
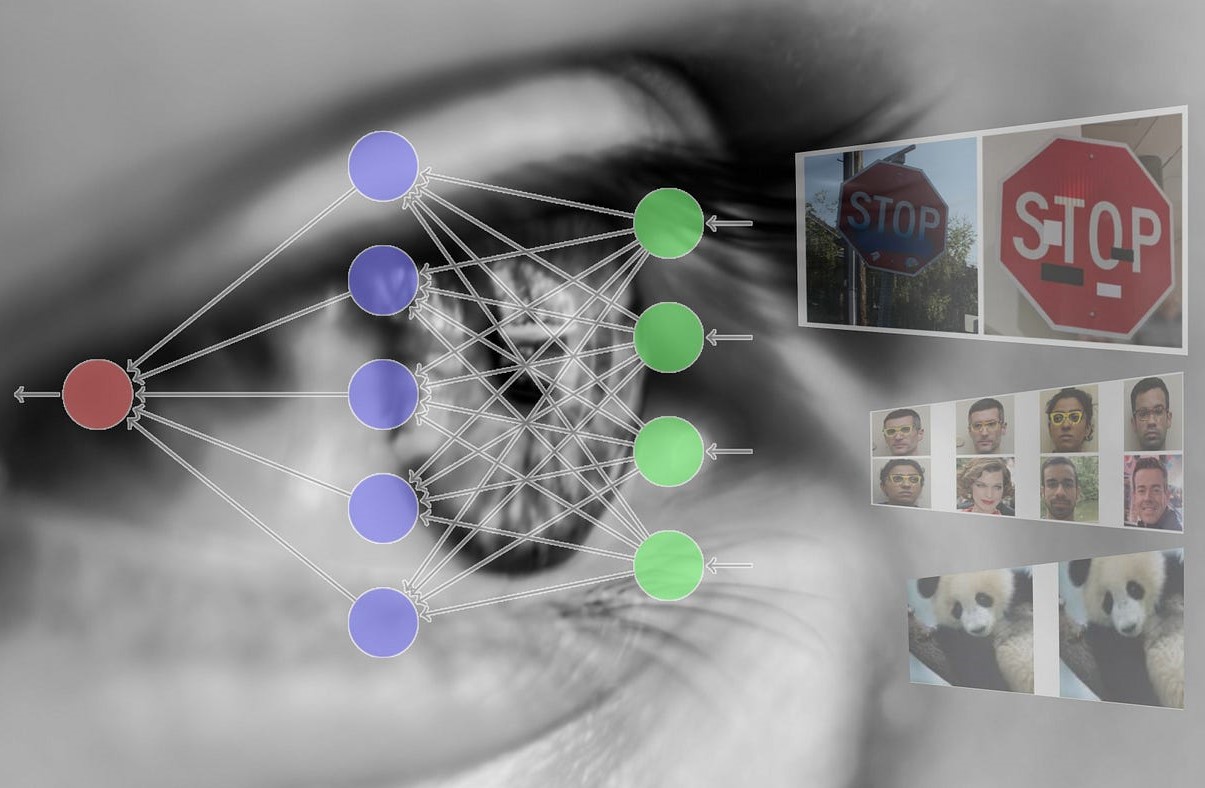
Types of Attacks in Machine Learning
Machine learning algorithms have become a crucial part of many real-world applications, from image recognition to natural language processing. However, as these algorithms continue to advance, so do the methods employed by attackers to exploit their vulnerabilities. Understanding the different types of attacks in machine learning is essential for building robust systems and ensuring the integrity and security of the data being processed.
1. Evasion Attacks: Also known as adversarial attacks, evasion attacks aim to manipulate input data to deceive the machine learning model into making incorrect predictions. Attackers modify the input by adding imperceptible perturbations that can cause misclassification or confusion in the model’s decision-making process.
2. Poisoning Attacks: Poisoning attacks involve injecting malicious data into the training set used to train the machine learning model. By poisoning the training data, attackers can introduce biases or manipulate the model’s behavior, leading to erroneous predictions or compromised performance.
3. Model Extraction Attacks: In a model extraction attack, the attacker aims to extract the details of a trained model by querying it with carefully crafted inputs. This allows the attacker to obtain a replica of the model, enabling further analysis or potentially finding vulnerabilities to exploit.
4. Membership Inference Attacks: Membership inference attacks attempt to determine if a specific data point was present in the training data used to train the model. By querying the model with carefully designed inputs, attackers can exploit the model’s responses to deduce whether a particular data instance was part of the training set.
5. Model Inversion Attacks: Model inversion attacks involve an attacker trying to reconstruct sensitive information from a trained machine learning model. By leveraging the outputs of the model, an attacker can infer private or confidential data that was used to train the model, such as personal identification numbers or medical records.
These are just a few examples of the types of attacks in machine learning. It is crucial for organizations and researchers to be aware of these threats and develop robust defenses to mitigate their impact. By understanding the potential vulnerabilities and attack vectors, machine learning systems can be better equipped to withstand adversarial attacks and ensure the security and integrity of the data they process.
What is an Adversarial Attack?
An adversarial attack refers to a deliberate and targeted manipulation of machine learning models by introducing specially crafted inputs, known as adversarial examples, with the intention to deceive or exploit the model’s vulnerabilities. These attacks aim to exploit the inherent weaknesses of machine learning algorithms and their susceptibility to slight variations in input data.
Adversarial attacks take advantage of the fact that machine learning models make predictions based on patterns and features they have learned from the training data. By introducing carefully constructed perturbations to the input data, attackers can trick the model into misclassifying the inputs or making erroneous predictions.
One of the key characteristics of an adversarial attack is that the perturbations introduced to the input data are often imperceptible to the human eye. These subtle modifications can lead to significant changes in the model’s outputs, causing it to make incorrect or unexpected decisions.
Adversarial attacks can have various motivations and objectives. For example, in the context of image classification, an attacker might aim to create adversarial examples that can fool an image recognition model into misclassifying a stop sign as a speed limit sign, potentially leading to dangerous consequences in real-world scenarios.
Adversarial attacks can affect a wide range of machine learning models, including deep neural networks, support vector machines, and decision trees. They are not limited to specific domains and can impact diverse applications such as autonomous vehicles, cybersecurity, and healthcare.
It is important to note that adversarial attacks are not a flaw in machine learning algorithms, but rather a consequence of the underlying complexity and limitations of these models. As researchers and practitioners continue to explore the field of adversarial machine learning, the aim is to develop robust defenses and strategies to mitigate the impact of these attacks and enhance the security and reliability of machine learning systems.
Motivation for Adversarial Attacks
The prevalence of machine learning algorithms in various domains has led to an increased interest in adversarial attacks. Understanding the motivations behind these attacks is crucial for devising effective defense mechanisms and enhancing the security of machine learning systems.
1. Evasion of Detection: Adversarial attacks are often motivated by the desire to evade detection or bypass security measures. By exploiting the vulnerabilities of machine learning models, attackers can manipulate the predictions or classifications made by these models, creating a pathway for unauthorized access or malicious activities.
2. Economic Gain: Adversarial attacks can also be driven by the potential for financial gain. For example, in the context of online advertising, attackers may attempt to manipulate the recommendation algorithms to promote their own products or to suppress the visibility of competitors, thereby influencing consumer behavior and increasing their profits.
3. Social Engineering: Adversarial attacks can be used as a form of social engineering to manipulate public opinion or perception. By creating adversarial examples that can deceive sentiment analysis models or recommendation systems, attackers can influence public sentiment, spread misinformation, or manipulate online reviews and ratings.
4. Data Privacy and Security: Adversarial attacks can also be motivated by the need to assess the robustness and vulnerabilities of machine learning models to ensure the privacy and security of sensitive data. By understanding the weaknesses of these models, organizations can better protect confidential information and develop stronger defenses against potential attacks.
5. Research and Development: Adversarial attacks play a crucial role in driving research and development in the field of machine learning and cybersecurity. By identifying and exploiting vulnerabilities, researchers can gain insights into the limitations of current algorithms and develop more robust models and defenses.
Understanding the motivations behind adversarial attacks is essential for developing effective countermeasures and defenses. By anticipating the potential threats and motivations, organizations and researchers can work towards building more resilient machine learning systems and protecting against potential attacks.
How Adversarial Attacks Work
Adversarial attacks exploit the vulnerabilities inherent in machine learning models by manipulating input data to deceive or mislead the model’s predictions. Understanding the underlying mechanisms of how these attacks work is crucial for developing effective defenses against them.
1. Gradient-Based Attacks: One common approach to adversarial attacks is to use gradient-based methods. These attacks rely on computing the gradients of the model’s loss function with respect to the input data. By iteratively updating the input based on the gradients, attackers can find perturbations that maximize the model’s error, leading to misclassification or incorrect predictions.
2. Fast Gradient Sign Method (FGSM): FGSM is a popular gradient-based attack that introduces adversarial perturbations in a single step. The attacker calculates the gradients of the loss function with respect to the input data and then adds perturbations by taking a step in the direction of the sign of the gradient.
3. Iterative Methods: Iterative methods, such as the Basic Iterative Method (BIM) and Projected Gradient Descent (PGD), perform multiple iterations to refine the adversarial perturbations. These methods can lead to stronger attacks by gradually increasing the magnitude of the perturbations.
4. Transferability: Adversarial attacks often exhibit transferability, meaning that adversarial examples crafted to fool one model can also deceive other models. Transferability occurs due to the shared vulnerabilities and underlying patterns learned by different models during training. This property allows attackers to generate adversarial examples that can bypass multiple models or even models they don’t have access to.
5. Feature Space Attacks: Some adversarial attacks focus on perturbing the feature space instead of directly manipulating the input data. These attacks aim to identify critical features that the model relies on for making decisions and manipulate them to mislead the model. Feature space attacks take advantage of the interpretability of certain models or model-agnostic methods.
6. Defense Evasion: Adversarial attacks can also involve evading defense mechanisms implemented to mitigate such attacks. Attackers may carefully analyze the defense mechanisms employed by the model and adapt their attack strategy accordingly, exploiting weaknesses or blind spots that the defenses may have.
Understanding the inner workings of adversarial attacks is crucial for developing robust defenses. By comprehending the attack methodologies and the vulnerabilities they exploit, researchers and practitioners can work towards enhancing the security and reliability of machine learning models.
Methods of Adversarial Attacks
To successfully execute adversarial attacks, attackers employ various methods and techniques that exploit the vulnerabilities of machine learning models. Understanding these methods is essential for developing effective defenses against adversarial attacks.
1. Gradient-Based Attacks: Gradient-based methods, such as the Fast Gradient Sign Method (FGSM), leverage the gradients of the model’s loss function with respect to the input data. By iteratively updating the input based on these gradients, attackers can introduce perturbations that maximize the model’s error, leading to misclassification or incorrect predictions.
2. Optimization-Based Attacks: Optimization-based attacks involve formulating the generation of adversarial examples as an optimization problem. Attackers define an objective or loss function that guides the search for adversarial perturbations. Techniques like the Basic Iterative Method (BIM) and Projected Gradient Descent (PGD) fall under this category.
3. Transformation-Based Attacks: Transformation-based attacks seek to perturb the input by applying specific transformations or modifications to deceive the machine learning model. For example, attackers may employ methods like image rotation, scaling, or noise addition to manipulate the input data and confuse the model’s predictions.
4. Black-Box Attacks: Black-box attacks refer to scenarios where the attacker has limited knowledge or access to the targeted model. These attacks rely on various techniques, such as query-based attacks or surrogate models, to approximate the behavior of the target model and generate adversarial examples. Transferability plays a crucial role in black-box attacks.
5. Physical Attacks: Physical attacks target machine learning models deployed in the physical world. For example, attackers may use stickers or other physical modifications on objects to deceive computer vision systems or apply strategic alterations to input signals in autonomous systems to manipulate their behavior.
6. Adversarial Training: Adversarial training is a defense strategy that incorporates training on both regular and adversarial examples to improve the model’s robustness against adversarial attacks. By exposing the model to carefully crafted adversarial examples during training, it learns to better generalize and defend against similar attacks.
7. Jacobian-based Saliency Map Attack (JSMA): JSMA is a targeted attack method that aims to change the classification of a specific input sample to a desired target class. It works by incrementally adding perturbations to the input based on the gradients of the target class with respect to the input’s features.
These are just a few of the many methods used in adversarial attacks. The rapidly evolving nature of these attacks necessitates continuous research and development of robust defense mechanisms to safeguard the integrity and security of machine learning models.
Transferability of Adversarial Examples
One intriguing and concerning characteristic of adversarial examples is their transferability. Transferability refers to the phenomena where adversarial examples crafted to deceive one machine learning model can also deceive other models, even those with different architectures or training data.
Researchers have discovered that adversarial examples created for one model can bypass another model that performs a similar task. This property has significant implications as it means an attacker can generate adversarial examples against a surrogate model and exploit them to deceive the actual target model. The transferability of adversarial examples poses challenges and raises questions about the generalizability and robustness of machine learning models.
The transferability of adversarial examples arises from the shared vulnerabilities and decision boundaries learned by different models. While models may use different architectures and training techniques, they often depend on similar underlying patterns and features for making predictions. Adversarial examples exploit these shared characteristics, leading to similar misclassifications or incorrect predictions in multiple models.
Transferability has also been observed across different machine learning domains. Adversarial examples crafted for image classification models have been shown to fool models designed for natural language processing or speech recognition tasks. This cross-domain transferability further accentuates the potential impact of adversarial attacks.
Transferability of adversarial examples raises concerns about the security and trustworthiness of machine learning systems. Adversarial attacks can bypass even well-designed defenses if they rely on the assumption of model-specific vulnerabilities. The ability of an attacker to craft a single adversarial example that deceives multiple models with different security measures or training data highlights the need to develop more robust and generalized defense mechanisms.
Understanding transferability is crucial for designing effective countermeasures against adversarial attacks. Researchers and practitioners are exploring strategies to reduce transferability or develop model-agnostic defenses that can withstand attacks across different machine learning models. By comprehending the transferability and its implications, the aim is to build more resilient and secure machine learning systems.
Defenses Against Adversarial Attacks
As adversarial attacks continue to pose a significant threat to machine learning models, researchers and practitioners are developing various defense strategies and techniques to mitigate their impact and enhance the security of these models.
1. Adversarial Training: Adversarial training is a common defense approach where models are trained on both regular and adversarial examples. By exposing the model to adversarial examples during training, it learns to better generalize and defend against similar attacks. Adversarial training helps in improving the model’s robustness and reducing the effectiveness of adversarial attacks.
2. Defensive Distillation: Defensive distillation involves training a model on artificially generated softened or smoothed logits obtained from a pre-trained model. This technique aims to make the model more robust to adversarial attacks by introducing uncertainty in the model’s predictions, making it harder for attackers to craft effective adversarial examples.
3. Randomization: Randomization techniques add stochasticity or randomness to the model’s decision-making process, making it harder for attackers to find specific vulnerabilities. Techniques like input denoising, input preprocessing, and random resizing can be employed to introduce diversity and make the model more resistant to adversarial attacks.
4. Ensemble Methods: Utilizing ensemble methods, where multiple models are combined to make predictions, can help enhance robustness. Adversarial examples that may fool one model are less likely to deceive all models in the ensemble, thus increasing the model’s overall defense against attacks.
5. Feature Squeezing: Feature squeezing reduces the space of valid adversarial examples by manipulating the input’s feature space. By applying techniques such as quantization or reducing the precision of input features, the model becomes more resilient to small changes that adversarial attacks rely on.
6. Defensive Preprocessing: Defensive preprocessing involves manipulating the input data before it is fed into the model. This includes techniques like input normalization, spatial transformation, or noise injection, which can help detect and filter out potential adversarial perturbations.
7. Certified Defenses: Certified defenses involve mathematically certifying that the model’s predictions lie within a certain range of confidence. These methods provide provable guarantees against adversarial attacks, ensuring that the model’s predictions are robust and trustworthy.
It is important to note that no defense mechanism is entirely foolproof, and the arms race between attackers and defenders continues. Adversarial attacks evolve, and defenses must constantly adapt and improve to keep up with emerging threats. Ongoing research and collaboration within the machine learning community are essential to develop more effective, resilient, and practical defenses against adversarial attacks.
Evaluating and Measuring Adversarial Attacks
Evaluating and measuring the effectiveness and impact of adversarial attacks is crucial for understanding their capabilities and developing robust defense strategies. Researchers employ various metrics and evaluation methods to quantify the success and severity of adversarial attacks.
1. Success Rate: The success rate measures the percentage of adversarial examples that successfully fool the targeted model. It indicates the effectiveness of the attack in terms of the model’s misclassification or incorrect predictions. A high success rate suggests a potent attack, while a low success rate implies the model’s robustness against the attack.
2. Transferability: Transferability measures the ability of adversarial examples generated for one model to deceive other models. A high transferability indicates the universality of the attack, as the adversarial examples can fool models with different architectures or training data. Assessing transferability helps in understanding the generalizability of adversarial attacks and their potential impact.
3. Perturbation Measure: Perturbation measure quantifies the magnitude or size of the modifications made to the input data to generate adversarial examples. Commonly used metrics include L2 norm, L-inf norm, or mean squared error. A larger perturbation measure implies a more noticeable modification, while smaller measures indicate subtle or imperceptible changes.
4. Robustness Evaluation: Robustness evaluation involves subjecting the targeted model to a battery of adversarial attacks and measuring its performance in terms of accuracy and robustness. Evaluating the model’s resilience against various attack methods helps in identifying potential weaknesses, developing stronger defenses, and assessing the overall security of the model.
5. Zero-day Attacks: Zero-day attacks are a type of evaluation that measures the vulnerability of a model to attacks that exploit previously unknown vulnerabilities. These attacks test the robustness of the model in real-world scenarios where attackers utilize novel techniques not seen before. Evaluating the model’s resistance to zero-day attacks helps in assessing its ability to handle emerging threats.
6. Adversarial Detection: Adversarial detection measures the effectiveness of detecting or identifying adversarial examples. It evaluates the ability of detection systems or algorithms to flag inputs that are likely to be adversarial. Metrics like precision, recall, and F1 score are commonly used to assess the performance of adversarial detection mechanisms.
Evaluating and measuring adversarial attacks are ongoing areas of research and development. Existing metrics and evaluation methods help researchers and practitioners understand the capabilities of adversarial attacks, improve defense strategies, and enhance the overall security and reliability of machine learning models.
Real-World Examples of Adversarial Attacks
Adversarial attacks have moved beyond theoretical concepts and have been demonstrated in real-world scenarios, exposing vulnerabilities in various machine learning applications and systems. Here are some notable examples of adversarial attacks:
1. Image Classification: In the field of image classification, researchers have shown that adversarial examples can deceive state-of-the-art deep learning models. For example, adding subtle perturbations to an image of a panda can cause a deep neural network to misclassify it as a gibbon or a given class with high confidence.
2. Autonomous Vehicles: Attacking autonomous vehicles through adversarial examples can have dangerous consequences. Researchers have demonstrated that adding stickers or patterns to road signs can cause autonomous vehicles to misinterpret them or perceive them as completely different signs. This misclassification can lead to potentially hazardous situations on the road.
3. Voice Recognition Systems: Adversarial attacks can also target voice recognition systems. Researchers have shown that adding specific noise or distortion to an audio signal can cause voice recognition systems to misinterpret commands or identify the wrong speaker, potentially leading to unauthorized access or compromised security.
4. Natural Language Processing: Adversarial attacks have been demonstrated in natural language processing tasks, such as sentiment analysis or spam detection. By carefully crafting input text, attackers can manipulate sentiment analysis models to misclassify positive sentiment as negative or deceive spam detection systems into classifying malicious emails as legitimate.
5. Biometric Recognition: Adversarial attacks can also exploit biometric recognition systems. Researchers have shown that subtle alterations to a person’s face or fingerprints can result in biometric systems inaccurately identifying or verifying individuals, potentially compromising security and access control mechanisms.
These real-world examples highlight the potential consequences and impact of adversarial attacks across different domains. The ability to deceive machine learning systems through imperceptible modifications raises concerns about their trustworthiness and reliability in crucial applications.
Understanding these real-world attacks is vital for developing effective defense strategies and mitigating the risks posed by adversarial examples. Continued research and collaboration in this field are essential to safeguard machine learning systems against potential attacks in various practical scenarios.
Future Implications and Research on Adversarial Attacks
The rise of adversarial attacks has sparked significant interest and research in the field of adversarial machine learning. As these attacks continue to evolve, there are several future implications and avenues of research that need to be explored to enhance the security and robustness of machine learning systems.
1. Adversarial Defense Mechanisms: Developing more robust and effective defense mechanisms against adversarial attacks is a crucial area of research. As attackers find new ways to craft adversarial examples, defenders must devise countermeasures that can withstand a wide range of attacks without sacrificing model accuracy or efficiency.
2. Understanding Attack Mechanisms: Gaining a deeper understanding of the underlying mechanisms that make adversarial attacks successful is essential. By uncovering the vulnerabilities and weaknesses of machine learning models, researchers can develop more targeted and effective defense strategies.
3. Generalizability of Defenses: Ensuring the generalizability and transferability of defense mechanisms across different models, architectures, and domains is crucial. Defenses need to be applicable to various machine learning systems and not limited to specific scenarios to provide robust protection against adversarial attacks.
4. Adversarial Robustness Testing: Developing standardized evaluation methodologies and benchmarks to test the adversarial robustness of machine learning models is vital. This includes establishing realistic attack scenarios and metrics to assess the performance and effectiveness of defense mechanisms, promoting fair and comprehensive comparisons between different approaches.
5. Privacy-Preserving Adversarial Learning: Exploring techniques that can defend against adversarial attacks while preserving the privacy of sensitive data is an important area of research. This involves developing models and defenses that are resilient to attacks while minimizing the risk of compromising private or confidential information.
6. Understanding Real-World Implications: Further investigating the real-world implications of adversarial attacks is necessary. This includes exploring the potential impact of these attacks in critical domains such as healthcare, finance, and cybersecurity, and developing specific defense mechanisms tailored to the unique requirements and challenges posed by these applications.
Adversarial attacks pose ongoing challenges to the security and reliability of machine learning models. Continued research and collaboration among researchers and practitioners are keys to staying ahead of attackers, developing robust defenses, and ensuring the trustworthy and effective deployment of machine learning systems in various real-world scenarios.