
The Importance of Data in Machine Learning
Data is the lifeblood of machine learning. It serves as the foundation on which algorithms learn and make intelligent decisions. The quality and quantity of data directly impact the performance and accuracy of machine learning models. Without sufficient, relevant, and high-quality data, the effectiveness of machine learning algorithms can be severely limited.
Data plays a crucial role in training machine learning models. By feeding the algorithm with a diverse and extensive set of data, it can identify patterns, make predictions, and generate insights. The more varied and representative the data, the better-equipped the algorithm becomes in understanding and making accurate predictions in real-world scenarios.
Furthermore, data serves as the means of testing and validating the trained models. By evaluating the model’s performance against a separate set of data, known as the test data, we can gauge its accuracy and assess its generalizability to new, unseen data.
Simply put, without adequate data, machine learning algorithms lack the ability to learn and generalize effectively. They rely on historical data to make accurate predictions and recommendations for future inputs. The more data they have access to, the more informed and accurate their decisions become.
Additionally, data is crucial for addressing the issue of bias in machine learning algorithms. Bias can arise from imbalanced or incomplete data, resulting in biased predictions or discriminatory behavior. By ensuring inclusive and representative data sets, we can tackle these biases and build fair and unbiased models.
Understanding the Data Requirements for Machine Learning
Before diving into the process of acquiring and preparing data for machine learning, it’s essential to understand the specific requirements that make data suitable for training and testing machine learning models.
First and foremost, the data must be relevant to the problem at hand. It should capture the essential features and characteristics that the machine learning algorithm needs to learn and make accurate predictions. Irrelevant or noisy data can introduce unnecessary complexity and hinder the model’s performance.
Secondly, the data should be of sufficient quantity. While there is no predefined rule on how much data is exactly needed, having more data generally leads to more robust and accurate models. However, the quantity should be balanced with the quality of the data. It’s better to have a smaller but cleaner dataset than a large dataset plagued with errors and inconsistencies.
Another crucial aspect is the diversity of the data. The dataset should capture a wide range of scenarios, variations, and edge cases that the model may encounter in real-world situations. A lack of diversity can limit the model’s ability to generalize and perform accurately on new, unseen inputs.
Furthermore, the data should be labeled or annotated correctly, especially in supervised learning scenarios. Accurate labels provide ground truth information that guides the learning process. In some cases, obtaining labeled data can be expensive or time-consuming, requiring manual labeling or the assistance of domain experts.
Lastly, it’s important to consider the temporal aspect of the data. Time-sensitive data, such as sequential or time-series data, may require additional considerations for training and validation. Techniques like sliding windows or cross-validation can be employed to handle such temporal data effectively.
By understanding and meeting these data requirements, we can lay a solid foundation for building reliable and accurate machine learning models. The quality, quantity, relevance, diversity, labeling, and temporal aspects of the data should be carefully considered and addressed throughout the machine learning lifecycle.
How Much Data is Enough?
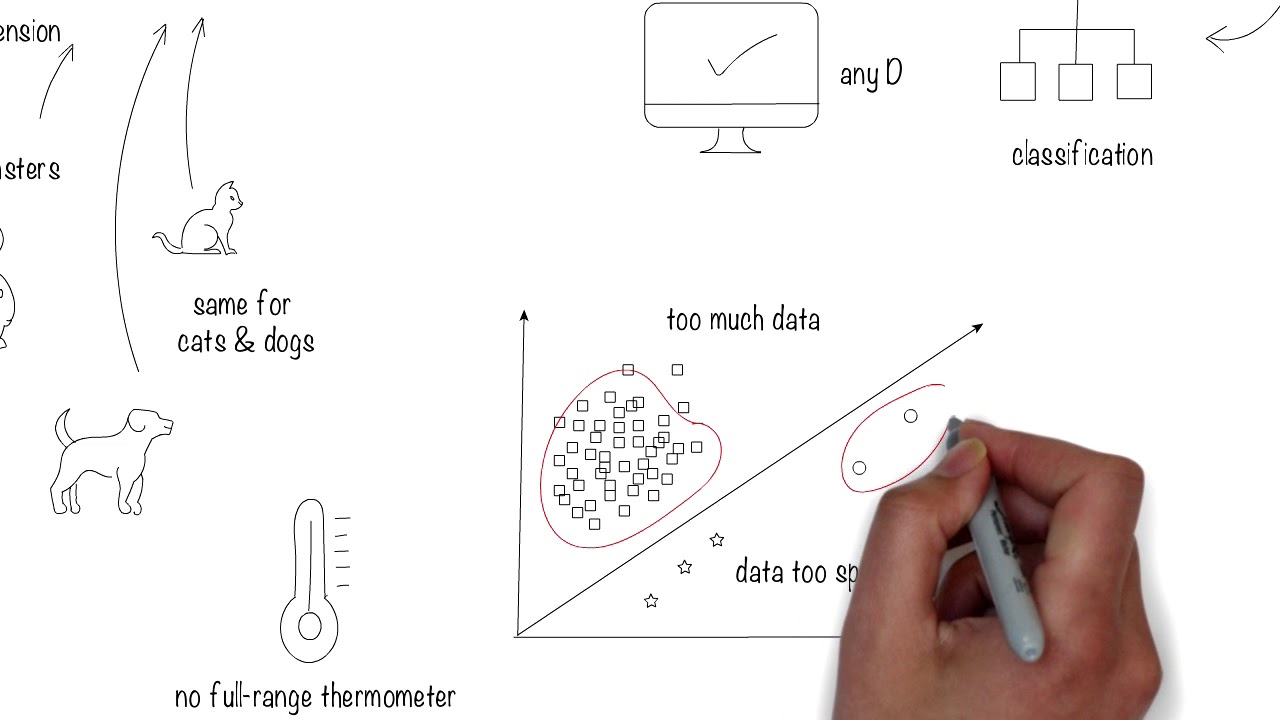
One common question that arises in the field of machine learning is how much data is needed to train accurate and effective models. While there is no definitive answer, the general consensus is that more data is beneficial, up to a certain point.
The amount of data required depends on various factors, including the complexity of the problem, the diversity of the data, and the algorithm being used. Simple problems with few variables may require less data, while complex problems with numerous variables may demand a larger dataset.
In practice, it’s recommended to start with a reasonably sized dataset and then gradually increase its size until the model’s performance plateaus. This is known as the learning curve, where additional data provides diminishing returns in terms of improving accuracy and performance.
However, the law of diminishing returns applies, and there is a point where adding more data does not significantly improve the model’s performance. This is known as the saturation point, where the model has learned most of the relevant patterns and additional data does not introduce significant new insights.
It’s important to note that the necessary amount of data may also vary depending on the algorithm employed. Deep learning models, which typically have a large number of parameters, may require massive datasets to effectively train. On the other hand, simpler algorithms like decision trees may achieve reasonable performance with smaller datasets.
Moreover, the quality and relevance of the data play a crucial role in determining the amount of data needed. High-quality, clean, and relevant data can often yield better results with smaller datasets compared to noisy or irrelevant data.
Therefore, when determining how much data is enough, it’s essential to strike a balance between the quantity and quality of the data. Starting with a reasonable-sized dataset, monitoring the learning curve, and assessing the model’s performance can help determine the optimal amount of data for a particular problem.
The Impact of Data Size on Machine Learning Models
The size of the dataset used for training machine learning models has a significant impact on their performance and generalization abilities. The more data available, the better the models can learn and make accurate predictions. Several key aspects highlight the impact of data size on machine learning models.
Firstly, a larger dataset can help mitigate the risk of overfitting. Overfitting occurs when a model becomes too complex and starts to memorize the training data instead of learning general patterns. With more data, models are exposed to a greater variety of examples, reducing the likelihood of overfitting and improving their ability to generalize to unseen data.
Secondly, a larger dataset provides more information for the models to learn from. It increases the chances of capturing rare or unusual instances, allowing the models to learn more robust representations of the data. This improved understanding of the data leads to better performance when encountering new, unseen examples during inference.
Furthermore, the impact of data size is particularly significant in deep learning models. Deep neural networks typically have a large number of parameters, and training them requires a substantial amount of data. Insufficient data can lead to the models’ inability to learn complex patterns, resulting in suboptimal performance.
However, it’s important to note that data size alone is not the sole determinant of model performance. The quality and diversity of the data also play crucial roles. A small dataset containing relevant and high-quality examples may outperform a larger but noisier dataset. Therefore, it is essential to strike a balance between data quantity and quality.
Moreover, with larger datasets, the computational requirements for training and inference increase. More data means more computations, longer training times, and potentially higher resource utilization. Therefore, it’s necessary to consider the available resources and infrastructure when dealing with large datasets.
The Trade-off Between Data Quantity and Data Quality
When it comes to data for machine learning, there is a trade-off between quantity and quality. While both are important, finding the right balance is crucial for effective model training and accurate predictions.
Data quantity refers to the size of the dataset, the number of examples or instances available for training. Having a larger dataset can provide more opportunities for the model to learn diverse patterns and make accurate predictions. It helps in capturing various variations, edge cases, and rare examples, thus improving the model’s ability to generalize to new, unseen data.
On the other hand, data quality focuses on the reliability, cleanliness, and relevance of the data. High-quality data helps in reducing noise, inconsistencies, and errors that can negatively impact the model’s performance. Quality data ensures that the learning process is based on accurate and valid representations of the problem at hand.
It’s important to strike a balance between data quantity and data quality because having more data does not automatically lead to improved performance. If the quality of the data is compromised, the accuracy and reliability of the model can be affected, even with a large dataset.
Collecting and curating a high-quality dataset can be a time-consuming and resource-intensive task. It often requires manual inspection, cleaning, and validation by domain experts. However, the effort is worth it, as high-quality data can lead to more reliable and accurate models.
It’s important to note that data quantity and data quality are not mutually exclusive. It’s possible to have a large dataset with high-quality data. On the other hand, small datasets can also be valuable if they are carefully curated and contain relevant examples.
When determining the trade-off between data quantity and quality, consider the problem complexity, available resources, and the specific requirements of the machine learning task. It may be beneficial to start with a smaller dataset of high-quality data and gradually increase its size if needed. Regular data validation and quality checks are essential throughout the machine learning lifecycle to ensure that the data remains reliable and relevant.
Techniques for Handling Limited Data
Handling limited data is a common challenge in machine learning, especially in scenarios where obtaining a large dataset is impractical or expensive. However, there are several techniques that can help mitigate the impact of limited data and improve model performance.
One approach is to employ data augmentation techniques. Data augmentation involves generating new training examples by applying various transformations to the existing data, such as rotation, scaling, cropping, or adding noise. This helps to artificially increase the diversity and quantity of the data, providing the model with more training examples to learn from.
Another technique is to leverage transfer learning. Transfer learning involves utilizing pre-trained models or using knowledge learned from a related task to boost performance on a new, limited data task. By transferring the knowledge learnt from a larger dataset or a similar problem domain, the model can generalize better on the limited data available.
Active learning can also be used to make the most out of limited data. Active learning algorithms select the most informative examples from a pool of unlabeled data, which can then be labeled by domain experts. By actively selecting the most valuable data points to annotate, the model can be trained more effectively and efficiently with limited resources.
Additionally, regularization techniques can help combat overfitting and improve generalization on limited data. Techniques such as L1 and L2 regularization, dropout, and early stopping can prevent the model from memorizing the limited training examples and encourage it to focus on learning more generalizable patterns.
Ensemble methods can also be beneficial when working with limited data. Ensemble methods combine the predictions of multiple models trained on different subsets of the limited data, thereby reducing the risk of overfitting and improving overall performance.
Finally, it’s essential to make the most out of the available limited data by carefully designing the training and testing datasets. Techniques such as cross-validation and stratified sampling can help provide a robust evaluation of model performance with limited data.
While handling limited data poses challenges, the combination of these techniques can help alleviate the impact of data scarcity and improve model performance. It’s crucial to explore and experiment with different strategies to find the most effective solution for a specific scenario.
The Role of Data Augmentation in Machine Learning
Data augmentation is a powerful technique in machine learning that helps address the challenge of limited training data. It involves applying various transformations or modifications to the existing data to create new, synthetic data points. Data augmentation plays a vital role in improving model performance and generalization in several ways.
One primary benefit of data augmentation is the ability to increase the quantity of training data. By generating new examples, the model has access to a larger and more diverse set of training instances. This helps in preventing overfitting and improves the model’s ability to generalize to unseen data.
Data augmentation also adds robustness to the model by exposing it to a wide range of variations and perspectives. By applying transformations such as rotation, scaling, flipping, or adding noise, the model becomes more resilient to changes in input data. It learns to recognize and extract meaningful features regardless of the orientation, size, or noise level in the data.
Furthermore, data augmentation can help address class imbalance issues in the dataset. In scenarios where certain classes have fewer samples than others, augmentation techniques can be used to create artificial examples of the underrepresented classes. This balances the distribution of the data and ensures that the model does not favor the majority classes over the minority classes.
Data augmentation is particularly effective when working with image and text data. For image data, techniques such as random cropping, rotation, and flipping can create new images that simulate different viewpoints or conditions. Similarly, for text data, techniques such as word replacement, shuffling, or adding synonyms can generate new variations of textual data.
It’s important to note that data augmentation should be applied judiciously and in a way that preserves the original meaning and integrity of the data. The generated synthetic data should still be representative of the original data distribution and adhere to the problem requirements.
Overall, data augmentation serves as a valuable tool for increasing data quantity, improving model robustness, addressing class imbalance, and enhancing generalization in machine learning. By expanding the available training data through synthetic examples, data augmentation empowers models to learn more effectively and perform better on real-world scenarios.
Strategies for Collecting and Preparing Sufficient Data
Collecting and preparing sufficient data is key to training successful machine learning models. Here are some strategies to consider when acquiring and preparing a dataset:
Define Clear Objectives: Start by clearly defining the objectives and requirements of your machine learning project. This will help guide the data collection process, ensuring that you collect the most relevant and useful data.
Data Sources: Identify potential sources of data that are relevant to your problem domain. These can include publicly available datasets, data from APIs, or data collected from your own sources such as surveys, experiments, or user interactions.
Data Quality: Ensure that the collected data is of high quality. This can involve removing duplicate entries, correcting errors, handling missing values, and addressing inconsistencies. Quality data is essential for training accurate and reliable machine learning models.
Data Annotation: If your problem requires labeled data, consider the most efficient way to annotate your dataset. This may involve hiring human annotators, utilizing crowd-sourcing platforms, or leveraging pre-existing labeled datasets.
Data Representation: Decide on the appropriate representation format for your data. This could involve transforming raw data into structured formats like CSV, JSON, or XML, or encoding textual data into tokenized or vectorized representations suitable for machine learning algorithms.
Data Preprocessing: Preprocess your data to make it suitable for model training. This may involve removing irrelevant features, normalizing or scaling numerical features, handling categorical variables, or performing dimensionality reduction techniques.
Data Split: Split your data into separate sets for training, validation, and testing. The size and distribution of each set depend on the specifics of your project. Cross-validation techniques can also be applied to assess model performance more robustly.
Data Privacy and Ethics: Consider the legal and ethical aspects of using the data. Ensure that you have obtained the necessary permissions and comply with data privacy regulations. Anonymize or de-identify personal information to protect the privacy of individuals.
Data Updates: Regularly update your dataset to account for changes in the problem domain over time. This ensures that the model remains accurate and relevant as new data becomes available.
Data Versioning: Establish a system for versioning your dataset to track changes and maintain reproducibility. This involves capturing relevant metadata and documenting any preprocessing steps applied to the data.
By following these strategies, you can collect and prepare a sufficient dataset that aligns with the objectives of your machine learning project. Remember to continuously evaluate and iterate on your data collection and preparation processes to ensure high-quality and up-to-date data for training and testing your models.
Evaluating and Monitoring Data Quality
Evaluating and monitoring data quality is a critical step in the machine learning process. It ensures that the data used for training and testing models is reliable, accurate, and representative of the problem at hand. Here are some key considerations for evaluating and monitoring data quality:
Data Accuracy: Assess the accuracy of the data by checking for errors, inconsistencies, or outliers. This can involve manual inspection, statistical analysis, or validation against ground truth information when available.
Data Completeness: Determine if the dataset is complete and contains all the necessary information for the problem domain. Check for missing values or fields, and consider imputation techniques if data is missing. In some cases, incomplete data may require additional data collection efforts.
Data Consistency: Ensure that the data is consistent both within the dataset and compared to external sources if applicable. Look for discrepancies in values, formats, or units that could impact model performance. Data with inconsistent labeling or conflicting information should be resolved before training the models.
Data Bias: Evaluate the dataset for bias, particularly in scenarios involving sensitive attributes like race, gender, or age. Bias can lead to unfair or discriminatory model outcomes. Perform an analysis to detect and mitigate biases, such as examining the distribution of attributes and ensuring representation from diverse populations.
Data Currency: Consider the currency or recency of the data. For some problems, historical data may not be useful, and frequent updates or real-time data may be required. Regularly assess the need for data updates to maintain the relevance and accuracy of the models.
Data Sampling: Validate the representativeness of the data by assessing the sampling process. Ensure that the selected samples are unbiased and reflect the underlying population distribution. Stratified sampling or other techniques may be necessary to account for imbalances in the dataset.
Data Validation: Implement validation measures to identify and handle potential errors or anomalies during the data collection and preprocessing stages. This can involve using checksums, cross-validation techniques, or comparing against external sources to validate the integrity of the data.
Data Documentation: Keep detailed documentation of the data, including data sources, preprocessing steps, and any data transformations applied. This documentation ensures reproducibility and helps others understand the data characteristics and potential limitations.
Continuous Monitoring: Establish a system for continuous monitoring of data quality. Regularly review and update the data quality metrics, perform periodic audits, and address any issues promptly to ensure the reliability and trustworthiness of the data used for machine learning.
By implementing a robust evaluation and monitoring process, you can ensure that the data utilized for machine learning is of high quality. This, in turn, improves the accuracy and effectiveness of the models and supports reliable and trustworthy decision-making based on the machine learning outputs.
The Benefits and Challenges of Big Data for Machine Learning
Big data has revolutionized the field of machine learning, offering numerous benefits and presenting unique challenges. Understanding both the advantages and obstacles associated with big data is crucial for unlocking its full potential in machine learning applications.
Benefits:
1. Improved Model Performance: Big data allows machine learning models to leverage a vast amount of training examples, resulting in improved accuracy and performance. With more data, models can capture diverse patterns, understand complex relationships, and make more accurate predictions.
2. Enhanced Generalization: Big data enables models to generalize better, as they are exposed to a wider variety of real-world scenarios. By training on diverse instances, models can learn to handle different data distributions and better adapt to unseen data during inference.
3. Uncovering Insights and Patterns: Big data provides an opportunity to discover hidden patterns and insights that may not be evident in smaller datasets. The increased volume and variety of data can reveal valuable information and facilitate data-driven decision-making.
4. Detecting Rare Events: Big data enables the identification of rare events or anomalies that may be significant but occur infrequently. These rare events may have unique patterns or characteristics that can be detected and analyzed using sophisticated machine learning techniques.
Challenges:
1. Data Acquisition and Storage: The sheer volume of big data requires efficient acquisition, storage, and management. This often involves implementing robust infrastructure, distributed storage systems, and specialized techniques for data ingestion and processing.
2. Data Quality and Noise: Big data can be prone to quality issues, including incomplete, inconsistent, or noisy data. It may require significant preprocessing efforts to clean and validate the data to ensure its reliability and integrity.
3. Scalability and Processing: Analyzing big data demands scalable algorithms and computational resources. Traditional machine learning techniques may struggle to handle the size and complexity of big data, requiring the use of distributed computing frameworks and parallel processing techniques.
4. Privacy and Ethical Concerns: Big data often involves sensitive personal or proprietary information, raising concerns related to privacy and ethical usage. Proper anonymization, data encryption, and compliance with privacy regulations are essential to address these concerns.
5. Bias and Representativeness: Large-scale datasets can inadvertently introduce biases due to imbalances in the data or underrepresentation of certain groups or populations. Careful data collection and preprocessing techniques are necessary to address these biases and ensure fairness in model predictions.
Considerations for Training and Testing Data Sets
When training and testing machine learning models, careful consideration must be given to the composition and management of the training and testing data sets. Several key factors play a significant role in ensuring accurate model performance and reliable evaluation:
Data Split: The data should be split into separate training and testing sets. The training set is used to train the model, while the testing set is used to evaluate its performance. The split should be representative of the underlying data distribution and include a sufficient amount of data in both sets.
Data Separation: The training and testing data should be completely separate, ensuring that there is no overlap between the two sets. This helps in assessing the model’s ability to generalize to unseen data and prevents the model from simply memorizing the training examples.
Data Quality: Both the training and testing sets should be of high quality. This involves ensuring that the data is clean, accurate, and representative of the problem domain. Preprocessing steps, such as removing outliers or handling missing values, should be applied consistently to both sets.
Data Distribution: The distribution of data in the training and testing sets should be similar. This ensures that the model is exposed to a representative sample of the data during training and is evaluated on data that resembles real-world scenarios.
Class Imbalance: Consider the presence of class imbalance in the data. If certain classes are underrepresented, techniques such as stratified sampling or oversampling can be employed to ensure a balanced representation in both the training and testing sets. This prevents model bias towards the majority class.
Temporal Considerations: For time-series data, it is important to consider the temporal aspect when splitting the data. The training set should contain data from earlier time periods, while the testing set should include data from later time periods to closely simulate real-world scenarios.
Validation Set: In addition to the training and testing sets, a validation set can be used for hyperparameter tuning and model selection. This separate set allows for iterative model evaluation and fine-tuning without the risk of overfitting on testing data.
Cross-Validation: Cross-validation techniques, such as k-fold or leave-one-out cross-validation, can be employed to obtain a more robust evaluation of the model’s performance. This helps to mitigate potential biases introduced by a single train-test split and provides a more reliable estimation of the model’s generalization ability.
Data Augmentation: Data augmentation techniques, as discussed earlier, can also be applied during the training phase to artificially increase the diversity and quantity of the training data. It is important to ensure that data augmentation is only applied to the training data and not to the testing or validation sets.
By carefully considering these factors, machine learning models can be trained and evaluated effectively. Proper management of the training and testing data sets, consideration of data quality and distribution, and the use of appropriate evaluation techniques contribute to reliable and precise model performance assessment.
Data Acquisition and Labeling Strategies
Data acquisition and labeling are essential steps in preparing data for machine learning. These processes involve gathering relevant data and assigning appropriate labels for supervised learning. Consider the following strategies for effective data acquisition and labeling:
Data Sources: Determine the potential sources of data that align with your problem domain, such as public datasets, APIs, or proprietary data. Depending on the problem at hand, consider the feasibility, reliability, and legality of acquiring data from various sources.
Data Collection: Design a systematic approach to collect data, considering factors such as sample size, data representativeness, and potential bias. Depending on the nature of the problem, data collection methods could include surveys, data scraping, sensor data acquisition, or manual data entry.
Data Sampling: Carefully select a representative sample of the data, considering factors like sample size, diversity, imbalances in class distribution, or stratification. Proper sampling techniques can ensure that the acquired data is a fair representation of the problem domain.
Data Labeling: If working with supervised learning, label the collected data by assigning relevant class labels or annotations. This can be a manual process done by human annotators, or it can involve automated techniques like rule-based labeling or active learning.
Annotator Guidelines: If using human annotators, provide clear and specific guidelines to ensure consistency in labeling. Clearly define label definitions, establish guidelines for ambiguous cases, and encourage communication and feedback between annotators to maintain label quality.
Annotation Review: Establish a review process to validate the quality and accuracy of the annotations. This involves checking for inter-annotator agreement, conducting periodic audits, and resolving any discrepancies or ambiguities in the labeled data.
Data Labeling Tools: Explore available tools and platforms that can assist in the data labeling process. These tools can streamline the annotation workflow, provide annotation interfaces, and enable collaboration and quality control among multiple annotators.
Active Learning: Implement active learning techniques to intelligently select instances for labeling. Active learning algorithms can prioritize uncertain or informative instances, reducing the labeling effort required while still achieving high model performance.
Quality Control: Implement mechanisms for ongoing quality control throughout the labeling process. This includes regular performance checks, reevaluation of labeled data, and establishing processes to address and rectify any potential labeling errors or biases.
Data Privacy and Ethics: Ensure compliance with data privacy regulations. Follow ethical guidelines and protect sensitive information during data acquisition and labeling. Anonymize or de-identify the data when necessary to preserve privacy.
By following these strategies, practitioners can effectively acquire and label data for machine learning projects. Proper data acquisition and labeling practices help ensure the availability of reliable, diverse, and accurately labeled datasets, which in turn contribute to the development of robust and effective machine learning models.
Overcoming Data Imbalance Issues in Machine Learning
Data imbalance is a common challenge in machine learning, where one or more classes in the dataset have significantly fewer instances than others. This imbalance can hinder the performance of machine learning models, leading to biased predictions or poor generalization. Addressing data imbalance is crucial for building reliable and accurate models. Here are some strategies to overcome data imbalance issues:
Data Resampling: Resampling techniques involve either oversampling the minority class or undersampling the majority class to balance the class distribution. Oversampling techniques replicate or generate synthetic examples of the minority class, while undersampling techniques reduce the number of examples from the majority class. These techniques help create a more balanced dataset for model training.
Class Weighting: Assigning class weights during model training can help address data imbalance. Class weights give higher importance to the minority class during model optimization, effectively balancing the impact of different classes. This ensures that the model doesn’t prioritize the majority class and improves performance on the minority class.
Ensemble Methods: Ensemble methods combine multiple models trained on different subsets of data to make predictions collectively. By training models on balanced subsets of data or utilizing different algorithms, ensemble methods can reduce the impact of data imbalance and improve overall model performance.
Anomaly Detection: If the imbalance is caused by a specific class representing rare or anomalous events, anomaly detection techniques can be employed. Instead of directly training a classification model, identifying and treating the rare class as an anomaly can lead to more effective detection and handling of such instances.
Cost-Sensitive Learning: Cost-sensitive learning is an approach that assigns different misclassification costs to different classes. By considering the relative importance of different classes, cost-sensitive learning focuses on minimizing the cost of misclassification for the minority class, even if it increases misclassification in the majority class.
Data Generation: If acquiring more data is challenging, data generation techniques can be employed to create synthetic examples of the minority class. This could involve using generative models or utilizing data augmentation methods to create realistic instances that resemble the minority class characteristics.
Domain Knowledge: Leveraging domain knowledge can help in designing effective strategies to handle data imbalance. Understanding the problem domain and the reasons behind the class imbalance can guide the selection of appropriate techniques for data preprocessing, feature engineering, and model optimization.
Evaluation Metrics: Consider using evaluation metrics that are robust to class imbalance, such as precision, recall, F1-score, and area under the precision-recall curve (AUPRC). These metrics provide a better assessment of model performance when dealing with imbalanced data than traditional accuracy.
Active Learning: Active learning techniques can be employed to reduce the labeling effort required for imbalanced datasets. By prioritizing the uncertain or difficult-to-classify instances from the minority class, active learning can guide the efficient labeling process and improve model performance.
By applying these strategies, machine learning practitioners can mitigate the challenges posed by data imbalance and build models that provide accurate and equitable predictions across all classes, regardless of their imbalance levels.
Data Scaling and Normalization Techniques for Machine Learning
Data scaling and normalization are crucial preprocessing steps in machine learning that ensure fair treatment of features and improve model performance. These techniques help bring the input features to a common scale and range, eliminating biases introduced by differing units, magnitudes, or distributions. Here are some common data scaling and normalization techniques:
Min-Max Scaling: Min-max scaling, also known as normalization, rescales the features to a specific range, typically between 0 and 1. The formula used is:
X’ = (X – Xmin) / (Xmax – Xmin)
This transformation ensures that all values are proportionally adjusted relative to the minimum and maximum values present in the feature.
Standardization: Standardization transforms the features to have a mean of 0 and a standard deviation of 1. It is achieved using the formula:
X’ = (X – mean(X)) / std(X)
Standardization is particularly useful when the data distribution is not necessarily Gaussian or when there are potential outliers present in the features.
Robust Scaling: Robust scaling is a technique that is less affected by outliers compared to standardization. It scales the features by subtracting the median and dividing by the interquartile range (IQR):
X’ = (X – median(X)) / IQR
This technique is suitable when the data contains outliers or is not normally distributed.
Log Transformation: Log transformation applies a logarithmic function to the feature values, which can help normalize skewed distributions. It is often used when data is heavily skewed or when the relationship between the feature and the target variable is exponential.
Scaling to Unit Norm: Scaling to unit norm, also known as vector normalization, scales the feature vectors to have a magnitude of 1. It is useful when the magnitude of the feature values matters more than the actual values themselves. Each feature vector is divided by its Euclidean norm to achieve this normalization.
Quantile Transformation: Quantile transformation maps the feature values to a specified target distribution, often Gaussian. It helps to mitigate the impact of outliers and non-normality, producing features with more comparable statistical properties.
These scaling and normalization techniques play a crucial role in ensuring fair treatment of features and improving the performance of machine learning models. The specific technique to use depends on the characteristics of the data, the nature of the problem, and the requirements of the machine learning algorithm being employed.
Addressing Missing Data in Machine Learning
Missing data is a common issue in machine learning, and it can adversely affect the performance of models if not handled properly. Dealing with missing data requires careful consideration and appropriate techniques to ensure accurate and reliable model training. Here are some strategies for addressing missing data in machine learning:
Identify Missing Data: Start by identifying and understanding the patterns of missing data in your dataset. Missing data can be categorized as Missing Completely at Random (MCAR), Missing at Random (MAR), or Missing Not at Random (MNAR). This categorization helps guide subsequent imputation strategies.
Deletion of Missing Data: One straightforward approach to handling missing data is to remove the instances or variables with missing values. However, this strategy is often only applicable when the missing data is minimal and does not significantly impact the representation or analysis of the dataset. It may lead to a loss of valuable information, especially if the missing data is not random.
Mean or Median Imputation: Mean or median imputation replaces the missing values with the mean or median, respectively, of the available values in the feature. This approach assumes that the missing values have a similar distribution to the observed values. While easy to implement, this method may distort the natural distribution of the feature and introduce bias.
Mode Imputation: Mode imputation is suitable for categorical or discrete features. It replaces the missing values with the most frequent category or value in the feature. This method works well when the missing values are associated with the dominant category or when the mode represents a reasonable estimate of the missing values.
Hot-Deck Imputation: Hot-deck imputation involves filling in missing values by randomly selecting a value from a similar or closely related observation. This technique ensures that the imputed value closely reflects the distribution of the observed values within the subgroup.
Model-Based Imputation: Model-based imputation uses machine learning models to estimate missing values. The missing values are predicted based on the other features in the dataset. Methods such as regression-based imputation, K-nearest neighbors imputation, or probabilistic methods can be employed to model and impute the missing values.
Multiple Imputations: Multiple imputations generate multiple plausible imputed datasets, each with its imputed values. This allows for variability in the imputations and captures the uncertainty associated with missing data. Multiple imputations are performed, and the results are combined during the model training phase.
Domain Expert Input: When dealing with complex or domain-specific datasets, consulting domain experts can provide valuable insights and assist in imputing missing values effectively. Their expertise can help make informed decisions on how to derive or estimate the missing values based on contextual knowledge.
It is important to approach missing data handling strategically, considering the potential impact on model performance and the assumptions made during imputation. Each technique has its strengths and limitations, and the choice depends on the nature of the data, the extent of missingness, and the specific requirements of the machine learning problem at hand.
The Importance of a Data Privacy and Security Strategy
In an increasingly data-driven world, implementing a robust data privacy and security strategy is crucial. As businesses and organizations collect and utilize large amounts of data for machine learning and other purposes, protecting the privacy and security of that data becomes paramount. The importance of a data privacy and security strategy can be understood through the following key points:
Protecting Sensitive Information: A data privacy and security strategy safeguards sensitive and personal information from unauthorized access, use, or disclosure. This includes personally identifiable information (PII) such as names, addresses, social security numbers, financial data, and more. Compliance with privacy regulations, such as the General Data Protection Regulation (GDPR) and the California Consumer Privacy Act (CCPA), is of utmost importance to ensure responsible data handling.
Building Trust: Demonstrating a commitment to data privacy and security builds trust among users, customers, and partners. It reassures them that their data is handled responsibly and protected from potential breaches or misuse. Trust is a valuable asset that fosters customer loyalty, strengthens relationships, and enhances brand reputation.
Mitigating Legal and Financial Risks: Failure to adequately protect data can result in legal and financial consequences. Organizations may face lawsuits, hefty fines, and reputational damage if data breaches occur or if they violate privacy regulations. Having a well-defined data privacy and security strategy minimizes these risks and demonstrates compliance with legal requirements.
Preserving Data Integrity: Data privacy and security measures not only protect data from unauthorized access but also ensure the integrity of the data. By employing encryption, access controls, and secure storage techniques, organizations can maintain the accuracy and reliability of the data, reducing the risk of data tampering or unauthorized modifications.
Supporting Ethical Data Use: A data privacy and security strategy promotes ethical data use, preventing unauthorized or unethical practices such as data trading, identity theft, or discriminatory profiling. It ensures that data is processed and utilized within legal and ethical boundaries, respecting the rights and privacy of individuals.
Enabling Data Sharing: A well-designed data privacy and security strategy can facilitate responsible data sharing and collaboration. Organizations can establish frameworks and protocols that allow secure sharing of data with trusted entities, fostering innovation, research, and partnerships while protecting the rights and privacy of individuals.
Adapting to Evolving Threats: Cybersecurity threats and data breaches are continuously evolving. A robust data privacy and security strategy includes proactive measures to detect and mitigate potential threats. Regular security assessments, employee training, and monitoring protocols ensure that organizations stay ahead of emerging risks.
Overall, a comprehensive data privacy and security strategy is essential for protecting sensitive information, building trust, mitigating legal and financial risks, preserving data integrity, supporting ethical data use, enabling data sharing, and adapting to evolving threats. By adopting and implementing such a strategy, organizations can responsibly manage and leverage data while maintaining the privacy and security of individuals’ information.