIC).
In forward stepwise regression, the process begins with an empty model and adds variables one by one, selecting the variable that results in the greatest improvement in the model’s fit. The process continues until further addition of variables does not contribute significantly to the model.
In backward stepwise regression, the process starts with a model that includes all independent variables and removes variables one by one, eliminating the variable with the least contribution to the model’s fit at each step. The process continues until further removal of variables does not significantly impact the model’s fit.
Stepwise regression offers several advantages. It automates the variable selection process, helping to identify a parsimonious model that maximizes predictive accuracy while minimizing unnecessary complexity. It also provides statistical measures, such as p-values, to assess the significance and contribution of each variable.
However, stepwise regression does have limitations. It may lead to overfitting the model if not performed cautiously, as selecting variables based solely on statistical significance may introduce noise and multicollinearity issues. Additionally, the selected model is dependent on the specific dataset used, and there is a risk of excluding important variables if not considered in the initial model.
Stepwise regression is a valuable tool in exploratory analysis and model building, allowing researchers to subset a large pool of potential predictors and select the most relevant variables. However, it should be used judiciously in conjunction with subject matter expertise and consideration of theoretical relevance to ensure the resulting model is meaningful and accurate.
By automating the variable selection process and providing statistical measures for evaluation, stepwise regression facilitates the creation of robust regression models that best represent the relationship between the dependent and independent variables.
How Does Regression Work in Data Mining?
Regression analysis plays a crucial role in data mining by uncovering relationships and patterns between variables. It helps in understanding how changes in independent variables impact the dependent variable and enables the development of predictive models. Here’s how regression works in data mining:
1. Collecting and Preparing Data: The first step in regression analysis is to collect and preprocess the relevant data. This involves gathering data on the dependent variable and the independent variables, ensuring data quality, handling missing values, and transforming variables if needed.
2. Choosing the Right Regression Model: Based on the nature of the data and the research question, the appropriate regression model is selected. This could be simple linear regression, multiple linear regression, polynomial regression, logistic regression, or another suitable model.
3. Training and Testing the Regression Model: Once the model is chosen, the dataset is split into a training set and a testing set. The training set is used to build the regression model by estimating the coefficients or parameters. The testing set is then used to evaluate the model’s performance and validate its predictive ability.
4. Evaluating the Accuracy of the Regression Model: Various statistical measures and diagnostic tools are employed to assess the accuracy and goodness-of-fit of the regression model. These measures include R-squared, adjusted R-squared, standard error of the estimate, hypothesis testing, residual analysis, and other relevant evaluation metrics.
5. Making Predictions with Regression: Once the regression model is deemed accurate and reliable, it can be used to make predictions or estimate values of the dependent variable based on new or unseen data. This enables forecastings, estimations, or classifications, depending on the type of regression model used and the research objective.
6. Continuously Refining the Model: The process of regression analysis is iterative and dynamic. As new data becomes available or as the research goals evolve, the regression model can be refined, recalibrated, or updated to improve its performance and adapt to changing circumstances.
Regression analysis in data mining allows researchers and data scientists to analyze large datasets, uncover hidden relationships, and build predictive models. It provides a quantitative framework to understand the impact of variables on a target outcome, aids in decision-making, and enables accurate predictions and forecasts.
Overall, regression analysis forms an essential component of data mining, facilitating insights, predictions, and evidence-based decision-making in a wide range of industries and research domains.
Collecting and Preparing Data for Regression
Collecting and preparing data is a crucial step in regression analysis to ensure the accuracy and reliability of the regression model. Here’s a breakdown of the process:
1. Data Collection: The first step is to gather data on the dependent variable (the variable being predicted or explained) and the independent variables (the predictors). This data can come from various sources, such as surveys, databases, experiments, or observations.
2. Data Cleaning: Once the data is collected, it needs to be cleaned to eliminate any errors, inconsistencies, or missing values. This involves checking for outliers, handling missing data through imputation or exclusion, and verifying the accuracy and integrity of the data.
3. Data Exploration: Exploratory data analysis (EDA) is carried out to gain insights into the data and understand the relationships between variables. This includes analyzing summary statistics, creating visualizations (such as scatter plots or histograms), and identifying any patterns or trends.
4. Variable Selection: In regression analysis, it is essential to select the right variables that have a meaningful impact on the dependent variable. This involves assessing the relevance, significance, and potential multicollinearity (correlation between independent variables) of each variable. Variables that are irrelevant or highly correlated may be excluded from the analysis.
5. Data Transformation: Sometimes, variables may need to be transformed to meet certain assumptions of regression analysis. Common transformations include logarithmic, exponential, or polynomial transformations to achieve linearity or equalize variances. Additionally, categorical variables may be converted into dummy variables to incorporate them into the regression model.
6. Data Scaling and Standardization: Scaling or standardizing the variables may be necessary to ensure that the variables are on a similar scale. This is especially important when variables have different units or scales, preventing one variable from dominating the others in the analysis.
7. Data Splitting: To evaluate the performance of the regression model, the dataset is split into a training set and a testing set. The training set is used to build the model, while the testing set is reserved to assess the model’s predictive accuracy on new or unseen data.
Collecting and preparing data for regression analysis requires attention to detail, thoroughness, and adherence to data quality standards. The quality of the data and the appropriateness of variables significantly impact the accuracy and validity of the regression model. Through careful data collection and preparation, researchers can ensure that the resulting regression model provides meaningful insights and reliable predictions.
Choosing the Right Regression Model
Choosing the appropriate regression model is a crucial step in regression analysis as it impacts the accuracy and interpretability of the results. The choice of the regression model depends on factors such as the nature of the data, the relationship between the variables, and the research objectives. Here’s a guide on selecting the right regression model:
1. Simple Linear Regression: Simple linear regression is suitable when there is a single independent variable that is believed to have a linear relationship with the dependent variable. This model assumes a straight-line relationship between the variables and can be a good starting point for analyzing simple relationships.
2. Multiple Linear Regression: Multiple linear regression accommodates situations where there are multiple independent variables that can simultaneously influence the dependent variable. It is applicable when these variables are believed to have independent and additive effects on the outcome.
3. Polynomial Regression: Polynomial regression is used when the relationship between the variables is curvilinear, rather than linear. It includes polynomial terms, such as squared or cubed terms, to capture the non-linear patterns in the data. This model can better fit U-shaped or inverted U-shaped relationships.
4. Logistic Regression: Logistic regression is ideal when the dependent variable is categorical or binary. It predicts the probability of an event occurring based on the independent variables. It is commonly used in classification problems, such as predicting whether a customer will churn or not.
5. Nonlinear Regression: Nonlinear regression is appropriate when the relationship between the dependent and independent variables cannot be adequately captured by linear or polynomial models. It allows for more complex and flexible models, fitting more intricate shapes to the data.
6. Stepwise Regression: Stepwise regression is employed when there is a large pool of potential independent variables. It automates the variable selection process, adding or removing variables based on statistical criteria such as p-values or adjusted R-squared, to build an optimal regression model.
The choice of the regression model should be informed by a combination of theoretical knowledge, exploratory data analysis, and statistical assessments. It is crucial to consider the underlying relationship between the variables, the assumptions of the selected model, and the interpretability of the results.
It is worth noting that the selection process may involve trial and error, testing different models, and comparing their performance using evaluation metrics such as R-squared, residual analysis, AIC, or other relevant measures to identify the best-fitting model.
By carefully selecting the most appropriate regression model, researchers can uncover meaningful relationships, make accurate predictions, and gain insights into the factors influencing the dependent variable.
Training and Testing the Regression Model
Training and testing the regression model is a crucial step in regression analysis to evaluate the model’s performance and ensure its predictive accuracy. This process involves splitting the dataset into two subsets: the training set and the testing set. Here’s an overview of training and testing the regression model:
1. Data Splitting: The dataset is divided into the training set and the testing set. Typically, the majority of the data (e.g., 70-80%) is allocated to the training set, while the remainder is reserved for testing the model’s performance.
2. Building the Regression Model: The training set is used to build the regression model. The model is constructed by estimating the coefficients or parameters that define the relationship between the independent variables and the dependent variable. This estimation process involves techniques like the method of least squares or maximum likelihood estimation.
3. Model Validation: Once the model is constructed using the training set, it needs to be validated on the testing set. The testing set serves as independent data to assess the model’s accuracy and generalizability. The model’s ability to predict outcomes on unseen data is evaluated using various evaluation metrics.
4. Evaluation Metrics: To assess the model’s performance, several evaluation metrics are utilized. Common metrics include R-squared, which measures the proportion of the variability in the dependent variable that is explained by the model, as well as metrics such as mean squared error (MSE) or root mean squared error (RMSE) that quantify the average prediction error.
5. Overfitting and Underfitting: The testing set helps identify whether the model suffers from overfitting or underfitting. Overfitting occurs when the model performs exceptionally well on the training set but poorly on the testing set, indicating that the model has captured noise or irrelevant patterns in the data. Underfitting occurs when the model fails to capture the underlying patterns and performs poorly on both the training and testing sets.
6. Model Refinement: Based on the model’s performance on the testing set, adjustments or refinements may be necessary. This might involve feature selection, regularization techniques, or revisiting the model assumptions. Iterative refinement of the model can improve its predictive accuracy and generalizability.
Training and testing the regression model helps in assessing its ability to make accurate predictions on new or unseen data. By validating the model on an independent dataset, researchers can evaluate and fine-tune the model to ensure reliable and accurate predictions in real-world scenarios.
Evaluating the Accuracy of the Regression Model
Evaluating the accuracy of the regression model is crucial to assess its performance and reliability. By examining various statistical measures and diagnostic tools, researchers can determine how well the model fits the data and make informed decisions based on the results. Here are key aspects of evaluating the accuracy of a regression model:
1. R-squared: R-squared, also known as the coefficient of determination, measures the proportion of the variability in the dependent variable that is explained by the independent variables. Higher R-squared values indicate a better fit of the model to the data, with values closer to 1 representing a stronger relationship between the variables.
2. Adjusted R-squared: Adjusted R-squared takes into account the number of predictors in the model, penalizing the inclusion of unnecessary variables. It provides a more conservative estimate of the model’s goodness-of-fit, serving as a useful metric when comparing models with different numbers of predictors.
3. Standard Error of the Estimate: The standard error of the estimate (also known as the root mean square error or residual standard error) quantifies how closely the predicted values align with the actual values. It measures the average distance between the observed dependent variable values and the predicted values from the regression model. A lower standard error indicates a better fit.
4. Hypothesis Testing: Hypothesis tests can be conducted on the regression coefficients to assess their statistical significance. The p-values associated with each coefficient indicate the probability of observing such a coefficient value by chance if there were no true relationship between the variables. Small p-values (typically below 0.05) suggest a significant relationship.
5. Residual Analysis: Residual analysis involves examining the residuals (the differences between the observed and predicted values) to assess the model’s adequacy. Residual plots can reveal patterns or trends that indicate violation of assumptions, such as nonlinearity or heteroscedasticity. Ideally, the residuals should exhibit randomness and have a mean of zero.
6. Cross-Validation: Cross-validation techniques, such as k-fold cross-validation, can be employed to further evaluate the model’s performance. By partitioning the data into multiple subsets and iteratively training and testing the model on different folds, one can assess its generalizability and robustness to different data samples.
It is important to approach the evaluation process holistically, considering multiple measures rather than relying solely on one metric. A well-evaluated regression model should have a high R-squared value, significant and interpretable coefficients, small standard error of the estimate, minimal deviations in residual plots, and satisfactory results in cross-validation.
Care must be taken to ensure that the evaluation reflects the specific goals and requirements of the analysis. Different evaluation criteria may be more important in different contexts, and additional domain-specific considerations should be taken into account when assessing the validity and usefulness of the regression model.
Making Predictions with Regression
One of the primary purposes of regression analysis is to make predictions based on the relationships and patterns uncovered in the data. Once a regression model is developed and validated, it can be used to forecast or estimate values of the dependent variable for new or unseen data. Here’s how predictions are made with regression:
1. Data Preparation: Before making predictions, it is important to ensure that the new data is properly prepared and processed. This involves applying the same data transformations and scaling as done during the training and testing phase of the regression model. The new data should be structured in a way that matches the format of the training data.
2. Feature Selection: If there was feature selection involved in building the regression model, it is essential to include the same set of variables in the prediction process. The independent variables should align with the original model’s specifications to maintain consistency and accuracy in the predictions.
3. Coefficient Application: Using the estimated coefficients from the regression model, the predicted values of the dependent variable for the new data are calculated. The independent variables in the new data are multiplied by their corresponding coefficients, and the intercept term (if present) is added to obtain the predicted value.
4. Interpretation and Limitations: The predicted values obtained from regression should be interpreted with caution. While regression models provide valuable insights, it is crucial to remember that predictions are subject to certain limitations. These include assumptions of linearity, independence, and constant variability, as well as potential issues related to extrapolation or prediction outside the range of the original data.
5. Model Evaluation: After making predictions, it is advisable to evaluate the performance of the regression model on the new data. This may involve comparing the predicted values to the actual observed values and analyzing performance metrics such as mean squared error or R-squared to assess the accuracy and goodness of fit of the predictions.
6. Iterative Model Refinement: Based on the performance evaluation of the predictions, adjustments to the model can be made if necessary. This could involve retraining the model on a combined dataset of new and old data, updating coefficients, or revisiting the feature selection process.
Making predictions with regression allows for informed decision-making and forecasting. By incorporating new data into the established regression model, organizations can gain insights into future outcomes, estimate values of the dependent variable, and make data-driven decisions in various domains such as finance, marketing, healthcare, and social sciences.
Common Challenges and Pitfalls in Regression Analysis
Regression analysis is a powerful tool, but it comes with its own set of challenges and potential pitfalls. Understanding these challenges is crucial to ensure accurate and reliable results. Here are some common challenges and pitfalls in regression analysis:
1. Violations of Assumptions: Regression models assume certain conditions, including linearity, independence of observations, constant variance (homoscedasticity), and normality of residuals. Violating these assumptions can lead to biased estimates and inaccurate predictions. It is important to check for violations and, if necessary, apply transformations or consider alternative modeling techniques.
2. Multicollinearity: Multicollinearity occurs when independent variables in a regression model are highly correlated. This leads to difficulties in estimating the unique contribution of each variable and can result in unstable coefficients and erroneous interpretations. It is important to assess multicollinearity and, if present, consider variable selection techniques or other approaches to address it.
3. Overfitting and Underfitting: Overfitting occurs when the regression model fits the noise or random fluctuations in the training data rather than the true underlying relationship. This can result in poor performance on new data. Underfitting, on the other hand, occurs when the model is too simplistic and fails to capture the complexity of the relationship. Balancing the complexity of the model and the size of the dataset is crucial to avoid these issues.
4. Sample Size: The sample size plays a critical role in regression analysis. With a small sample size, the estimates may have high uncertainty and the model may have limited generalizability. It is important to ensure an adequate sample size to obtain reliable results, as larger samples tend to produce more robust estimates and better model performance.
5. Outliers and Influential Observations: Outliers are extreme observations that can strongly influence the regression model and distort the results. It is important to identify and handle outliers appropriately to prevent them from unduly impacting the model’s coefficients and predictions.
6. Variable Selection Bias: Variable selection, especially when conducted based solely on statistical significance, can introduce bias and lead to models that do not reflect the true underlying relationships. It is essential to consider domain knowledge and theory when selecting variables to build a meaningful and interpretable model.
7. Extrapolation: Extrapolating beyond the range of the observed data can be risky, as regression models are built based on the relationships observed within the data range. Extrapolation may lead to unreliable predictions and unrealistic estimates. It is important to exercise caution when making predictions for values far outside the range of the observed data.
Awareness of these challenges and pitfalls is crucial in designing and interpreting regression analysis. Applying appropriate techniques for addressing these issues and considering the limitations of regression analysis can improve the reliability and usefulness of the results obtained.