
What is a Database?
A database is an organized collection of data that is designed to be managed and accessed efficiently. It serves as a repository for information that can be stored, retrieved, and manipulated using computer systems. Businesses and individuals use databases to store a wide range of data types, such as customer information, product inventory, financial records, and much more.
At its core, a database consists of tables, which are structured with rows and columns. Each row represents a record or an instance of data, while each column represents a specific attribute or characteristic of that data. For example, in a customer database, each row may represent a customer, and the columns may include attributes like name, age, email address, and phone number.
Databases provide several advantages over traditional file-based systems. They offer better data organization, efficient data retrieval, data integrity through consistency rules, and support for complex queries and analysis. They also facilitate data sharing and collaboration among multiple users or applications.
There are different types of databases available, depending on the structure and organization of the data. The most commonly used types include relational databases, non-relational databases (also known as NoSQL databases), in-memory databases, distributed databases, and more. Each type has its own strengths and is suited for different use cases.
As technology continues to advance, databases play a vital role in storing and managing vast amounts of data. They have become the backbone of many applications and systems, powering essential functions in industries such as finance, healthcare, e-commerce, and more.
Types of Databases
Databases come in various types, each offering unique features and functionalities to cater to different data storage and management needs. Here are some of the most common types of databases:
- Relational Databases: Relational databases are based on the relational model and use tables with predefined relationships between them. They store data in a structured manner, and the relationships between tables are established using primary and foreign keys. Relational databases, such as MySQL, Oracle, and SQL Server, are widely used in businesses for their flexibility and ability to handle complex queries.
- Non-Relational Databases (NoSQL): NoSQL databases are designed to store and manage unstructured or semi-structured data and offer high scalability and performance. Unlike relational databases, NoSQL databases do not rely on predefined schemas and can handle large volumes of data. Examples of NoSQL databases include MongoDB, Cassandra, and Redis.
- In-Memory Databases: In-memory databases store data in primary memory (RAM) for faster access and retrieval. They are capable of handling real-time data processing and are commonly used in applications where speed is crucial, such as financial systems and real-time analytics. Redis and Memcached are popular in-memory database options.
- Distributed Databases: Distributed databases store data across multiple nodes or servers, enabling high availability and fault tolerance. They divide and replicate data across various locations, ensuring that if one node fails, the data remains accessible from other nodes. Examples of distributed databases include Apache Cassandra and Google Spanner.
- Data Warehouses and Data Lakes: Data warehouses and data lakes are used for storing and analyzing large volumes of data. Data warehouses are optimized for processing and querying structured data, while data lakes store raw, unprocessed data, including structured, semi-structured, and unstructured formats. They are commonly used in big data analytics and business intelligence applications.
These are just a few examples of the different types of databases available today. Each type has its own advantages and is suitable for specific use cases. Choosing the right type of database depends on factors such as data structure, scalability requirements, performance needs, and budget considerations.
Relational Databases
Relational databases are one of the most widely used types of databases in the industry. They are based on the relational model, which organizes data in the form of tables with predefined relationships between them.
In a relational database, data is structured into tables, where each table represents a specific entity or concept. Each row in a table, also known as a record, represents an instance of that entity, and each column represents a specific attribute or characteristic of the data.
The relationships between tables in a relational database are established using primary and foreign keys. A primary key is a unique identifier for each record in a table, while a foreign key is a reference to the primary key of another table. These relationships help maintain the integrity and consistency of the data.
Relational databases provide several advantages, including:
- Data Integrity: Relational databases enforce data integrity by applying rules and constraints to ensure that data is consistent and accurate. This helps maintain the quality and reliability of the stored information.
- Flexibility: Relational databases offer flexibility in querying and manipulating data. They support complex SQL (Structured Query Language) queries, allowing users to retrieve and analyze data in various ways.
- Scalability: Relational databases can handle large volumes of data and can scale vertically by upgrading hardware resources or horizontally through database replication and partitioning.
- Security: Relational databases provide robust security mechanisms, such as user authentication, access control, and encryption, to protect sensitive data from unauthorized access.
Some of the popular relational database management systems (RDBMS) include MySQL, Oracle Database, Microsoft SQL Server, and PostgreSQL.
Relational databases have been the go-to choice for many applications, especially those requiring complex data relationships or structured data. However, they may not be the optimal solution for every use case. In recent years, the rise of non-relational databases (NoSQL) has provided alternative options for handling unstructured or rapidly changing data.
Nonetheless, relational databases continue to play a crucial role in various industries, providing a solid foundation for data management and analysis.
Non-Relational Databases
Non-relational databases, also known as NoSQL databases, have gained popularity in recent years due to their ability to handle unstructured and semi-structured data efficiently. Unlike relational databases, which rely on predefined schemas and tables, NoSQL databases offer more flexibility and scalability.
NoSQL databases are designed to handle large volumes of data, including unstructured and semi-structured formats like JSON, XML, and key-value pairs. They provide faster data querying and processing capabilities, making them well-suited for use cases that require high scalability and performance.
Some key features of non-relational databases include:
- Flexible Schema: NoSQL databases do not enforce strict schemas, allowing for easy changes to the data structure without impacting existing data. This flexibility is particularly advantageous for applications dealing with rapidly changing data models.
- Horizontal Scalability: NoSQL databases are designed to scale horizontally, meaning they can handle large volumes of data by distributing it across multiple nodes or servers. This enables high availability, fault tolerance, and seamless scalability as data grows.
- High Performance: NoSQL databases prioritize performance by using distributed computing, caching mechanisms, and optimized data retrieval techniques. They can handle massive amounts of read and write operations concurrently, making them suitable for real-time applications.
- Document-Based Structure: Many NoSQL databases are document-based, storing data in the form of documents or collections of key-value pairs. This format allows for efficient retrieval and storage of complex and nested data structures.
- Graph-Based Relationships: Some NoSQL databases, like graph databases, are built specifically for handling complex relationships between data entities. They excel at managing and traversing interconnected data structures.
Examples of popular NoSQL databases include MongoDB, Cassandra, Redis, and Amazon DynamoDB.
NoSQL databases are commonly used in various domains, including web applications, social networking platforms, IoT (Internet of Things) systems, and big data analytics. Their flexibility, scalability, and high-performance capabilities make them suitable for handling diverse and rapidly evolving data requirements.
However, it’s important to note that non-relational databases are not always a one-size-fits-all solution. The choice between a relational and non-relational database depends on factors such as the data structure, scalability needs, consistency requirements, and the specific use case at hand.
Common Database Management Systems
There are several popular Database Management Systems (DBMS) available in the market that offer a range of features and functionalities for managing and manipulating databases. Each DBMS has its own strengths and is suited for different use cases. Here are some of the most commonly used DBMS:
- MySQL: MySQL is an open-source relational database management system. It is known for its ease of use, scalability, and high performance. MySQL is widely used in various web applications and is favored by developers for its extensive community support.
- Oracle Database: Oracle Database is a powerful and highly scalable relational database management system. It offers advanced features such as high-availability, security, and robust transaction management. Oracle Database is commonly used in enterprise-level applications and large-scale systems that require stringent data integrity and reliability.
- Microsoft SQL Server: Microsoft SQL Server is a popular relational database management system developed by Microsoft. It provides a comprehensive set of tools and features for data management, business intelligence, and data analysis. SQL Server is widely used in Windows-based environments and integrates well with other Microsoft products.
- PostgreSQL: PostgreSQL is an open-source relational database management system known for its reliability, extensibility, and compliance with SQL standards. It offers advanced features like geospatial and JSON support, as well as support for various programming languages. PostgreSQL is a preferred choice for applications that require strong data consistency and transactional integrity.
- MongoDB: MongoDB is a popular NoSQL database management system that stores data in a JSON-like format called BSON (Binary JSON). It offers flexibility, scalability, and ease of use, and is favored for handling unstructured and fast-changing data. MongoDB is commonly used in modern web applications, content management systems, and real-time analytics.
These are just a few examples of widely used DBMS, but there are many other options available, depending on specific requirements and preferences. Other notable DBMS include SQLite, IBM DB2, SAP HANA, and Amazon Aurora.
Choosing the right DBMS depends on factors such as the nature of the data, scalability needs, performance requirements, budget, and integration capabilities with other systems. It’s essential to evaluate these factors carefully to select the most suitable DBMS for a specific application or project.
Structured Query Language (SQL)
Structured Query Language (SQL) is a standardized language used for managing and manipulating relational databases. It provides a set of commands and queries to interact with the database, enabling users to create, retrieve, update, and delete data.
SQL is a declarative language, meaning users specify what they want to achieve, and the database system determines the most efficient way to execute the request. It allows for seamless communication between applications and the database, providing a powerful means of data management.
Some key features and capabilities of SQL include:
- Data Definition Language (DDL): DDL commands in SQL are used to define the structure of the database objects, such as tables, views, and indexes. They allow users to create, modify, and delete database schemas, tables, and other objects.
- Data Manipulation Language (DML): DML commands are used to query and manipulate data within the database. Commands like SELECT, INSERT, UPDATE, and DELETE enable users to retrieve, add, modify, and remove data records based on specific conditions.
- Data Control Language (DCL): DCL commands in SQL are used to manage user access and permissions to the database. They control security aspects, such as granting or revoking privileges to users and defining roles and permissions.
- Transactions and Concurrency Control: SQL supports transactions, which ensure the integrity and consistency of data. Transactions allow a set of related database operations to be treated as a single logical unit, ensuring that all changes are either committed or rolled back. Concurrency control mechanisms prevent conflicts when multiple users access and modify the database simultaneously.
- Aggregation and Joins: SQL provides powerful aggregation functions, such as COUNT, SUM, AVG, and GROUP BY, to perform calculations and generate summary data. It also enables users to combine data from multiple tables using JOIN operations based on common data attributes.
SQL is supported by most relational database management systems, including MySQL, Oracle Database, Microsoft SQL Server, and PostgreSQL. Although there are some variations in SQL syntax and features among different DBMS, the core concepts and principles remain consistent.
SQL is a fundamental skill for database administrators, developers, and data analysts. Its versatility and wide adoption make it an essential tool for managing and manipulating data in relational databases.
CRUD Operations
CRUD operations refer to the basic actions that can be performed on data in a database. CRUD is an acronym that stands for Create, Read, Update, and Delete, which represent the fundamental functions necessary for managing data.
Let’s explore each of these operations:
- Create: The Create operation involves inserting new data records into a database. It typically requires specifying the table structure and providing values for the required fields. The INSERT statement is commonly used in SQL to perform the Create operation.
- Read: The Read operation is used to retrieve data from a database. It allows users to fetch specific data records or query for data that matches certain criteria. The SELECT statement in SQL is used to perform Read operations and retrieve data from one or more tables.
- Update: The Update operation is used to modify existing data records in a database. It allows users to change the values of specific fields within a record or update multiple records that meet certain conditions. The UPDATE statement in SQL is commonly used for performing Update operations.
- Delete: The Delete operation is used to remove data records from a database. It allows users to delete specific records based on certain criteria or delete all records from a table altogether. The DELETE statement in SQL is used to perform Delete operations.
CRUD operations play a crucial role in the persistence and integrity of data. They allow applications to create new data, retrieve existing data, update data when necessary, and delete data that is no longer needed.
These operations are not only limited to SQL-based databases but also applicable to other types of databases, such as NoSQL databases, which may use different terminology or syntax to perform similar functionality.
By understanding CRUD operations, developers and database administrators can effectively manage and manipulate data within a database, ensuring the accuracy and reliability of the stored information.
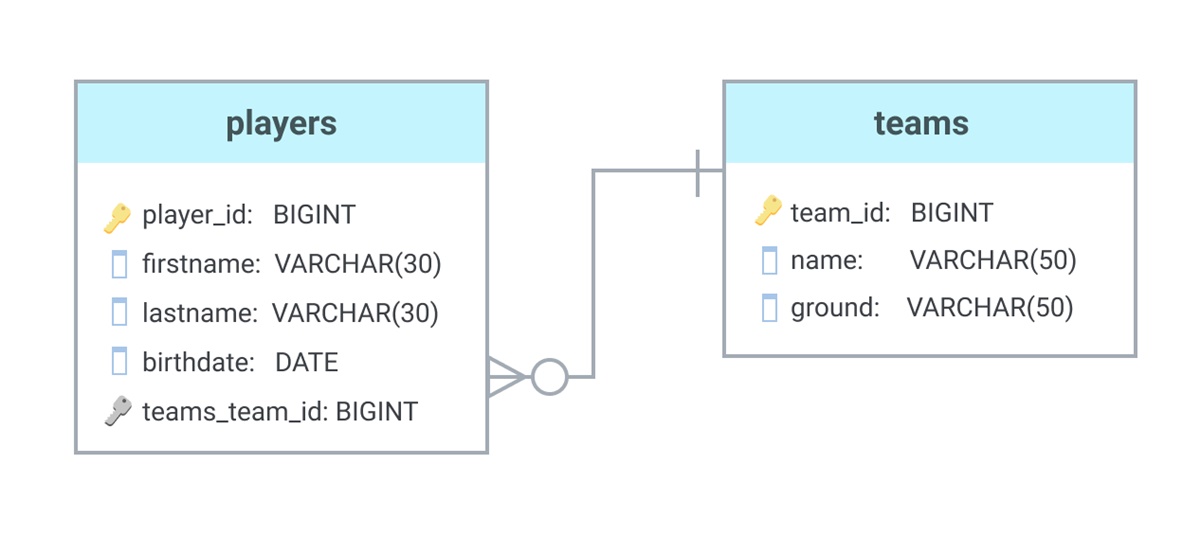
Primary Keys and Foreign Keys
In a relational database, primary keys and foreign keys are used to establish relationships between tables and maintain data integrity. They play an essential role in ensuring the accuracy and consistency of the data stored in the database.
A primary key is a unique identifier for each record in a table. It ensures that each row in the table can be uniquely identified and distinguished from others. The primary key can be a single column or a combination of columns, and it must have a unique value for every record in the table.
The primary key serves several purposes:
- Uniqueness: It ensures that each record in the table is uniquely identifiable through the primary key value.
- Indexing: The primary key is often indexed, which allows for faster data retrieval and improves query performance.
- Data Integrity: The primary key constraint prevents the insertion of duplicate or null values into the table.
- Referential Integrity: The primary key is referenced by foreign keys in other tables to establish relationships between them.
A foreign key is a column or a set of columns in a table that references the primary key of another table. It establishes a logical link or relationship between two tables, allowing for data consistency across the database. The foreign key constraint ensures that the values in the foreign key column(s) match the values in the referenced primary key column(s) of the related table.
The foreign key relationship provides the following benefits:
- Referential Integrity: The foreign key constraint ensures that data remains consistent by enforcing referential integrity. It prevents the creation of orphaned, or invalid, records that reference non-existent primary key values.
- Data Integrity: Foreign keys help maintain data integrity by ensuring that the data in the related tables remains accurate and consistent.
- Data Retrieval: The foreign key relationship allows for joining related tables based on the primary and foreign key columns, enabling the retrieval of data from multiple tables using a single query.
- Data Modifications: When performing data modifications, such as updates or deletes, foreign keys help in cascading the changes to the related tables. This ensures the integrity of the entire data set.
Properly defining and utilizing primary keys and foreign keys is crucial for database design and maintenance. They provide the structural foundation for establishing relationships between tables and managing data integrity, ultimately enhancing the overall quality and reliability of the database.
Indexing and Query Optimization
Indexing and query optimization play a critical role in improving the performance and efficiency of database queries. They help speed up data retrieval and minimize the resources required for query processing.
Indexing is a technique used to create a separate data structure that allows for faster data retrieval based on specific columns or attributes. An index contains a sorted list of values along with pointers to the actual data rows, enabling the database system to quickly locate and retrieve the desired data records.
Benefits of indexing include:
- Improved Query Performance: Indexes allow the database system to efficiently locate the required data, reducing the time and resources needed to perform queries. They can significantly speed up data retrieval, especially when working with large datasets.
- Efficient Data Filtering: Indexes enable the database system to quickly filter and narrow down the dataset based on the specified search conditions, resulting in faster query execution.
- Enhanced Data Integrity: Indexes can enforce uniqueness and integrity constraints on the indexed columns, preventing the insertion of duplicate or invalid data.
However, it’s important to note that indexing also has some trade-offs. Indexes consume disk space and require additional maintenance overhead when inserting, updating, or deleting data. Therefore, it’s vital to strike a balance between the number and type of indexes created and the overall performance goals of the database system.
Query optimization is the process of improving the efficiency and performance of queries executed on the database. It involves various techniques, such as query rewriting, query plan optimization, and cache utilization, to minimize resource usage and maximize query execution speed.
Query optimization aims to:
- Reduce Response Time: Optimization techniques ensure that queries are executed in the most efficient manner, resulting in faster response times and improved user experience.
- Minimize Resource Utilization: By optimizing query execution plans, unnecessary disk I/O and CPU usage can be minimized, leading to better resource utilization and system scalability.
- Improve Concurrency: Query optimization techniques can help maximize concurrent access to the database, enabling multiple users or applications to execute queries simultaneously without performance degradation.
DBMSs employ various optimization techniques, such as cost-based optimization, query plan caching, and parallel processing, to provide efficient query execution. These techniques analyze the query structure, statistics, and available indexes to determine the most optimal execution plan for a given query.
By leveraging indexing and query optimization techniques, database administrators and developers can significantly enhance the performance and efficiency of database operations, resulting in faster query execution and improved overall system performance.
Normalization and Denormalization
Normalization and denormalization are techniques used in database design to optimize data storage and minimize redundancy. They help ensure data consistency, improve data integrity, and enhance overall database performance.
Normalization is the process of organizing data in a database to eliminate redundant and duplicated information. It involves breaking down a large table into smaller, more manageable tables while establishing relationships between them.
Normalization follows a set of rules, known as normalization forms, which include:
- First Normal Form (1NF): Ensures that each column in a table contains atomic values and has a unique name. It eliminates repeating groups and fixes data redundancy.
- Second Normal Form (2NF): Builds upon 1NF and requires that each non-key column in a table is dependent on the entire primary key. It eliminates partial dependencies.
- Third Normal Form (3NF): Extends 2NF and ensures that there are no transitive dependencies between non-key columns. It eliminates redundant data by breaking tables down into smaller, more specialized units.
- Higher Normal Forms (BCNF, 4NF, 5NF, etc.): These normal forms address more complex scenarios and dependencies to achieve further levels of data normalization.
The benefits of normalization include:
- Data Consistency: Normalization helps maintain data consistency by reducing duplication and ensuring that each piece of information is stored in only one place.
- Data Integrity: It improves data integrity by reducing the risk of anomalies, such as insert, update, and delete inconsistencies within the database.
- Flexibility and Scalability: Normalized data structures allow for easier data maintenance, modifications, and scalability as the business requirements evolve.
Denormalization, on the other hand, is the process of intentionally introducing some level of redundancy into a database design. It involves combining related tables and duplicating data to optimize query performance and improve overall system efficiency.
Denormalization offers several advantages:
- Improved Query Performance: By reducing the number of joins required in a query, denormalization can speed up data retrieval, especially in scenarios where complex joins would be resource-intensive.
- Reduced Data Duplication: Carefully denormalizing certain parts of a database can minimize the need for excessive table joins, eliminating redundant data access and simplifying the data model.
- Caching and Aggregation: Denormalization can facilitate the caching of frequently accessed data and simplification of complex calculations or aggregations, leading to faster query execution.
However, denormalization comes with some trade-offs. It increases the redundancy of data and requires careful planning and maintenance to ensure data integrity and consistency.
The decision to normalize or denormalize a database depends on factors such as the specific use case, performance requirements, query patterns, and data access patterns. Striking the right balance between normalization and denormalization is crucial to achieving an efficient and optimized database schema.
ACID Properties
In the context of database transactions, the ACID properties are a set of principles that ensure reliability, consistency, and durability of data. ACID stands for Atomicity, Consistency, Isolation, and Durability.
Atomicity: Atomicity ensures that a transaction is treated as a single, indivisible unit of work. It means that either all the operations within a transaction are successfully completed, or none of them are. If any part of the transaction fails, the database system rolls back all the changes made by the transaction, ensuring that the data remains in a valid and consistent state.
Consistency: Consistency guarantees that a transaction brings the database from one consistent state to another. It ensures that the data is compliant with all the defined rules, constraints, and relationships. If a transaction violates any integrity constraints, the database system prevents it from being committed, preserving the overall integrity and validity of the data.
Isolation: Isolation ensures that multiple transactions occur independently and do not interfere with each other. It ensures that each transaction sees a consistent snapshot of the data, regardless of the concurrency. Transactions are isolated from each other to prevent issues like data corruption, dirty reads, and non-repeatable reads. Isolation levels, such as Read Uncommitted, Read Committed, Repeatable Read, and Serializable, define levels of concurrency and consistency trade-offs.
Durability: Durability guarantees that once a transaction is committed and confirmed to the user, its changes are permanently saved and will survive any subsequent system failures or crashes. The database system ensures that the written data is stored reliably, typically by using transaction logs and write-ahead logging mechanisms. Even in the event of power loss or hardware failures, the data can be restored from the log and brought back to its previous state.
The ACID properties are crucial for ensuring data reliability, integrity, and durability in database systems. They provide a foundation for maintaining data consistency and recoverability, particularly in mission-critical applications or scenarios where even a small inconsistency can have serious consequences.
While the ACID properties are fundamental to traditional relational databases, there may be certain scenarios where relaxing some of these properties can offer performance benefits. In such cases, NoSQL databases and other alternative data storage mechanisms may opt for eventual consistency models, sacrificing strict ACID guarantees in favor of scalability and availability.
NoSQL Databases
NoSQL databases, also known as “not only SQL,” are a family of database management systems that provide flexible data models and horizontal scalability. NoSQL databases deviate from traditional relational databases by not relying on rigid schemas or structured query language (SQL).
NoSQL databases are designed to handle large volumes of unstructured, semi-structured, and rapidly changing data. They excel in scenarios with high scalability requirements, real-time data processing, and the need to handle massive data sets. NoSQL databases offer several key characteristics:
- Flexible Data Models: NoSQL databases allow for the storage of unstructured and semi-structured data, such as JSON documents, key-value pairs, wide-column stores, or graphs. They provide the ability to manage diverse data types within a single database system.
- Horizontal Scalability: NoSQL databases are built to scale horizontally by distributing data across multiple servers or nodes. This enables seamless expansion of storage and processing capabilities as data volume or user load increases.
- High Performance: NoSQL databases employ optimized data structures and indexing techniques, resulting in fast read and write operations. They are suitable for handling high-speed data ingestion and real-time analytics.
- Flexible Data Access Patterns: NoSQL databases offer different access patterns, such as key-value retrieval, graph traversal, or document querying, to cater to diverse application requirements. They allow for efficient access to specific data elements without traversing the entire dataset.
There are several categories of NoSQL databases:
- Document databases: Store and manage unstructured data as documents, typically in BSON (Binary JSON) or XML formats.
- Key-value stores: Store data as a collection of key-value pairs, optimized for fast retrieval using unique keys.
- Columnar databases: Organize data in columns rather than rows, enabling efficient handling of analytical workloads and aggregation.
- Graph databases: Designed to represent and store interconnected data entities (nodes) and their relationships (edges), making them ideal for applications like social networks and recommendation engines.
Popular NoSQL databases include MongoDB, Cassandra, Redis, and Neo4j. These databases are embraced by developers for their flexibility, scalability, and ability to handle diverse data types and high-speed data processing requirements.
NoSQL databases are particularly useful in scenarios such as real-time analytics, content management systems, IoT data processing, and applications dealing with high-velocity data streams. They provide organizations with the flexibility to handle evolving data requirements and the ability to scale horizontally to meet growing demands.
CAP Theorem
The CAP theorem, also known as Brewer’s theorem, is a fundamental principle in computer science that describes the trade-offs in distributed data systems. It states that in a distributed system, it is impossible to simultaneously guarantee all three of the following properties: Consistency, Availability, and Partition tolerance.
Consistency refers to the requirement that all nodes in a distributed system have the same data at the same time. In other words, when a write operation is performed, all subsequent read operations must return the updated data. Consistency ensures that data remains in a valid and correct state throughout the system.
Availability refers to the guarantee that every valid request to the system receives a response, regardless of the current state of the system or the failure of individual nodes. Availability ensures that the system is continuously accessible and able to serve requests, even in the presence of failures or network partitions.
Partition tolerance refers to the system’s ability to continue functioning even when network partitions or communication failures occur, which may cause nodes in the distributed system to be unable to communicate with each other. Partition tolerance ensures that the system remains operational and functional even in the face of network failures or partitions.
The CAP theorem asserts that in a distributed system, when faced with a network partition, one must choose between maintaining consistency (C) or availability (A). It is impossible to have both guarantees simultaneously. However, the system must always be designed to tolerate network partitions (P).
This theorem has significant implications for distributed database systems. Different types of databases prioritize different properties based on the specific requirements of the application or use case:
- CP Systems: Consistency and Partition tolerance are prioritized over Availability. These systems maintain data consistency across all nodes, even during network partitions, but may experience temporary unavailability in case of failures.
- AP Systems: Availability and Partition tolerance are prioritized over Consistency. These systems prioritize continuous availability and responsiveness, potentially sacrificing strong consistency during network partitions. They allow for eventual consistency, where data may temporarily diverge but eventually converge across nodes.
- CA Systems: Some systems choose to forgo partition tolerance and prioritize both Consistency and Availability. These systems prioritize data integrity and guarantee consistency and availability within a single node or data center but may not handle network partitions well.
Understanding the CAP theorem is essential for designing and architecting distributed systems, as it provides insights into the trade-offs that need to be made when building highly scalable and fault-tolerant data systems.
In-Memory Databases
In-memory databases, as the name suggests, are databases that primarily rely on main memory (RAM) for data storage and retrieval instead of traditional disk-based storage. By keeping data in memory, these databases provide significant performance improvements and enable faster access to data compared to disk-based databases.
In-memory databases offer several advantages:
- Speed and Low Latency: In-memory databases eliminate disk I/O bottlenecks, resulting in faster data retrieval and transaction processing. The data is readily available in memory, allowing for low latency and high throughput, which is especially vital for real-time applications and high-speed data processing.
- Enhanced Scalability: In-memory databases can deliver exceptional scalability by leveraging the speed of memory and parallel processing capabilities. They can handle large volumes of data and provide faster response times, even with increasing data loads.
- Improved Analytical Processing: In-memory databases are well-suited for analytical workloads that require complex queries and aggregations. Their high-speed data processing capabilities make them ideal for real-time analytics and decision-making.
- Optimized Transaction Processing: In-memory databases offer high-performance transaction processing, as writes and updates can be performed directly in memory without the need for disk access. This makes them suitable for applications that require rapid transaction processing and high concurrency.
- Reduced Hardware Costs: In-memory databases reduce the need for expensive hardware components like high-speed disks, resulting in cost savings. They allow businesses to achieve higher performance with existing hardware infrastructure.
In-memory databases are commonly used in various domains, including financial systems, e-commerce platforms, real-time analytics, and gaming applications. Some popular in-memory databases include Redis, Memcached, and Apache Ignite.
However, it’s important to note that in-memory databases may have limitations concerning data durability and capacity. Since data resides in volatile memory, there is a risk of data loss in the event of a system failure or power outage. To mitigate this, in-memory databases often provide mechanisms like data replication and persistence to disk to ensure data durability.
Organizations choosing an in-memory database need to carefully consider factors such as data requirements, performance needs, durability strategies, and trade-offs between memory costs and capacity. Properly designed and implemented, in-memory databases can deliver substantial performance benefits, enabling businesses to process and analyze data in real-time to gain a competitive edge.
Distributed Databases
Distributed databases are a type of database system in which data is spread across multiple nodes or servers in a network. This decentralized approach allows for improved scalability, fault tolerance, and performance compared to centralized database systems.
In a distributed database, data is partitioned and distributed across multiple nodes. Each node typically stores a portion of the data, and coordination mechanisms are in place to ensure data consistency and efficient data access. Distributed databases offer several advantages:
- Scalability: Distributed databases can handle large volumes of data by distributing it across multiple nodes. As data size or user load increases, more nodes can be added to the cluster, ensuring high scalability and improved performance.
- Fault Tolerance: With data replicated across multiple nodes, distributed databases provide fault tolerance. If one node fails, data remains accessible from other nodes, ensuring uninterrupted availability and data integrity.
- High Availability: Distributed databases can provide high availability by replicating data across geographically diverse locations. This allows for continuous access to data even in the event of regional failures or network disruptions.
- Improved Performance: Distributed databases can leverage parallel processing and distributed query execution to achieve faster query response times. Data can be processed in parallel across multiple nodes, leading to improved throughput and reduced latency.
- Data Locality: Distributed databases can store data closer to where it is being used, reducing network latency and optimizing data access. This is particularly beneficial in applications with high read and write demands.
There are different approaches to building distributed databases, including:
- Shared-Nothing Architecture: In this architecture, each node operates independently and has its own resources. Nodes communicate by passing messages, and data is divided and distributed across the nodes.
- Shared-Disk Architecture: Shared-disk databases have a central storage unit that is accessible by all nodes. Data is distributed across nodes, but they share a common disk for data storage and retrieval.
- Shared-Memory Architecture: Shared-memory databases have a centralized memory that is shared by all nodes. Data is replicated across nodes, and they can directly access the shared memory for data operations.
Well-known distributed database systems include Apache Cassandra, Apache HBase, Google Spanner, and CockroachDB. These databases provide robust distributed features and support features like data partitioning, replication, and data consistency mechanisms.
Designing and managing distributed databases requires careful consideration of factors such as data partitioning strategies, data consistency models, communication protocols, and system performance trade-offs. When architected correctly, distributed databases can offer significant scalability, fault tolerance, and performance advantages, enabling organizations to handle large-scale, high-throughput applications efficiently.
Data Warehouses and Data Lakes
Data warehouses and data lakes are two different approaches to storing and managing large volumes of data, each serving distinct purposes and handling different data types and analysis requirements.
Data warehouses are designed to support business intelligence (BI) and decision-making processes. They are structured relational databases that store structured and well-defined data from multiple sources. The data is transformed, integrated, and organized into a unified schema, optimized for efficient querying and analysis.
Data warehouses offer several key features:
- Data Integration: Data from diverse sources, such as transactional databases, spreadsheets, or external systems, is extracted, transformed, and loaded into the data warehouse. This integration ensures consistency and supports a holistic view of the data.
- Schema-on-Write: Data warehouses enforce a predefined schema to ensure data quality and consistency. Before loading data into the warehouse, it is transformed and structured according to the schema.
- Aggregated and Summarized Data: Data warehouses store summarized, pre-aggregated, or pre-calculated data, allowing for faster query performance. This enables efficient analysis of trends, patterns, and business insights.
- Optimized Query Performance: Data warehouses use indexing, partitioning, and other optimization techniques to enable fast querying and reporting capabilities, making them suitable for complex analytical queries.
Data lakes, in contrast, are designed to store vast amounts of structured, semi-structured, and unstructured data in its raw form. Data lakes prioritize flexibility and agility, enabling users to store and analyze diverse data types without predefined schemas or transformations.
Data lakes offer several characteristics:
- Schema-on-Read: Data lakes allow for data ingestion and storage without imposing a predefined schema. The schema is applied at the time of data access, enabling the flexibility to explore and analyze different data structures without upfront data transformations.
- Data Exploration and Discovery: Data lakes provide a platform for data scientists and analysts to explore and experiment with various data types, structures, and formats. This flexibility encourages ad-hoc analysis and discovery of new insights.
- Scalability and Low Cost: Data lakes have flexible storage architectures and can scale horizontally to accommodate massive volumes of data. They harness the benefits of cloud storage, offering cost-effective options for storing and analyzing extensive datasets.
- Support for Big Data Technologies: Data lakes leverage big data technologies, like Hadoop and Apache Spark, to enable distributed processing and parallel data analysis. This makes them well-suited for handling high-velocity and high-variety data.
Data lakes and data warehouses are not mutually exclusive, and organizations often leverage both to achieve a comprehensive data strategy. Data transformations and aggregations may be performed in the data warehouse, while the raw, detailed data is stored in the data lake for further exploration and analysis.
Ultimately, the choice between data warehouses and data lakes depends on factors such as data requirements, query and analysis needs, flexibility, and cost considerations. Both approaches play vital roles in enabling data-driven insights and supporting decision-making processes in today’s data-driven world.
Database Security
Database security is crucial for protecting sensitive information, ensuring data integrity, and preventing unauthorized access or data breaches. It involves implementing a combination of physical, technical, and administrative controls to secure databases and protect valuable data assets.
Here are some key aspects of database security:
- Access Control: Implementing strict access controls is fundamental to database security. This includes user authentication, authorization, and role-based access control (RBAC). Limiting access to data based on user roles and assigning appropriate privileges helps prevent unauthorized access.
- Data Encryption: Encrypting sensitive data at rest and in transit provides an additional layer of protection. Encryption algorithms such as AES are used to scramble data, ensuring that it remains secure and confidential, even if it falls into the wrong hands.
- Auditing and Monitoring: Database auditing and logging mechanisms track activities and changes made to the database. Monitoring and analyzing logs can help detect unauthorized access attempts, suspicious activities, or potential security breaches.
- Backup and Recovery: Regularly backing up databases and storing backups securely offsite helps protect data in case of incidents like system failures, natural disasters, or cyberattacks. Ensuring reliable recovery mechanisms are in place allows for prompt restoration of data.
- Vulnerability Management: Regularly scanning and assessing databases for vulnerabilities is crucial. Applying security patches and updates promptly helps address identified vulnerabilities and strengthens the overall security posture of the database.
- Database Activity Monitoring (DAM): DAM solutions provide real-time monitoring of database activities, assisting in the detection of anomalous or suspicious behavior. DAM helps identify potential threats, data exfiltration attempts, or unauthorized activities.
It’s important to note that database security is not just limited to technical controls. Adequate security awareness and training programs for database administrators and users play a crucial role in preventing security incidents. Educating users about best practices for password management, social engineering attacks, and secure data handling is essential.
Compliance with standards and regulations specific to the industry, such as the General Data Protection Regulation (GDPR) or the Health Insurance Portability and Accountability Act (HIPAA), is also critical. Adhering to these regulations ensures the privacy and protection of sensitive data in line with legal requirements.
Implementing a comprehensive database security strategy requires a combination of preventive and detective controls, along with ongoing monitoring and proactive measures to protect against evolving threats. Regular security assessments, vulnerability management, and a strong security framework contribute to maintaining a robust and secure database environment.
Backup and Recovery
Backup and recovery are critical components of a comprehensive database management strategy. They involve creating copies of data and establishing processes to restore data in the event of data loss, system failures, or disasters. A well-designed backup and recovery plan ensures the availability and integrity of data, minimizes downtime, and aids in business continuity.
Backup: The backup process involves creating copies of the database’s data and storing it in a separate location. Regular backups are essential for safeguarding against data loss caused by hardware failures, software corruption, human errors, or cyberattacks. Key considerations for backups include:
- Frequency: The backup frequency should be determined based on the criticality of the data and the frequency of changes. Critical databases may require more frequent backups to minimize the risk of data loss.
- Incremental and Full Backups: Incremental backups capture only the changes made since the last backup, reducing backup time and storage requirements. Full backups, on the other hand, capture the complete dataset, providing a baseline for restoration.
- Offsite Storage: Backups should be stored in secure, offsite locations to protect against physical disasters or damage to the primary data center. Cloud storage or remote servers are commonly used for offsite backup storage.
- Data Validation: Regularly validating the backup data to ensure its integrity and reliability is crucial. Validation involves verifying the consistency, completeness, and recoverability of the backup data.
Recovery: Recovery is the process of restoring data from backups in the event of data loss or system failures. A robust recovery plan ensures the timely restoration of data and minimizes downtime. Key considerations for recovery include:
- Recovery Point Objective (RPO) and Recovery Time Objective (RTO): RPO defines the maximum acceptable data loss tolerance, while RTO specifies the maximum acceptable downtime. These objectives help establish the recovery strategy and determine the frequency and speed of backups and restoration processes.
- Point-in-Time Recovery: Point-in-time recovery allows restoration to a specific point in time before the data loss occurred. It enables rollback to a consistent state and is crucial in scenarios where data corruption or accidental changes have occurred.
- Backup Validation: Validating the integrity and reliability of backups before performing a recovery ensures that the backup data is usable and can be restored successfully.
- Testing and Documentation: Regularly conducting recovery tests and documenting the recovery process are essential. Testing ensures that the recovery plan and procedures are up-to-date, effective, and can be executed in a timely manner when required.
- Disaster Recovery Plans: In addition to routine backup and recovery processes, establishing disaster recovery plans that account for catastrophic events is critical to ensuring business continuity. These plans include redundancy measures, failover systems, and procedures for restoring data and services in the event of a disaster.
Regularly reviewing and updating the backup and recovery strategy based on changing business needs, data growth, and technological advancements is essential. Implementing a comprehensive backup and recovery plan minimizes the risk of data loss, provides assurance to stakeholders, and helps organizations maintain critical operations in the face of disruption.