
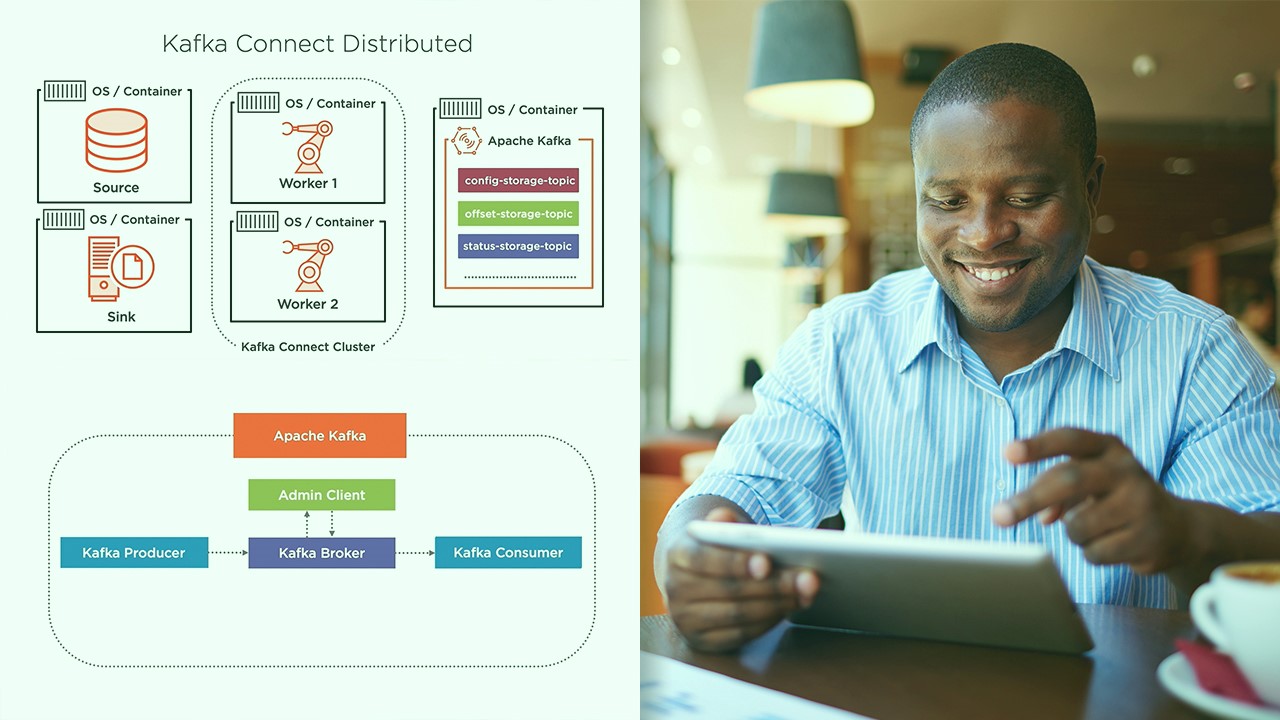
What is Kafka Connector?
Kafka Connect is a framework for connecting Apache Kafka with external systems such as databases, storage systems, and other data sources and sinks. Kafka Connectors are plugins that extend the functionality of Kafka Connect, enabling seamless integration with a wide range of systems. These connectors facilitate the efficient and scalable transfer of data between Kafka and external systems, making it easier to build robust data pipelines.
Kafka Connectors serve as the bridge between Kafka and various data sources and sinks, allowing users to easily ingest data into Kafka topics or extract data from Kafka topics for further processing or storage. By leveraging Kafka Connect, organizations can streamline the process of integrating Kafka with their existing data infrastructure, enabling real-time data processing and analysis.
Kafka Connectors are designed to handle both the source and sink of data, providing a unified and consistent approach to data integration. This versatility makes Kafka Connect a powerful tool for building scalable and reliable data pipelines that cater to diverse use cases across different industries.
Benefits of Using Kafka Connector
-
Simplified Integration: Kafka Connectors simplify the process of integrating Kafka with external systems, reducing the complexity and effort required to establish data pipelines.
-
Scalability: With Kafka Connectors, organizations can easily scale their data pipelines to accommodate growing data volumes and evolving business needs.
-
Robustness: Kafka Connectors are designed to ensure fault-tolerant and reliable data transfer, minimizing the risk of data loss or inconsistencies.
-
Extensibility: The availability of a wide range of pre-built connectors and the ability to develop custom connectors make Kafka Connect highly extensible, catering to diverse integration requirements.
-
Real-time Data Processing: Kafka Connectors enable real-time data ingestion and processing, empowering organizations to derive insights and take timely actions based on the latest data.
Types of Kafka Connectors
Kafka Connectors can be categorized into two main types: source connectors and sink connectors. Source connectors facilitate the ingestion of data from external systems into Kafka, while sink connectors enable the export of data from Kafka to external systems.
-
Source Connectors: These connectors pull data from external systems and publish it to Kafka topics, allowing users to consume and process the data within the Kafka ecosystem.
-
Sink Connectors: Sink connectors subscribe to Kafka topics and deliver the data to external systems, enabling seamless integration with databases, storage systems, and other downstream applications.
The availability of a diverse set of connectors for popular systems such as databases, file systems, cloud services, and messaging platforms makes Kafka Connect a versatile and adaptable solution for data integration.
In the next sections, we will explore the process of setting up Kafka Connectors, as well as the management and monitoring aspects of Kafka Connectors, providing insights into harnessing the full potential of Kafka Connect for seamless data integration and processing.
Benefits of Using Kafka Connector
Kafka Connectors offer a myriad of advantages that significantly enhance the data integration capabilities of Apache Kafka. By leveraging Kafka Connectors, organizations can streamline their data pipelines and achieve seamless connectivity with a diverse array of external systems. Below are the key benefits of using Kafka Connectors:
- Simplified Integration: Kafka Connectors simplify the process of integrating Kafka with external systems, reducing the complexity and effort required to establish data pipelines. This streamlined approach accelerates the implementation of data integration solutions, allowing organizations to focus on deriving value from their data rather than grappling with intricate integration challenges.
- Scalability: With Kafka Connectors, organizations can easily scale their data pipelines to accommodate growing data volumes and evolving business needs. The inherent scalability of Kafka Connectors enables seamless expansion of data integration capabilities, ensuring that the infrastructure can handle increasing data loads without compromising performance or reliability.
- Robustness: Kafka Connectors are designed to ensure fault-tolerant and reliable data transfer, minimizing the risk of data loss or inconsistencies. This robustness is essential for maintaining data integrity and consistency across diverse systems, providing assurance that data is accurately and securely transferred between Kafka and external sources or sinks.
- Extensibility: The availability of a wide range of pre-built connectors and the ability to develop custom connectors make Kafka Connect highly extensible, catering to diverse integration requirements. This extensibility empowers organizations to seamlessly connect with various systems, applications, and data sources, fostering a flexible and adaptable data integration ecosystem.
- Real-time Data Processing: Kafka Connectors enable real-time data ingestion and processing, empowering organizations to derive insights and take timely actions based on the latest data. This real-time capability is instrumental in enabling agile decision-making, facilitating rapid responses to changing business conditions, and supporting dynamic data-driven operations.
These benefits collectively underscore the transformative potential of Kafka Connectors in facilitating efficient, scalable, and reliable data integration. By harnessing the power of Kafka Connectors, organizations can unlock new opportunities for leveraging their data assets, driving innovation, and gaining a competitive edge in today’s data-driven landscape.
Next, we will delve into the various types of Kafka Connectors, shedding light on the distinct roles of source connectors and sink connectors in enabling seamless data exchange between Kafka and external systems.
Types of Kafka Connectors
Kafka Connectors encompass two primary types: source connectors and sink connectors, each playing a pivotal role in facilitating the seamless exchange of data between Apache Kafka and external systems. Understanding the distinct functions of these connector types is essential for orchestrating efficient data pipelines and integrating diverse data sources and sinks. Let’s explore the characteristics and roles of source connectors and sink connectors:
- Source Connectors: Source connectors serve as the entry point for data into the Kafka ecosystem. These connectors pull data from external systems, such as databases, file systems, cloud services, and messaging platforms, and publish it to Kafka topics. By ingesting data from various sources, source connectors enable the enrichment of Kafka with a continuous stream of diverse data, laying the foundation for real-time processing, analytics, and downstream consumption.
- Sink Connectors: On the other hand, sink connectors act as the exit point for data from Kafka, facilitating the seamless export of data to external systems. Sink connectors subscribe to Kafka topics and deliver the data to designated destinations, including databases, storage systems, and downstream applications. This outbound data flow enables the integration of Kafka with external systems, empowering organizations to leverage the data stored in Kafka for diverse operational and analytical purposes.
The distinction between source connectors and sink connectors underscores their complementary roles in orchestrating bidirectional data flows, enabling organizations to build robust and flexible data pipelines that cater to a spectrum of use cases. Whether it involves capturing real-time data from external sources or delivering processed data to downstream systems, Kafka Connectors provide the essential infrastructure for seamless data exchange and integration.
Furthermore, the availability of a diverse set of connectors for popular systems ensures that Kafka Connect can seamlessly integrate with a wide array of technologies, fostering interoperability and adaptability in data integration scenarios. This versatility empowers organizations to harness the full potential of Kafka Connectors in building agile, scalable, and resilient data pipelines that align with their specific business requirements and technological landscape.
Next, we will delve into the intricacies of setting up Kafka Connectors, providing insights into the configuration and deployment of connectors to facilitate efficient data exchange between Kafka and external systems.
Setting Up Kafka Connector
Configuring and deploying Kafka Connectors is a fundamental aspect of leveraging Apache Kafka’s data integration capabilities. The process of setting up Kafka Connectors involves defining the connector configurations, deploying the connectors, and establishing the necessary connections with external systems. Let’s explore the key steps involved in setting up Kafka Connectors:
Defining Connector Configurations
The first step in setting up Kafka Connectors is to define the connector configurations, which encompass the essential parameters for establishing the connection with external systems, specifying data transformation requirements, and configuring the behavior of the connectors. These configurations typically include details such as connector name, connector class, connection details for the external system, data format settings, and other relevant properties that govern the behavior of the connectors.
Deploying Connectors
Once the connector configurations are defined, the next step involves deploying the connectors within the Kafka Connect framework. This deployment process entails submitting the connector configurations to the Kafka Connect cluster, where the connectors are instantiated and managed. Depending on the deployment model, connectors can be deployed in standalone mode or distributed mode, with the latter offering scalability and fault tolerance benefits by leveraging a cluster of Kafka Connect workers.
Establishing Connections
After deploying the connectors, it is crucial to verify and establish the connections with the external systems. This involves validating the connectivity settings, ensuring that the required credentials and access permissions are in place, and testing the data transfer capabilities of the connectors. Establishing robust connections is essential for enabling seamless and reliable data exchange between Kafka and the external systems, laying the groundwork for efficient data integration and processing.
By following these steps, organizations can effectively set up Kafka Connectors, paving the way for streamlined data integration and enabling the seamless exchange of data between Kafka and a diverse array of external systems. The ability to configure, deploy, and manage connectors is instrumental in building agile and scalable data pipelines that cater to the evolving needs of modern data-driven enterprises.
Next, we will delve into the critical aspects of managing and monitoring Kafka Connectors, shedding light on the tools and practices that facilitate the efficient operation and optimization of Kafka Connectors within a data integration ecosystem.
Managing and Monitoring Kafka Connectors
Effective management and monitoring of Kafka Connectors are essential for ensuring the seamless operation, performance optimization, and fault-tolerant behavior of data integration pipelines within the Apache Kafka ecosystem. By employing robust management practices and leveraging monitoring tools, organizations can proactively oversee the health and functionality of their connectors, enabling timely interventions and continuous improvements. Let’s explore the key aspects of managing and monitoring Kafka Connectors:
Connector Lifecycle Management
Managing the lifecycle of Kafka Connectors involves tasks such as creating, modifying, pausing, and removing connectors as per the evolving data integration requirements. This entails utilizing administrative interfaces or RESTful APIs provided by Kafka Connect to interact with the connectors, enabling seamless management of their configurations and operational states. Effective lifecycle management ensures that connectors adapt to changing business needs and data sources, facilitating agility and responsiveness in data integration workflows.
Performance Monitoring and Optimization
Monitoring the performance of Kafka Connectors is critical for identifying bottlenecks, latency issues, and resource constraints that may impact the efficiency of data transfer and processing. By leveraging monitoring tools and metrics provided by Kafka Connect, organizations can gain insights into connector throughput, error rates, resource utilization, and other key performance indicators. This visibility enables proactive optimization efforts, such as fine-tuning configurations, scaling connector instances, and addressing performance-related challenges to maintain optimal data flow and processing capabilities.
Fault Tolerance and Error Handling
Ensuring fault tolerance and robust error handling mechanisms is integral to the reliable operation of Kafka Connectors. Organizations need to implement strategies for handling connector failures, recovering from errors, and maintaining data integrity during exceptional scenarios. This involves configuring connector resilience settings, defining error handling policies, and establishing recovery procedures to mitigate the impact of potential disruptions on data integration workflows, thereby ensuring the continuity of data exchange and processing.
By actively managing and monitoring Kafka Connectors, organizations can uphold the reliability, scalability, and efficiency of their data integration initiatives, fostering a resilient and adaptable ecosystem for seamless connectivity with external systems. The ability to proactively address operational challenges and optimize connector performance is instrumental in sustaining the agility and effectiveness of data pipelines within the Kafka environment.