
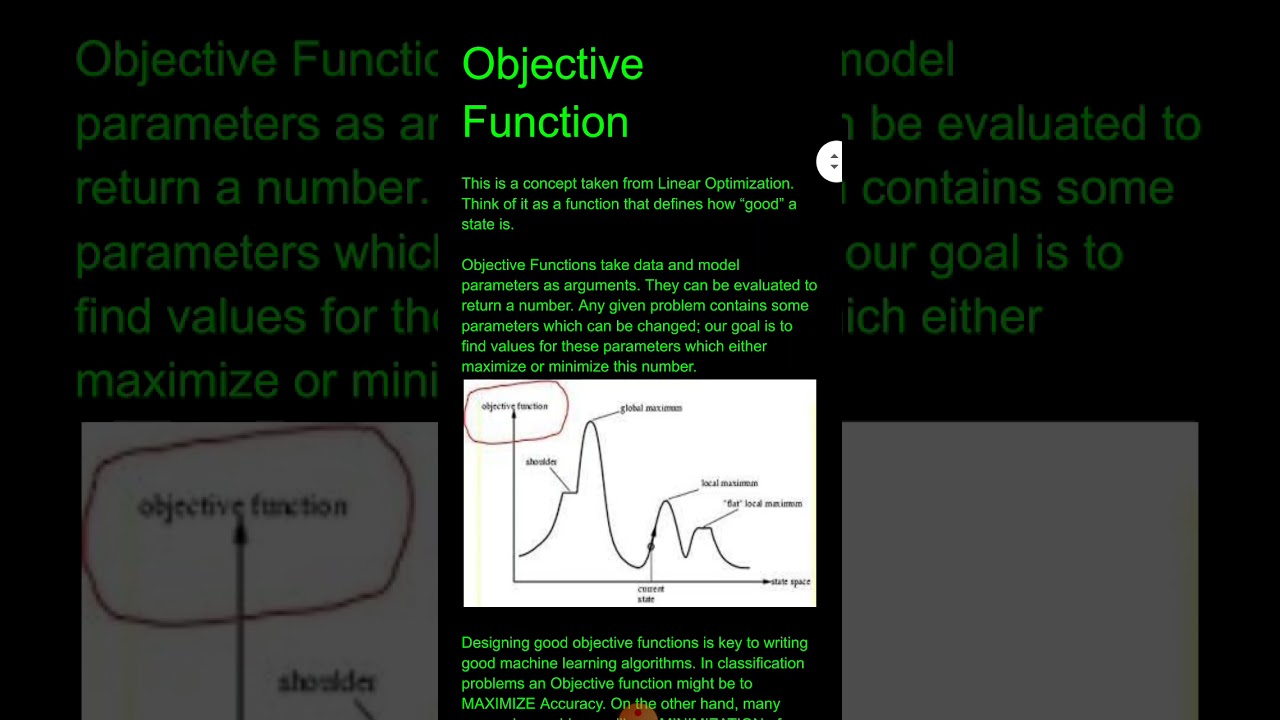
What Is Objective Function?
An objective function, also known as a loss function or cost function, plays a pivotal role in machine learning algorithms. It quantifies the disparity between predicted values and actual values, thereby guiding the learning process to optimize model performance.
Essentially, an objective function measures the quality of a model’s predictions by assigning a numerical value to the discrepancy between the predicted output and the true output. The goal is to minimize this discrepancy, indicating a closer alignment between the model’s predictions and the actual values.
The objective function encapsulates the ultimate goal of a machine learning algorithm, which could be to minimize error, maximize accuracy, or optimize a defined metric. It acts as a guide for the learning algorithm to find the best possible set of model parameters that will result in the desired outcome.
Machine learning models are built through an iterative process of training on a labeled dataset, where the objective function is used to evaluate and update the model’s parameters. By minimizing the value of the objective function, the model gradually learns patterns, relationships, and generalizations within the data, leading to improved performance.
A well-designed objective function should accurately capture the learning task’s objectives and provide a meaningful measure of model performance. It should be differentiable, allowing for gradient-based optimization algorithms, and should align with the specific goals and requirements of the problem at hand.
Moreover, the choice of objective function heavily influences the behavior and outcomes of the learning algorithm. Different objective functions emphasize different aspects of a model’s performance and cater to distinct learning objectives. Therefore, selecting the appropriate objective function is crucial to ensure the model’s effectiveness and relevance in solving the intended problem.
Importance of Objective Function in Machine Learning
The objective function holds significant importance in machine learning as it serves multiple crucial purposes throughout the learning process. Understanding its importance can help us appreciate its role in optimizing model performance and achieving desirable outcomes.
Firstly, the objective function guides the learning algorithm by providing a clear optimization goal. By quantifying the discrepancy between predicted and actual values, it enables the algorithm to iteratively update the model’s parameters in the direction that minimizes this discrepancy. In other words, the objective function acts as a compass, steering the learning algorithm towards the most optimal solution.
Secondly, the choice of the objective function determines the learning algorithm’s behavior and the model’s learning capabilities. Different objective functions prioritize different aspects of performance, such as error minimization, accuracy maximization, or regularization. For instance, an objective function that penalizes large model weights can help avoid overfitting, while a function that focuses on reducing errors can prioritize accurate predictions. Consequently, the objective function plays a critical role in defining the learning objectives and shaping the model’s behavior accordingly.
Furthermore, the objective function enables the evaluation and comparison of different models. By assessing the value of the objective function on a validation or test dataset, we can quantitatively measure the model’s performance. This allows us to compare different models or tune hyperparameters to select the model with the best performance for a given task. The objective function acts as a performance metric, providing a standardized way to assess and compare models based on their ability to achieve the desired outcome.
Additionally, the objective function is closely tied to the optimization algorithm used to train the model. Gradient-based optimization algorithms, such as stochastic gradient descent, rely on the gradients of the objective function to find the optimum model parameters. By computing the gradients and updating the parameters accordingly, these algorithms iteratively refine the model’s predictions. Therefore, the objective function is fundamental in driving the optimization process and ensuring that the learning algorithm converges towards an optimal solution.
Types of Objective Functions
There are various types of objective functions in machine learning, each serving a specific purpose and addressing different learning goals. The choice of objective function depends on the nature of the problem and the desired outcomes. Here, we will explore some commonly used types of objective functions:
- Mean Squared Error (MSE): This objective function measures the average squared difference between predicted and actual values. It is commonly used in regression problems, where the goal is to minimize the overall squared error and achieve the closest fit to the data.
- Mean Absolute Error (MAE): Similar to MSE, MAE computes the average absolute difference between predicted and actual values. It provides a measure of average prediction error and is less sensitive to outliers compared to MSE.
- Log Loss (Cross-Entropy Loss): This objective function is widely used in classification tasks. It measures the dissimilarity between predicted probabilities and true class labels. Log loss penalizes heavily for confident incorrect predictions and encourages the model to have high certainty in the correct class.
- Hinge Loss: Primarily used in support vector machines (SVMs) and binary classification problems, hinge loss aims to maximize the margin between the decision boundary and the training instances. It penalizes misclassifications but does not differentiate between confidently misclassified instances and marginally misclassified ones.
- Kullback-Leibler Divergence: This objective function is commonly used in tasks involving probabilistic models. It measures the dissimilarity between two probability distributions, such as the predicted distribution and the true distribution. Minimizing the Kullback-Leibler Divergence leads to aligning the predicted distribution as closely as possible to the true distribution.
These are just a few examples of objective functions, and there are many more depending on the specific task and learning objectives. It is important to choose the objective function that aligns with the problem at hand and the desired outcomes. Understanding the characteristics and implications of different objective functions allows for better decision-making in model development and optimization.
Choosing the Right Objective Function
Choosing the right objective function is a critical step in machine learning as it directly influences the learning process and the model’s performance. The objective function should align with the problem requirements and learning objectives to ensure optimal results. Here are some factors to consider when selecting the appropriate objective function:
- Problem Type: The nature of the problem, whether it is regression, classification, or something else, plays a significant role in determining the objective function. Regression problems often utilize mean squared error or mean absolute error, while classification problems commonly employ log loss or hinge loss.
- Metrics and Evaluation: Consider the evaluation metrics that are relevant to the problem and desired outcomes. The objective function should align with these metrics to ensure the model’s performance is optimized according to the evaluation criteria.
- Robustness to Outliers: Some objective functions, such as mean squared error, are more sensitive to outliers in the data. If the dataset contains outliers or extreme values, it may be beneficial to choose an objective function that is more resilient to such anomalies, like mean absolute error.
- Model Interpretability: Depending on the task and domain, model interpretability may be crucial. In such cases, it is advisable to choose an objective function that supports interpretable models, such as L1 regularization combined with MSE.
- Trade-offs: Consider any trade-offs that need to be made in the learning process. For example, if reducing false positives is more important than overall accuracy in a classification problem, an objective function that focuses on minimizing false positives, such as precision, should be chosen.
It is important to note that the choice of the objective function should be made thoughtfully and in alignment with the problem requirements and domain knowledge. Experimentation with different objective functions, along with proper evaluation, can help identify the most suitable one for the given problem. It is also worth considering the impact of the chosen objective function on the model’s behavior, convergence rate, and generalization capabilities.
By carefully selecting the right objective function, machine learning practitioners can ensure that the learning algorithm is aligned with the desired learning goals and the model is optimized for improved performance.
Loss Functions and Optimization Algorithms
Loss functions and optimization algorithms go hand in hand in the machine learning pipeline. The choice of the loss function affects the optimization algorithm’s behavior, and selecting an appropriate combination is crucial for effective model training and performance. Here is an overview of the relationship between loss functions and optimization algorithms:
Loss Functions: Loss functions quantify the difference between predicted and actual values. They provide a measure of the model’s performance and guide the optimization algorithm towards minimizing this difference. Different types of loss functions, such as mean squared error, mean absolute error, or log loss, are used depending on the problem type and learning objectives.
For regression tasks, loss functions like mean squared error or mean absolute error are commonly used. These loss functions penalize the difference between predicted and actual values, leading to models that provide the best possible fit to the data. In classification tasks, loss functions such as log loss play a crucial role in optimizing the model’s predicted probabilities and aligning them with the true class labels.
Optimization Algorithms: Optimization algorithms are responsible for adjusting the model’s parameters to minimize the chosen loss function. These algorithms iteratively update the model’s weights or coefficients to find the optimal values that result in the smallest loss.
Gradient-based optimization algorithms, like stochastic gradient descent (SGD) or Adam, are widely used in machine learning. They rely on calculating the gradients of the loss function with respect to model parameters and adjusting the parameters in the direction that leads to the steepest decrease in the loss. The learning rate, which determines the step size of the parameter updates, also plays a crucial role in the convergence and optimization process.
Combining the right loss function with an appropriate optimization algorithm is essential for successful model training. The loss function guides the algorithm towards the desired performance metric, while the optimization algorithm optimizes the model’s parameters based on the loss feedback.
It is worth noting that the choice of loss function and optimization algorithm can impact the convergence speed, model stability, and generalizability. Experimenting with different combinations and tuning hyperparameters can help find the best combination for a specific problem.
Overall, the selection of an appropriate loss function and optimization algorithm is a crucial step in developing accurate and reliable machine learning models.
Evaluating Model Performance Using Objective Functions
Objective functions not only guide the training process but also serve as valuable tools for evaluating model performance. By leveraging the values of the objective function, machine learning practitioners can assess the effectiveness and accuracy of their models. Here’s how objective functions are used to evaluate model performance:
Quantitative Assessment: Objective functions provide a quantitative metric to measure the model’s performance. By calculating the value of the objective function on a validation or test dataset, practitioners can obtain a numerical evaluation of how well the model is performing. Lower values of the objective function typically indicate better performance.
Benchmarking and Comparisons: Objective functions allow for fair comparisons and benchmarking between different models or variations of a model. By evaluating multiple models on the same objective function, practitioners can identify which model performs the best for a given task. This enables informed decision-making in selecting the most suitable model for deployment.
Tuning and Optimization: Objective functions are crucial during the model optimization process. Practitioners can leverage the value of the objective function to tune hyperparameters, such as learning rates or regularization strengths, to improve the model’s performance. By monitoring the changes in the objective function as these hyperparameters are adjusted, practitioners can ensure that the model is converging towards the optimal point.
Early Stopping: Objective functions can be used for early stopping, a technique that prevents overfitting and saves computational resources. By monitoring the value of the objective function on a validation dataset during training, practitioners can halt the training process when the performance starts to degrade or plateaus. This ensures that the model is not excessively fitted to the training data and has achieved a satisfactory level of generalization.
Subjective Assessments: While objective functions provide quantitative measures, it is essential to complement their evaluations with subjective assessments. The nature of some tasks, like image or text generation, often requires human judgment to evaluate the quality and appropriateness of the model’s outputs.
It is important for practitioners to select objective functions that align with the desired evaluation criteria and take into account any specific constraints or requirements of the task at hand. Additionally, it is beneficial to consider multiple evaluation metrics or objective functions to gain a comprehensive understanding of the model’s performance.
By leveraging objective functions for evaluation, practitioners can make informed decisions, optimize model performance, and ensure the reliability and effectiveness of their machine learning models.
Commonly Used Objective Functions in Machine Learning
Objective functions, also referred to as loss functions or cost functions, play a crucial role in machine learning to quantify the discrepancy between predicted values and actual values. There are several commonly used objective functions across different domains and tasks. Understanding these objective functions can provide insights into their applications and help guide the model development process. Here are some commonly used objective functions:
- Mean Squared Error (MSE): MSE is frequently used for regression tasks. It measures the average squared difference between predicted values and actual values. By minimizing this objective function, the model aims to achieve the best fit to the data and minimize the overall squared error.
- Mean Absolute Error (MAE): Another popular objective function for regression problems is MAE, which measures the average absolute difference between predicted values and actual values. MAE provides a measure of average prediction error and is less sensitive to outliers compared to MSE.
- Binary Cross-Entropy: Binary cross-entropy is commonly employed in binary classification problems. It compares the predicted probabilities of the positive class with the true labels. This objective function encourages the model to have high-certainty predictions for the correct class and penalizes confident incorrect predictions.
- Categorical Cross-Entropy: Categorical cross-entropy is used for multi-class classification problems. It measures the dissimilarity between predicted probabilities and true class labels across multiple classes. The model is trained to minimize the cross-entropy loss by aligning the predicted probabilities with the true class distributions.
- Hinge Loss: Hinge loss is commonly utilized in support vector machines (SVMs) and binary classification tasks. It aims to maximize the margin between the decision boundary and the training instances. Hinge loss penalizes misclassifications, but it does not differentiate between confident or marginally misclassified instances.
- Kullback-Leibler Divergence: Kullback-Leibler Divergence is often used in tasks involving probabilistic models. It quantifies the dissimilarity between two probability distributions, such as the predicted distribution and the true distribution. By minimizing this objective function, the model aligns its predicted distribution with the true distribution.
These objective functions represent a subset of the many objective functions available in machine learning. The choice of the objective function depends on the problem type, the nature of the data, and the desired learning goals. It is crucial to select the appropriate objective function that aligns with the problem requirements and evaluation metrics to ensure optimal performance of the machine learning model.
Challenges of Objective Function Optimization
Objective function optimization is a crucial component in training machine learning models, but it can present various challenges that require careful consideration and addressing. These challenges impact the efficiency and effectiveness of the optimization process. Here are some common challenges in objective function optimization:
Local Optima: Objective functions can have multiple local optima, which are points in the parameter space where the objective function has the lowest value locally. Optimization algorithms may get stuck in these local optima, resulting in suboptimal model performance. Addressing this challenge requires the use of more advanced optimization techniques, such as random restarts or metaheuristic algorithms.
Overfitting: Overfitting occurs when a model performs well on the training data but fails to generalize to unseen data. Objective function optimization may inadvertently lead to overfitting if not properly controlled. Techniques like regularization, early stopping, and cross-validation can help mitigate the risk of overfitting during optimization.
High-Dimensional Optimization: In high-dimensional spaces, objective function optimization becomes more challenging due to the large number of parameters to optimize. The curse of dimensionality can lead to slow convergence and an increased risk of getting trapped in local optima. Dimensionality reduction techniques and careful initialization of model parameters can help alleviate this challenge.
Noisy or Incomplete Data: Real-world datasets often contain noise, missing values, or outliers. These issues can distort the objective function optimization process, leading to inaccurate parameter estimates. Data preprocessing steps, such as outlier removal and imputation of missing values, can help improve the quality of the data and reduce the impact of noise during optimization.
Computational Complexity: Objective function optimization can be computationally intensive, especially for large datasets or complex models. The time required for optimization may become a bottleneck, limiting the scalability and efficiency of the model training process. Employing efficient optimization techniques, such as mini-batch gradient descent or parallelization, can help tackle this challenge.
Ill-Posed Problems: Certain machine learning tasks may suffer from ill-posedness, where the objective function lacks clarity or unique solutions. This can make optimization difficult and result in ambiguous model outputs. Careful problem formulation, regularization, or incorporating additional domain knowledge can help address this challenge.
Overcoming these challenges requires a combination of domain expertise, careful experimental design, and proper selection of optimization algorithms and techniques. Additionally, continuous monitoring and evaluation of the optimization process can help identify and address any issues that arise during model training.
By recognizing and addressing the challenges of objective function optimization, machine learning practitioners can enhance the quality and performance of their models and achieve better results in real-world applications.